通常,根据老年人的面部识别和身份识别结果对于长者来说就像是青少年时期的性爱-每个人都谈论他很多,却很少实践。 很明显,Facebook / VK在从友好聚会中下载照片后,建议对照片中的人物进行标记,我们对此并不感到惊讶,但是在这里,我们直观地知道,社交网络可以以人际关系图的形式提供良好的帮助。 如果没有这样的图表? 但是,让我们按顺序开始。

最初,与我们的脸部识别和“朋友/敌人”的识别完全是出于家庭的需要-上瘾者进入了同事的门口,并不断从安装的摄像机监视图片,甚至在邻居和陌生人不愿去的地方拆解不行
因此,仅用一周的时间,便在膝盖上组装了一个原型,其中包括IP摄像机,单板设备,运动传感器和face_recognition Python识别库。 由于python库位于单板的,功能强大的硬件上……让我们谨慎地说,不是很快,所以我们决定按以下方式构建处理过程:
- 运动传感器确定委托给它的空间区域中是否存在运动,并发出信号通知其存在;
- 基于gstreamer的书面服务,该服务不断接收来自IP摄像机的流,在检测之前5秒和10秒后将其截断,并将其提供给识别库进行分析;
- 她依次观看视频,在那儿找到面孔,将它们与已知样本进行比较,如果发现未知样本,则将视频提供给Telegram频道,之后应该将其控制在同一位置以立即切断误报-例如,当邻居转向样品反面的相机。
整个过程由我们挚爱的Erlang粘合在一起,在对同事的测试过程中,他证明了自己的最低工作能力。
但是,组装后的模型并没有在现实生活中找到应用-并不是因为它的技术缺陷-毫无疑问-正如经验所表明的那样,在温室办公室条件下膝盖收集在野外破裂的趋势非常差,并且在向客户演示时,并且由于组织上的原因,入口的居民拒绝了任何视频监控的大部分。
该项目搁置了货架,并定期用棍子戳戳以示销售期间的示范以及渴望在个人家庭中轮回的渴望。
自从我们针对同一主题进行更具体,更商业化的项目以来,一切都发生了变化。 由于不可能直接从问题陈述中使用运动传感器在其中切角,因此我不得不更深入地研究直接在溪流中搜索和识别三个头部(好的,两个半,如果算上我的脸)的细微差别。 然后发生了一个启示。
麻烦的是,在这个问题上的大多数发现都是纯粹的学术素描,主题是“我必须在杂志上写一篇关于时尚话题的文章,并且要发表论文才行。” 我并没有降低科学家的功绩-在论文中我发现有很多有用和有趣的东西,但是,可惜,我不得不承认,他们在Github上发布的代码的可重复性令人望而却步,或者看起来像是一次可疑的工作,最终浪费了时间。
神经网络和机器学习的众多框架通常难以提升-面部识别对于他们来说是一项单独的狭窄任务,对他们解决的各种问题不感兴趣。 换句话说,举一个现成的示例并在目标硬件上运行它,只是为了检查它如何工作以及它是否工作,是行不通的。 那不是一个例子,然后需要获得它,这建议从严格定义的OS的某些版本的某些库的汇编中进行一项艰巨的任务。 即 随身携带和飞行-像我们前面提到的手工艺品所使用的上述face_recognition一样,实际上是碎屑。
大公司一如既往地拯救了我们。 长期以来,英特尔和英伟达都感到这类任务的增长势头和商业吸引力,但是作为设备的供应商,他们首先分发了免费解决特定应用问题的框架。
我们的项目很可能不是研究性的,而是实验性的,因此我们没有分析和比较各个供应商的解决方案,只是采取了第一个方案,目的是收集现成的原型并在战斗中进行测试,同时获得最快的响应速度。 因此,选择很快就落在了
Intel OpenVINO上 -一个将机器学习实际应用到应用任务中的库。
首先,我们将一个支架放在一起,该支架通常是一组网吧,上面装有英特尔酷睿i3处理器和市场上来自中国供应商的IP摄像机。 摄像头直接连接到网顶,并向其提供了具有不太大的FPS的RTSP流,这是基于这样的假设,即人们不会像在比赛中那样在摄像头前奔跑。 一帧(搜索和识别脸部)的处理速度在几十到几百毫秒的范围内波动,这足以为使用现有样本的人嵌入搜索机制。 此外,我们还有一个备份计划-英特尔拥有一个特殊的协处理器,可加快
Neural Compute Stick 2神经网络的计算速度,如果没有通用处理器,则可以使用该算法。 但是-到目前为止,什么都没有发生。
在完成组装并验证了基本示例的功能之后(逐步且非常详细的示例指南),英特尔SDK的一项独特功能-我们开始构建软件。
我们面临的主要任务是在相机的视野中寻找一个人,识别其身份并及时通知其存在。 因此,除了识别人脸并将其与模式进行比较(当时的操作方式引起的问题不少于其他所有问题),我们还需要提供界面计划的辅助功能。 即,我们必须从同一台摄像机接收带有必要人员面部的镜框,以便他们进行后续识别。 为什么在同一台相机上,我认为这也很明显-相机在物体上的安装点和镜头光学器件会引起某些失真,这可能会影响识别质量,我们使用的源数据源与跟踪工具不同。
即 除了流处理程序本身之外,我们至少还需要一个视频档案和一个视频文件分析器,这些视频分析器和视频文件分析器会将所有检测到的面部与录像隔离开,并将最合适的面部保存为参考面部。
与往常一样,我们将熟悉的Erlang和PostgreSQL用作ffmpeg,OpenVINO上的应用程序和Telegram Bot API的警报之间的粘合剂。 另外,我们需要一个Web UI来提供管理该综合体的最低限度的程序集,而我们的同事前端已将其上传到VueJS。
工作逻辑如下:
- ffmpeg在控制平面(在Erlang中)的控制下,以五分钟的时间段将从摄像机到视频的流写入,一个单独的过程可确保记录存储在严格指定的卷中,并在达到此阈值时清除最旧的记录;
- 通过Web UI,您可以按时间顺序查看任何记录,这些记录按时间顺序排列,尽管并非毫无困难,但您可以隔离所需的片段并将其发送以进行处理;
- 处理过程包括分析视频并提取带有检测到的面部的帧,这只是基于OpenVINO的软件(我必须说,在这里我们设法将角度切开了一些-用于分析流和分析文件的软件几乎完全相同,这就是为什么其中大部分用于共享库,而实用程序本身仅在处理链上有所不同(例如模块化gstreamer)。 处理过程在视频上进行,使用经过特殊训练的神经网络隔离找到的面孔。 包含面部的帧的结果片段落入另一个神经网络,该神经网络形成一个256个元素的向量,实际上是人脸参考点的坐标。 该矢量,检测到的帧以及找到的脸部矩形的坐标存储在数据库中;
- 此外,在处理完成之后,操作员打开各种绘制的框,对其编号感到震惊,然后继续搜索目标人物。 所选样本可以添加到现有人员或创建一个新人员。 任务处理完成后,分析结果将被删除,但已存储的矢量映射到可观测对象的记录除外;
- 因此,我们可以随时查看帧和检测矢量,然后进行编辑,删除不成功的样本;
- 与后台检测周期平行,流分析服务始终可以工作,其作用相同,但是使用来自摄像机的流。 他从观察到的流中选择人脸,并将其与数据库中的样本进行比较,这是基于一个简单的假设,即一个人的向量将比所有其他向量更靠近彼此。 向量之间的距离是成对计算的,当达到阈值时,将检测记录和帧放入数据库中。 另外,在不久的将来会将一个人添加到停止列表中,这样可以避免有关该人的多个通知;
- 控制平面会定期检查检测日志,并在出现新条目时通过附带照片的消息进行通知,并通过机器人将脸部突出显示给根据设置允许的人。
看起来像这样:
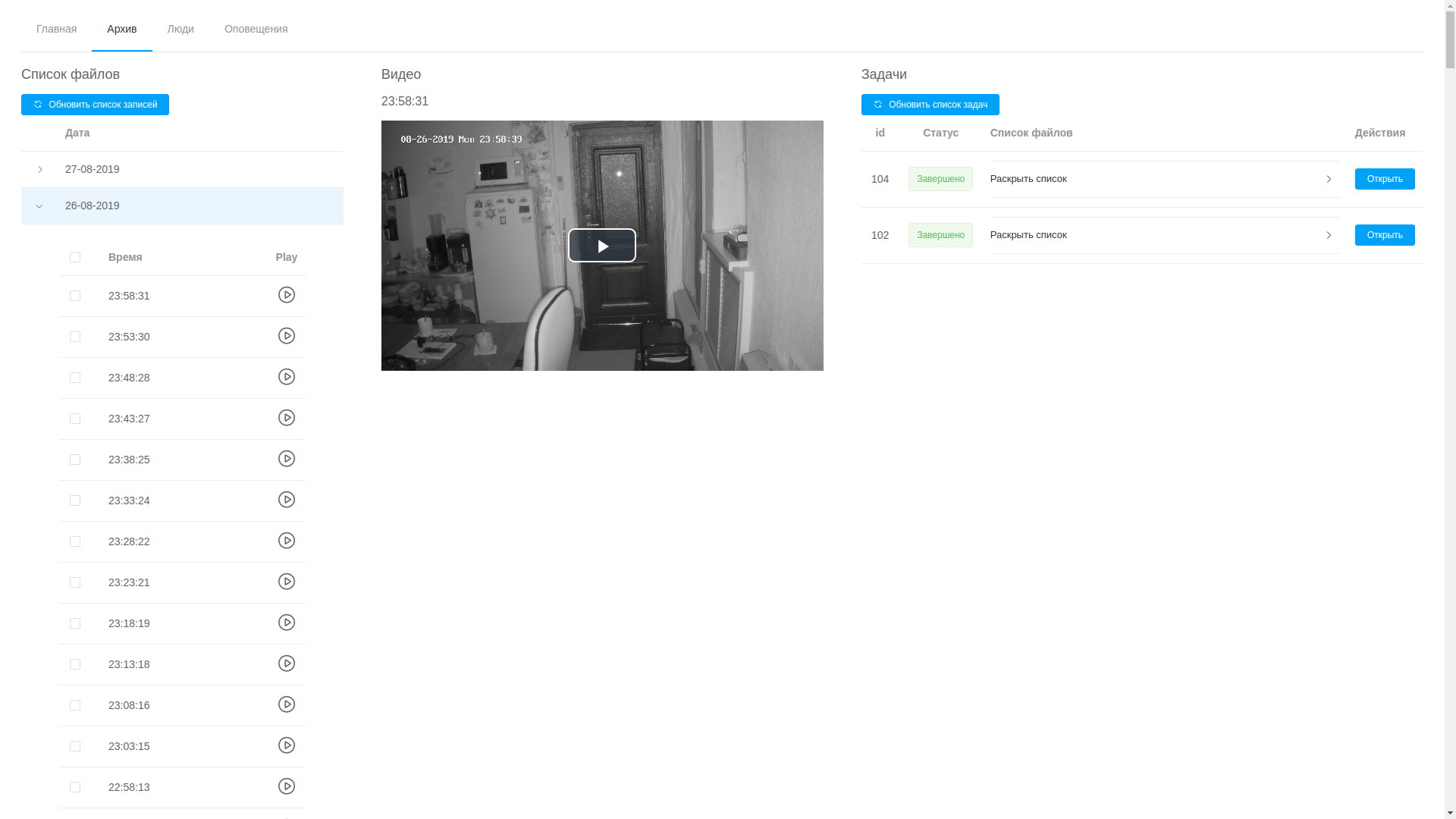 查看档案
查看档案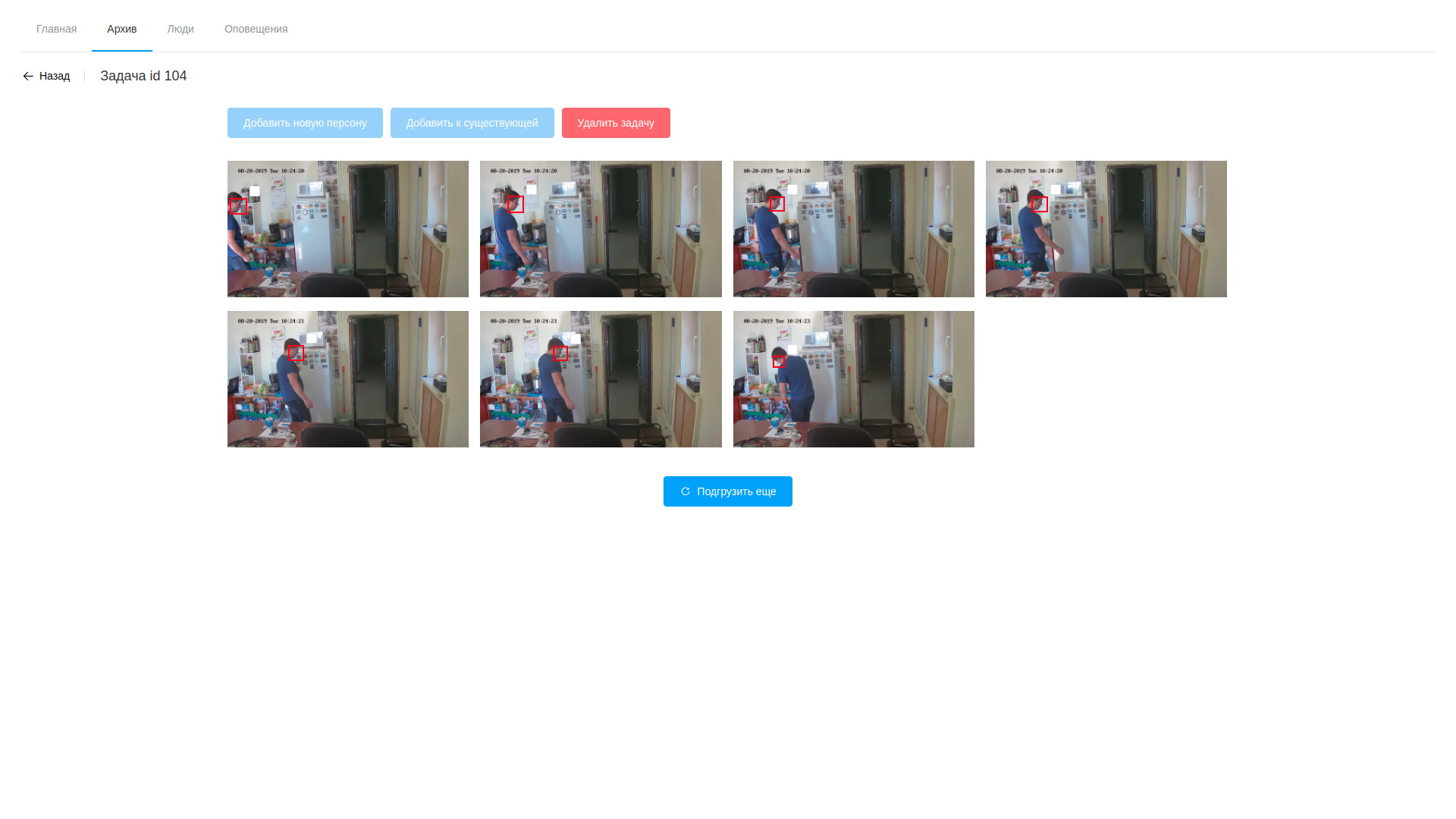 视频分析结果
视频分析结果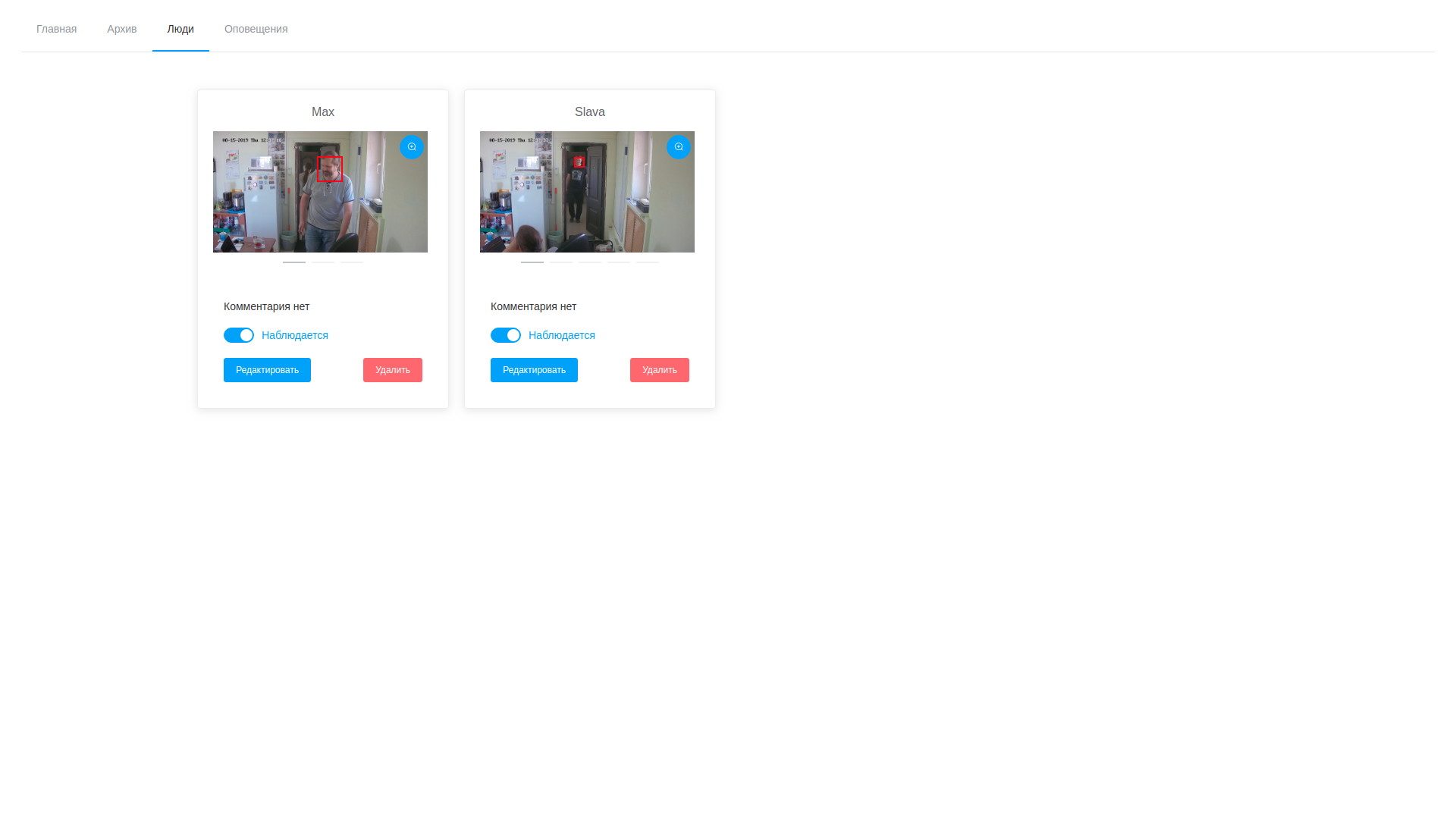 观察人物列表
观察人物列表在生产率和减少反应时间方面,所得解决方案在很多方面都存在争议,有时甚至不是最佳的。 但是,我重复一遍,我们的目标不是立即获得有效的系统,而只是走这条路线并填充最大数量的圆锥体,确定狭窄的路径和潜在的非显而易见的问题。
组装后的系统在温室办公室条件下测试了一周。 在此期间,注意以下几点:
- 识别质量与原始样本的质量之间存在明显的依赖关系。 如果被观察者过快地通过了观察区域,那么他很有可能不会留下用于采样的数据并且不会被识别。 但是,我认为这是对系统进行微调的问题,包括照明和视频流参数。
- 由于系统可以识别脸部元素(眼睛,鼻子,嘴巴,眉毛等),因此很容易通过在脸部和相机之间放置视觉障碍物(头发,墨镜,戴头巾等)来欺骗人,很有可能会发现,但是由于检测向量和样本之间的巨大差异,无法与样本进行比较;
- 普通眼镜的影响不会太大-戴眼镜的人有积极的反应,戴眼镜进行测试的人有假阴性的反应。
- 如果胡须在原始样本上,然后又消失了,则减少手术次数(这些行的作者将胡须修剪至2毫米,并且胡须减少了一半);
- 假阳性也发生了,这是一个进一步浸入该问题的数学的机会,并且可能是对向量的部分对应的问题的解决方案以及用于计算它们之间的距离的最佳方法。 但是,现场测试应在这方面揭示更多问题。
会发生什么? 检查战斗中的系统,优化检测处理周期,简化在视频档案中搜索事件的过程,向分析中添加更多数据(年龄,性别,情感)以及还有100,500个尚待完成的小型而非常规任务。 但是,我们已经迈出了千步之路的第一步。 如果有人分享他们在解决此类问题上的经验或在此问题上提供了有趣的链接-我将不胜感激。