注意事项 佩雷夫 :本材料是AWS技术传播者Adrian Hornsby撰写的精彩文章的系列,这些文章着眼于简单明确地解释旨在减轻IT系统故障后果的实验的重要性。
“如果您未能准备计划,那么您计划失败。” -本杰明·富兰克林
在本系列文章的
第一部分中 ,我介绍了混沌工程学的概念,并解释了混沌工程学如何在缺陷导致生产崩溃之前帮助发现和修复系统中的缺陷。 它还谈到了混沌工程如何促进组织内部积极的文化变革。
在第一部分的结尾,我答应谈论“将故障引入系统的工具和方法”。 head,我的脑子对此有自己的计划,在本文中,我将尝试回答人们最想提出的混乱工程问题:
首先要打破什么? 好问题! 但是,他似乎并不在意这只熊猫...
 不要惹乱熊猫!简短答案
不要惹乱熊猫!简短答案 :针对请求路径上的关键服务。
一个长而又可理解的答案 :要了解从哪里开始进行混乱实验,请注意以下三个方面:
- 查看故障历史并确定模式;
- 决定关键的依赖 ;
- 使用所谓的。 过度自信效应 。
这很有趣,但是具有同样成功的这一部分可以称为
“自我知识和启蒙之旅”。 在其中,我们将开始使用一些很酷的工具。
1.答案在于过去
如果您还记得的话,我在第一部分中介绍了错误更正(COE)的概念-我们用来分析错误的方法:技术,过程或组织中的失误-了解其原因并防止将来重复。 通常,这应该开始。
“要了解现在,您需要了解过去。” -卡尔·萨根(Karl Sagan)
查看失败的历史记录,将标签放入SOE或postmortem'ah中并进行分类。 确定通常会导致问题的常见模式,并针对每个SOE询问以下问题:
“是否可以预见到这一点,因此可以通过引入故障来防止?”我回想起我职业生涯初期的一次失败。 如果我们进行几个简单的混乱实验,可以很容易地避免这种情况:
在正常情况下,后端实例响应来自负载平衡器(ELB )的运行状况检查。 ELB使用这些检查将请求重定向到运行状况良好的实例。 当事实证明某个实例“不健康”时,ELB停止向其发送请求。 一次,成功的营销活动之后,流量增加,后端开始对健康检查的响应速度比平常慢。 应该说这些健康检查是深层的 ,即检查了依赖状态。
但是,有一阵子一切都井然有序。
然后,已经处于相当紧张的状况,其中一个实例开始执行ETL类别中的非关键性定期cron任务。 高流量和cronjob的结合使CPU利用率几乎提高了100%。 处理器超负荷进一步减慢了运行状况检查的响应速度,以至于ELB认为该实例遇到问题。 如预期的那样,平衡器停止向其分配流量,这进而导致该组中其余实例的负载增加。
突然,所有其他实例也开始无法通过运行状况检查。
启动新实例需要下载和安装软件包,并且花费的时间比自动缩放组中的ELB断开连接所需的时间长得多。 显然,整个过程很快就达到了临界点,申请失败了。
然后我们永远了解以下几点:
- 要在长时间创建新实例时安装软件,最好优先采用不变方法和Golden AMI 。
- 在困难的情况下,应优先执行对健康检查和ELB的响应-您要做的最后一件事是使其余实例的生活变得困难。
- 健康检查的本地缓存(甚至几秒钟)很有帮助。
- 在困难的情况下,请勿运行cron任务和其他非关键过程-为最重要的任务节省资源。
- 自动缩放时,请使用较小的实例。 一组10个小副本要比4个大副本好; 如果发生故障,第一种情况是10%的流量分布在9个点上,第二种情况是25%的流量分布在三个点上。
那么,
是否可以预见到这一点,因此可以通过引入问题来防止这种情况发生?是的 ,有几种方式。
首先,通过使用
stress-ng或
cpuburn工具模拟CPU的高利用率:
❯ stress-ng --matrix 1 -t 60s
 压力
压力其次,使用
wrk和其他类似实用程序重载实例:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
这些实验相对简单,但是它们可以提供很好的思考机会,而不必经历真正失败的压力。
但是,
不要停在那里 。 尝试在测试环境中重现故障,并检查对以下问题的回答:“
是否可以预见到这种情况,因此可以通过引入故障来防止这种情况发生?” ”。 这是一个混沌实验中的微型混沌实验,用于测试假设,但从失败开始。
 这是一个梦想,还是真的发生了?
这是一个梦想,还是真的发生了?因此,研究故障的历史记录,分析
COE ,根据“损坏半径”(或更确切地说,根据受影响的客户数量)对它们进行标记和分类,然后寻找模式。 问问自己,是否可以通过引入问题来预见并避免这种情况。 检查您的答案。
然后切换到范围最大的最常见模式。
2.构建依赖关系图
花点时间考虑一下您的应用程序。 是否有一个清晰的依赖关系图? 您知道发生故障时会对他们产生什么影响吗?
如果您对应用程序的代码不太熟悉或代码太大,则可能很难理解代码的功能及其依赖关系。 了解这些依赖性及其对应用程序和用户的可能影响对于了解从何处开始进行混乱工程至关重要:破坏半径最大的组件将是起点。
识别和记录依赖关系称为“
依赖关系映射” 。 通常,对于具有广泛代码库的应用程序,使用用于分析代码
(代码分析)和检测
(工具)的工具来执行 。 您还可以通过监视网络流量来构建地图。
但是,并不是所有的依赖项都是相同的(这使过程更加复杂)。 有些是
至关重要的 ,有些是
次要的 (至少在理论上是这样,因为崩溃通常是由被视为非关键的依赖关系问题导致的) 。
没有关键的依赖关系,服务将无法正常工作。 非严重的依赖关系“
不应该 ”在发生故障时对服务产生影响。 要处理依赖关系,您需要对应用程序使用的API有清晰的了解。 它可能比听起来复杂得多-至少对于大型应用程序而言。
首先对所有API进行排序。 突出最
重要和最
关键的 。 从代码存储库中获取
依赖项 ,检查
连接日志 ,然后查看
文档 (当然,如果存在的话,否则将会遇到更多问题)。 使用工具进行
性能分析和跟踪 ,过滤外部调用。
您可以使用
netstat程序,它是一个命令行实用程序,用于显示系统上所有网络连接(活动套接字)的列表。 例如,要显示所有当前连接,请键入:
❯ netstat -a | more

在AWS中,您可以使用流日志VPC-一种允许您收集有关去往或来自VPC上网络接口的IP流量的信息的方法。 这样的日志可以帮助完成其他任务,例如,找到某些流量为何未到达实例的答案。
您还可以使用
AWS X-Ray 。 X-Ray使您可以在请求通过应用程序时获得详细的“端”
(端对端)概述,还可以构建应用程序基本组件的映射。 如果需要识别依赖关系,这将非常方便。
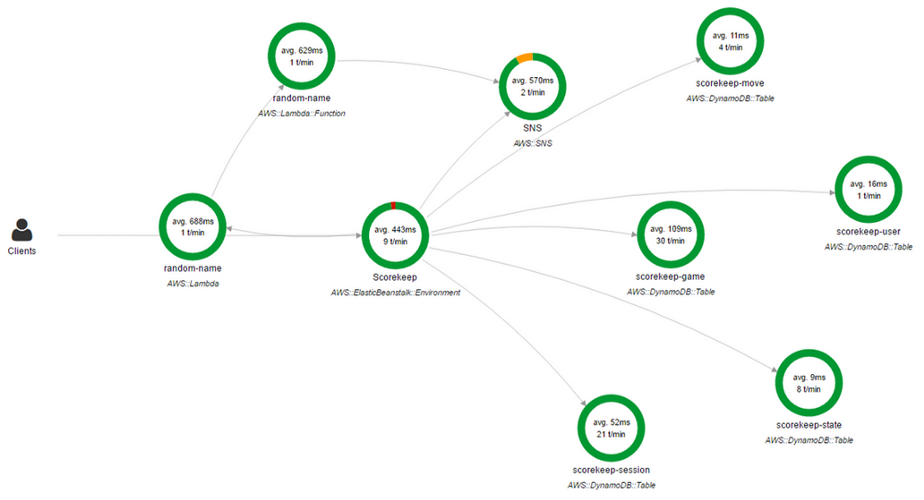 AWS X-Ray控制台
AWS X-Ray控制台网络依赖关系图只是部分解决方案。 是的,它显示了哪个应用程序与哪个应用程序关联,但是还存在其他依赖项。
许多应用程序使用DNS连接到依赖项,而其他应用程序可以使用服务发现机制,甚至可以使用配置文件中的硬编码IP地址(例如,在
/etc/hosts )。
例如,您可以使用
iptables创建
黑洞DNS,然后看看有什么坏处。 为此,请输入以下命令:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
 黑洞DNS
黑洞DNS如果您在
/etc/hosts或其他配置文件中找不到您一无所知的IP地址(是的,不幸的是,这种情况发生了),
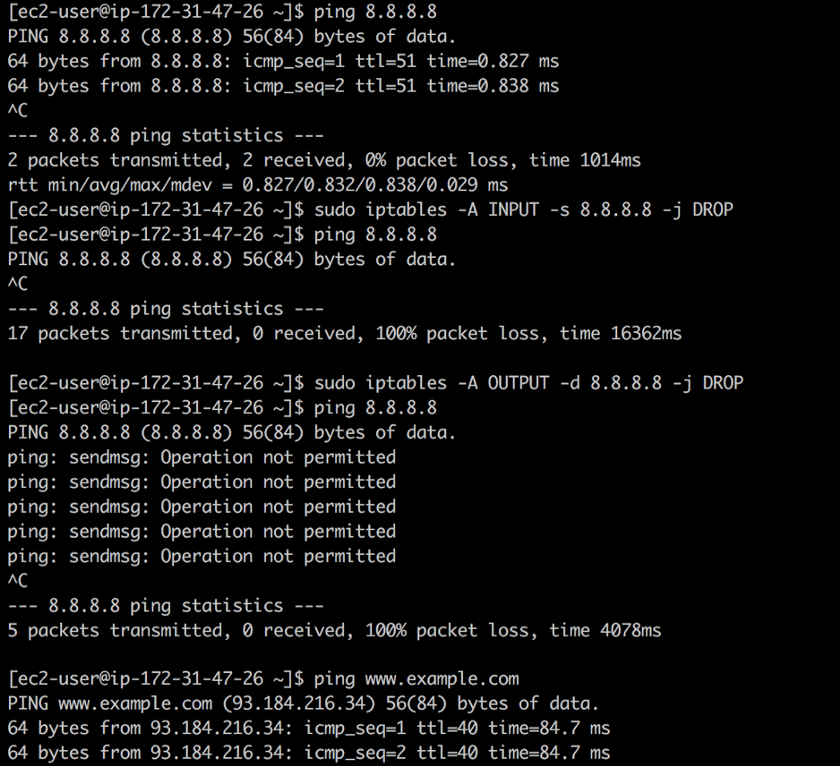
iptables可以再次解决。 假设您找到
8.8.8.8 ,却不知道这是Google的公共DNS服务器的地址。 使用
iptables可以使用以下命令关闭到该地址的传入和传出流量:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
 关闭访问
关闭访问第一条规则会丢弃来自Google的公共DNS的所有数据包:
ping有效,但不会返回数据包。 第二条规则会丢弃所有来自您系统的,朝向Google的公共DNS方向的数据包-响应
ping 操作,我们将
拒绝“操作” 。
注意:在这种情况下,最好使用whois 8.8.8.8 ,但这只是一个例子。由于使用TCP和UDP的所有内容实际上都取决于IP,因此您甚至可以更深入地了解它。 在大多数情况下,IP与ARP绑定。 不要忘记防火墙...
 如果您选择红色药丸,您将留在仙境,我将向您展示兔子洞的深度”
如果您选择红色药丸,您将留在仙境,我将向您展示兔子洞的深度”一种更激进的方法是逐一
关闭汽车,看看发生了什么……成为“混乱的猴子”。 当然,许多生产系统并不是针对这种粗暴的攻击而设计的,但至少可以在测试环境中进行尝试。
建立依赖关系图通常是一项很长的工作。 我最近与一位客户交谈,我花了近两年的时间开发了一种工具,该工具以半自动模式生成了数百个微服务和团队的依赖关系图。
但是,结果非常有趣且有用。 您将学到很多有关系统,其依赖性和操作的知识。 再次,请耐心:旅程本身是至关重要的。
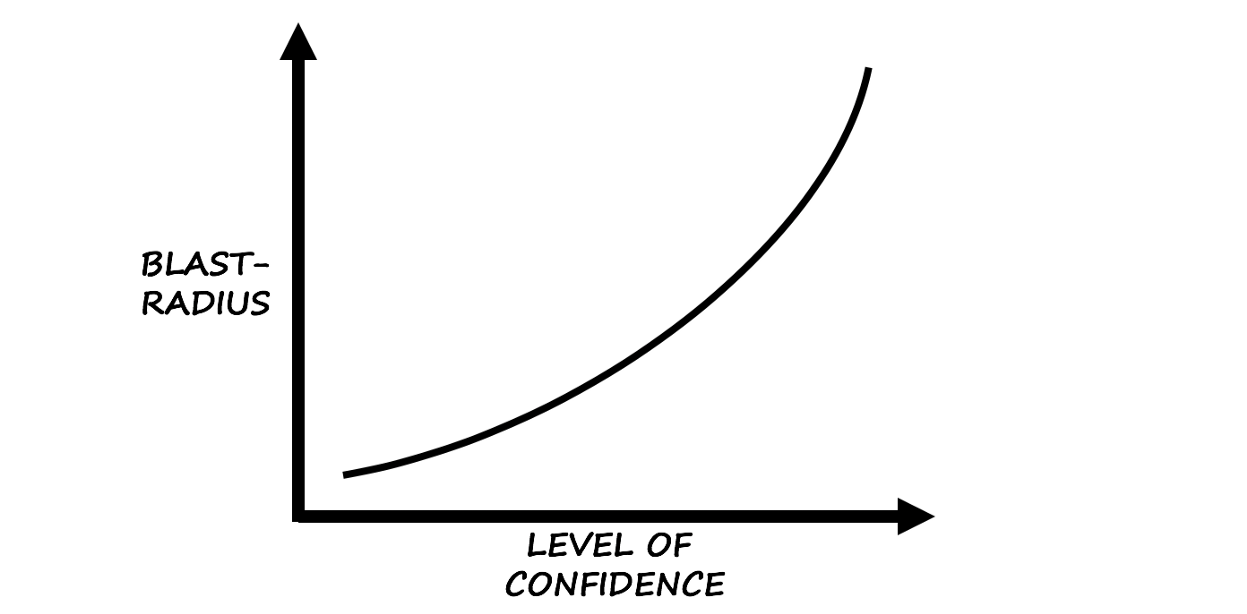
3.当心傲慢
“任何梦想的人都相信这一点。” -妖怪
您听说过
过度自信的
后果吗?
根据Wikipedia的说法,过度自信的后果是“一种认知失真,其中一个人对自己的行为和决策的信心远远高于这些判断的客观准确性,尤其是在信心水平相对较高时。”
 基于本能和经验...
基于本能和经验...根据我自己的经验,我可以说这种失真是从哪里开始进行混沌工程的一个很好的暗示。
当心自信的操作员:
查理:“这件事已经五年没倒了,一切都很好!”
失败:“等等……我会很快!”
由于各种因素影响的自信心造成的偏见是一种阴险甚至危险的事情。 当团队成员将自己的灵魂投入某种技术或花费大量时间进行“修复”时,尤其如此。
总结一下
寻找混沌工程的起点总是会产生比预期更多的结果,而开始四处走动的团队却忽视了(混沌)
工程更全球化和更有趣的本质-
科学方法的创造性应用以及设计,开发的
经验证据 ,(软件)系统的运行,维护和改进。
至此,第二部分结束。 请发表评论,分享意见或只是鼓掌欢迎。
在下一部分中,我将真正研究引入系统故障的工具和技术。 直到-再见! 更新 (12月19日):
第三部分的
翻译已可用。
译者的PS
另请参阅我们的博客: