
在SRE / DevOps工程师的环境中,有一天客户(或监控系统)出现并说“一切都丢失了”,您不会感到惊讶:该站点无法正常工作,付款无法通过,生活正在衰败...无论在这种情况下我想如何提供帮助如果没有简单易懂的工具,很难做到这一点。 通常,问题隐藏在应用程序本身的代码中-您只需要对其本地化即可。
在悲伤和喜悦中...
碰巧的是,我们长期以来一直非常喜欢New Relic。 它一直是并且仍然是监视应用程序性能的出色工具,并且还允许您(使用代理)对微服务体系结构进行检测等等。 而且,即使不是因为服务定价政策的变化,一切也可能很棒:
自2013年以来,其
成本已增长了3倍以上 。 另外,自去年以来,获得试用帐户需要与个人经理进行沟通,这使得向潜在客户展示产品变得困难。
通常的情况:不需要“持续进行”新遗物,只有在问题开始时才记住它。 但是您仍然需要定期付款(每台服务器每月140美元),并且在可自动扩展的云基础架构中,费用相当大。 尽管可以“按需付费”,但是要启用New Relic,您将需要重新启动应用程序,这可能会导致丢失一切开始的问题情况。 不久前,New Relic推出了一个新的资费计划
-Essentials ,乍一看似乎是Professional的合理替代方案...但经过仔细研究,结果发现某些重要功能缺失了(特别是它没有
关键交易 ,
跨应用程序跟踪 ,
分布式跟踪 ) 。
结果,我们考虑寻找一种更便宜的替代品,而我们的选择落在了Datadog和Atatus这两个服务上。 为什么要精确地放在他们身上?
关于竞争对手
我必须马上说,市场上还有其他解决方案。 我们甚至考虑了开放源代码选项,但并不是每个客户都有免费的能力来托管自托管解决方案...-此外,它们将需要额外的维护。 我们选择的一对夫妇最接近
我们的需求 :
- 内置和开发的对PHP应用程序的支持(我们的客户堆栈非常多样化,但是在寻找New Relic的替代方案方面,它无疑是领先者);
- 负担得起的费用(每台主机每月少于100美元);
- 自动仪表
- Kubernetes集成
- 与New Relic界面的相似性是一个明显的优势(因为我们的工程师已经习惯了)。
因此,在初始选择阶段,我们消除了其他几种流行的解决方案,尤其是:
- Tideways,AppDynamics和Dynatrace-价格;
- Stackify-在俄罗斯联邦被阻止,显示的数据太少。
下一篇文章的结构使得将简要介绍所考虑的解决方案,之后,我将讨论我们与New Relic的典型交互以及在其他服务中执行类似操作的经验/印象。
介绍选定的竞争对手

大概每个人都听说过
新遗物吗? 该服务于10年前的2008年开始发展。 自2012年以来,我们一直在积极使用它,并且在使用PHP,Ruby和Python进行大量应用程序集成时没有遇到集成问题,我们还具有与C#和Go集成的经验。 该服务的作者提供了用于监视应用程序,基础结构,跟踪微服务基础结构,已创建用于用户设备的便捷应用程序等解决方案。
但是,New Relic代理适用于专有协议,不具有OpenTracing支持。 高级检测要求专门针对New Relic进行编辑。 最后,到目前为止,对Kubernetes的支持还处于试验阶段。
 Datadog
Datadog于2010年开始开发,就其在Kubernetes环境中的使用而言,看起来比New Relic更有趣。 特别是,它支持与NGINX Ingress,日志收集,statsd和OpenTracing协议的集成,这使您可以从连接到工作结束的那一刻开始跟踪用户请求,以及查找该请求的日志(在Web服务器端和网络端)消费者)。
使用Datadog时,我们会遇到这样的事实,即它有时会错误地构建微服务映射,并存在一些技术缺陷。 例如,他错误地确定了服务的类型(他将Django用于缓存服务),并使用流行的Predis库在PHP应用程序中引起了第500个错误。
 Atatus
Atatus是最年轻的乐器。 服务于2014年推出。 它的营销预算显然不如上市竞争对手,提及的可能性要小得多。 但是,该工具本身与New Relic非常相似,不仅在功能(APM,浏览器监视等)上,而且在外观上也是如此。
一个重大缺点是仅支持Node.js和PHP。 另一方面,它的实现比Datadog更好。 与后者不同,Atatus不需要应用程序修改或设置代码中的其他标签。
我们如何与New Relic合作
现在让我们弄清楚我们通常如何使用New Relic。 假设我们有一个需要解决的问题:
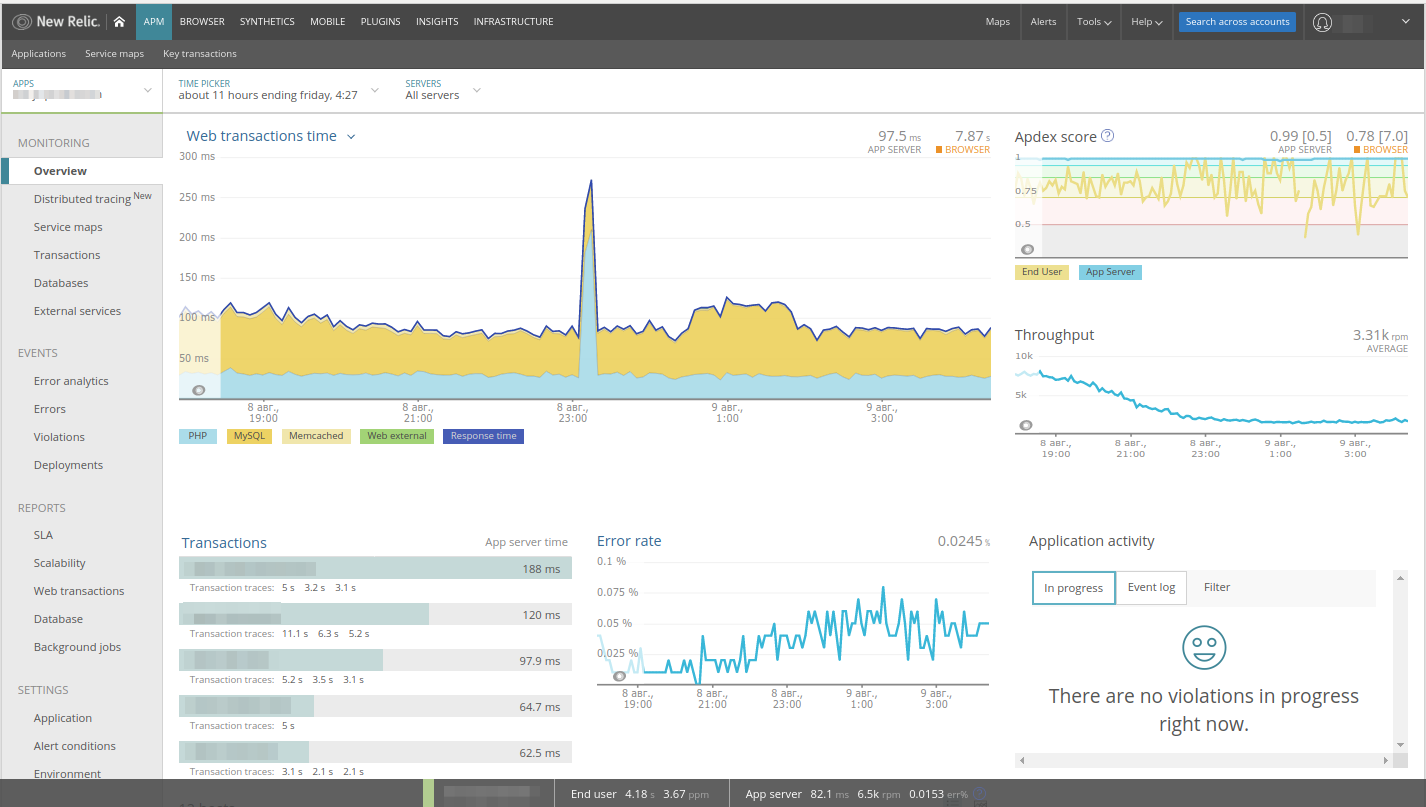
在图表上很容易注意到
激增 -我们对其进行了分析。 在New Relic中,立即为Web应用程序选择了Web事务,性能图中指示了所有组件,其中有错误率,请求率面板……最重要的是,直接从这些面板中可以在应用程序的不同部分之间移动(例如,单击MySQL,到数据库部分)。
由于在此示例中,我们看到
PHP活动激增,因此请单击此图表并自动转到
Transactions :
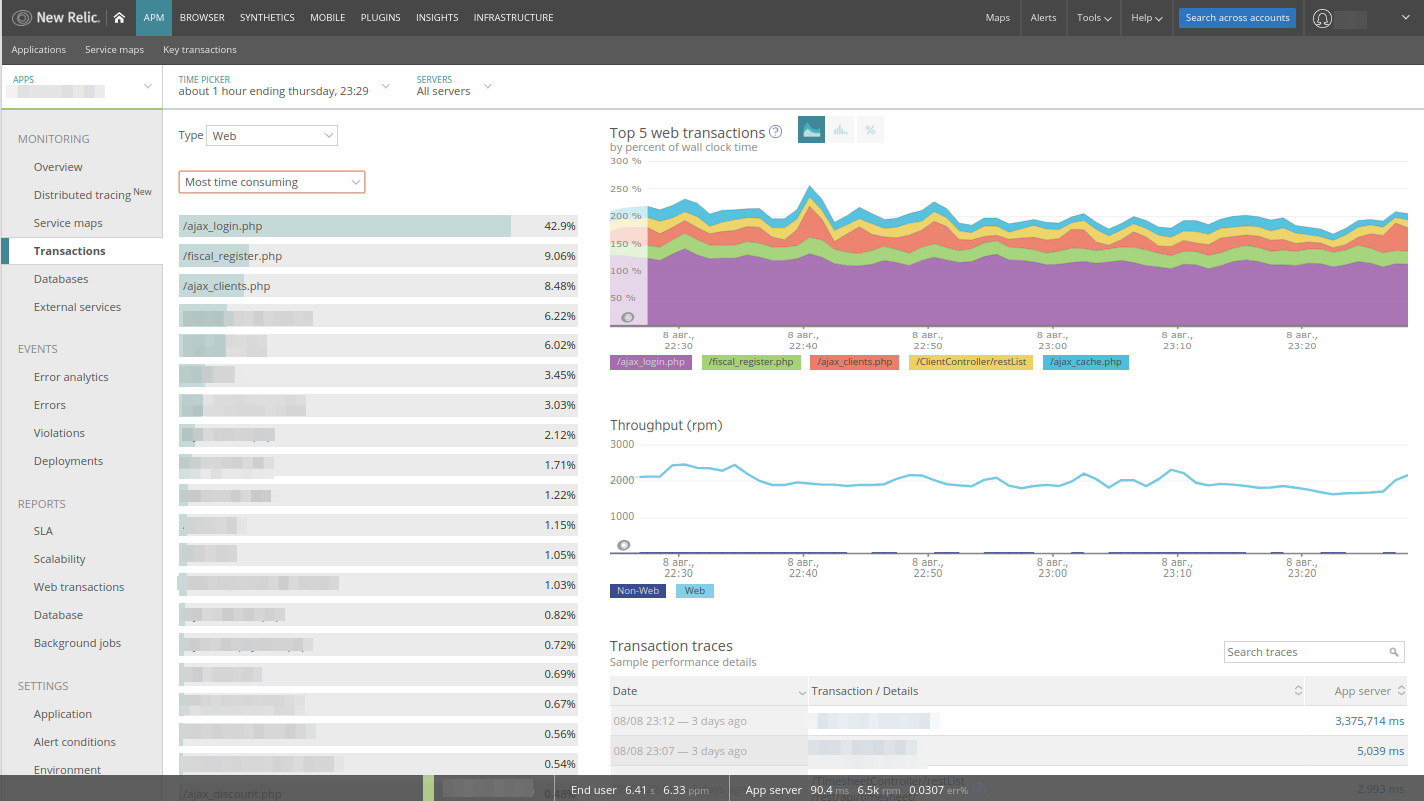
事务列表(本质上是MVC模型的控制器)已经按“
最耗时”进行了排序,这非常方便:我们立即看到应用程序的工作。 这是由New Relic自动收集的长查询的示例。 切换排序很容易找到:
- 负载最大的应用程序控制器;
- 最常要求的控制器
- 最慢的控制器。
此外,您可以扩展每个事务,并在执行代码时查看应用程序在做什么:
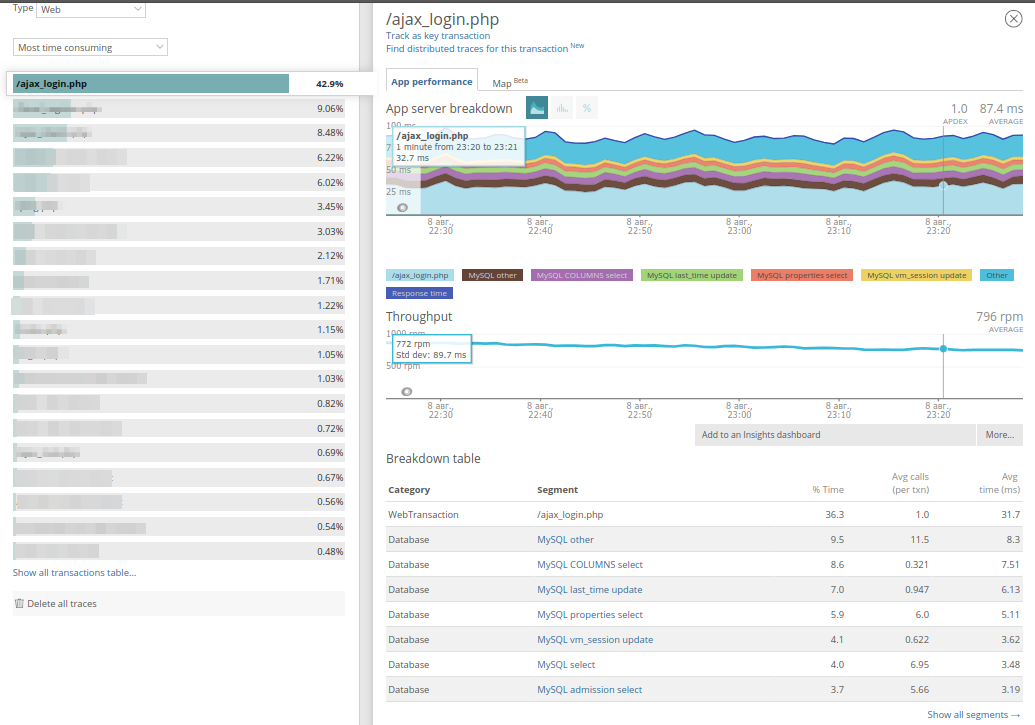
最后,长查询跟踪的示例(计算时间超过2秒)保存在应用程序中。 这是长时间交易的面板:

可以看出,两个方法花费大量时间,执行请求时还显示了它的URI和域。 通常,这有助于在日志中查找查询。 转到
Trace详细信息 ,您可以看到从哪里调用这些方法:
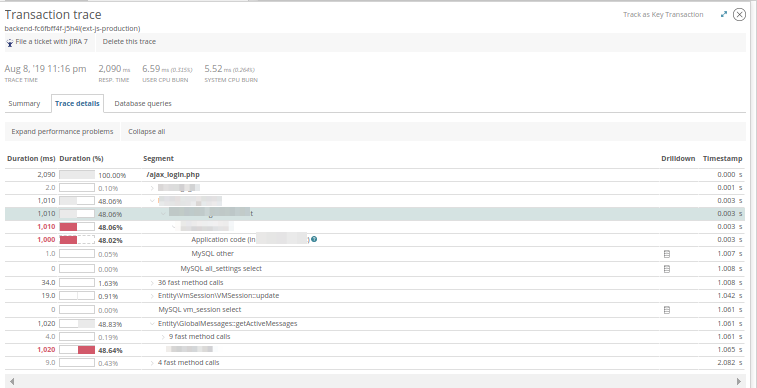
在
数据库查询中 -评估在应用程序执行时执行的数据库查询:

有了这些知识,我们就可以评估应用程序运行缓慢的原因,并与开发人员一起制定解决问题的策略。 实际上,New Relic并不总是能提供清晰的画面,但是它有助于选择调查媒介:
- 漫长的
PDO::Construct使我们进入pgpoll的奇怪功能; - 时间不稳定
Memcache::Get建议的虚拟机错误配置; - 处理模板的时间明显增加,导致嵌套循环,并检查了对象存储中是否存在500个化身;
- 等等...
也可能发生的是,与在主屏幕上执行代码不同的是,与外部数据存储相关的东西增加了-不管是什么:Redis或PostgreSQL-所有这些都隐藏在“
数据库”选项卡中。

您可以选择一个特定的研究基础并对查询进行排序-类似于在“事务”中如何进行。 通过转到“请求”选项卡,您可以查看在每个应用程序控制器中找到了多少请求,以及评估了该请求被调用的频率。 这很方便:
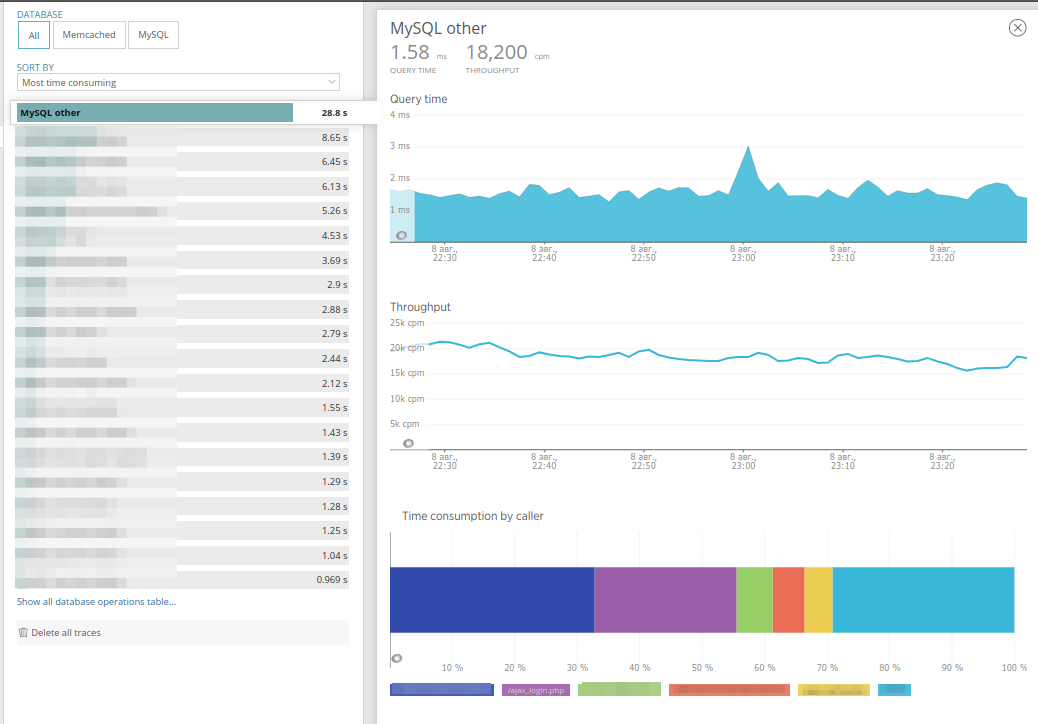
“
外部服务”选项卡包含类似的数据,该数据隐藏了对外部HTTP服务的请求,例如访问对象存储,将事件发送到哨兵等。 根据其内容,选项卡与数据库完全相似:

竞争对手:机会和印象
现在最有趣的是将New Relic的功能与竞争对手提供的功能进行比较。 不幸的是,我们无法在生产中运行的一个应用程序的相同版本上测试所有这三个工具。 不过,我们尝试比较最相同的情况/配置。
1.数据狗
Datadog向我们提供了一个带有服务墙的小组:
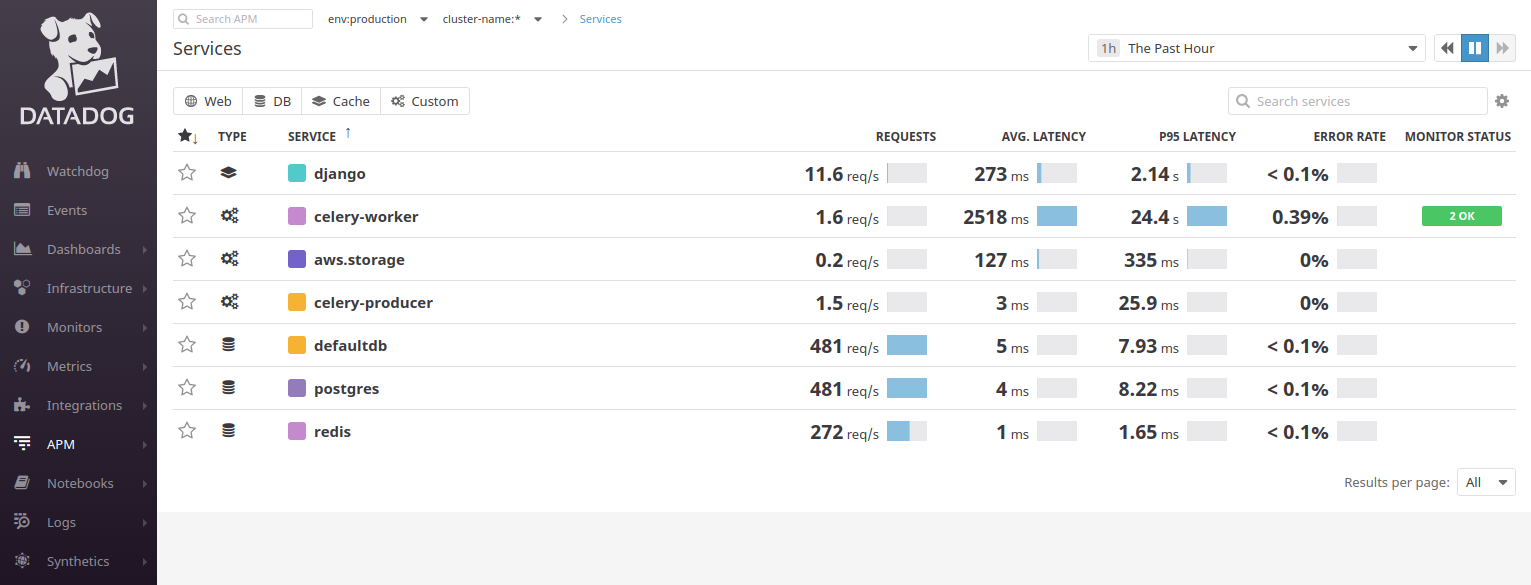
他正在尝试将应用程序分解为组件/微服务,因此在示例Django应用程序中,我们看到PostgreSQL的2个连接(
defaultdb和
postgres )以及Celery,Redis。 使用Datadog要求您至少了解MVC的原理:您需要了解用户请求的来源。 通常
,服务图可以帮助您:

顺便说一下,New Relic中有一些类似的东西:
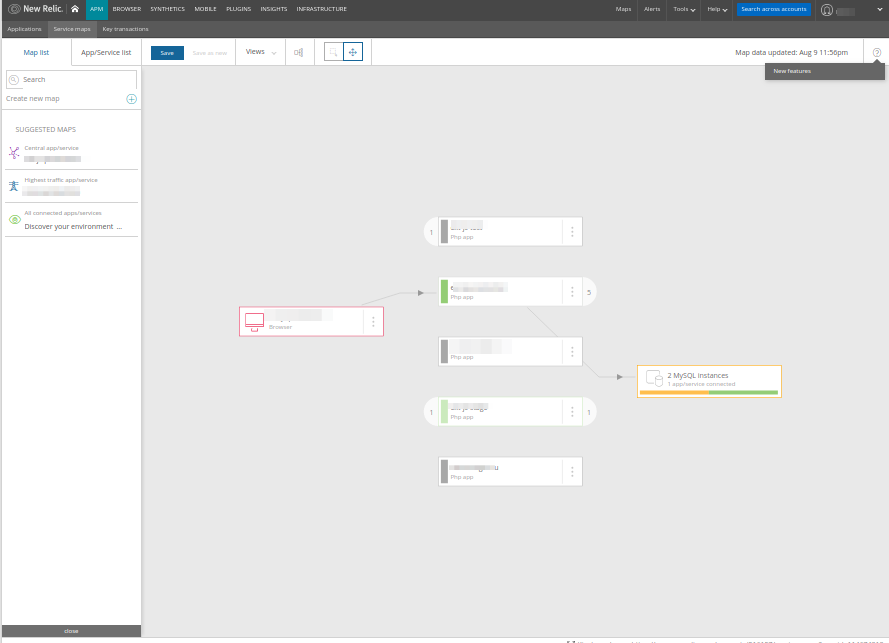
……此外,我认为它们的地图更简单易懂:它不显示一个应用程序的组件(如Datadog那样,它不必显示不必要的详细信息),而仅显示特定的服务或微服务。
返回Datadog:从服务图上可以清楚地看到用户请求来了Django。 让我们转到Django服务,最后看看我们的期望:
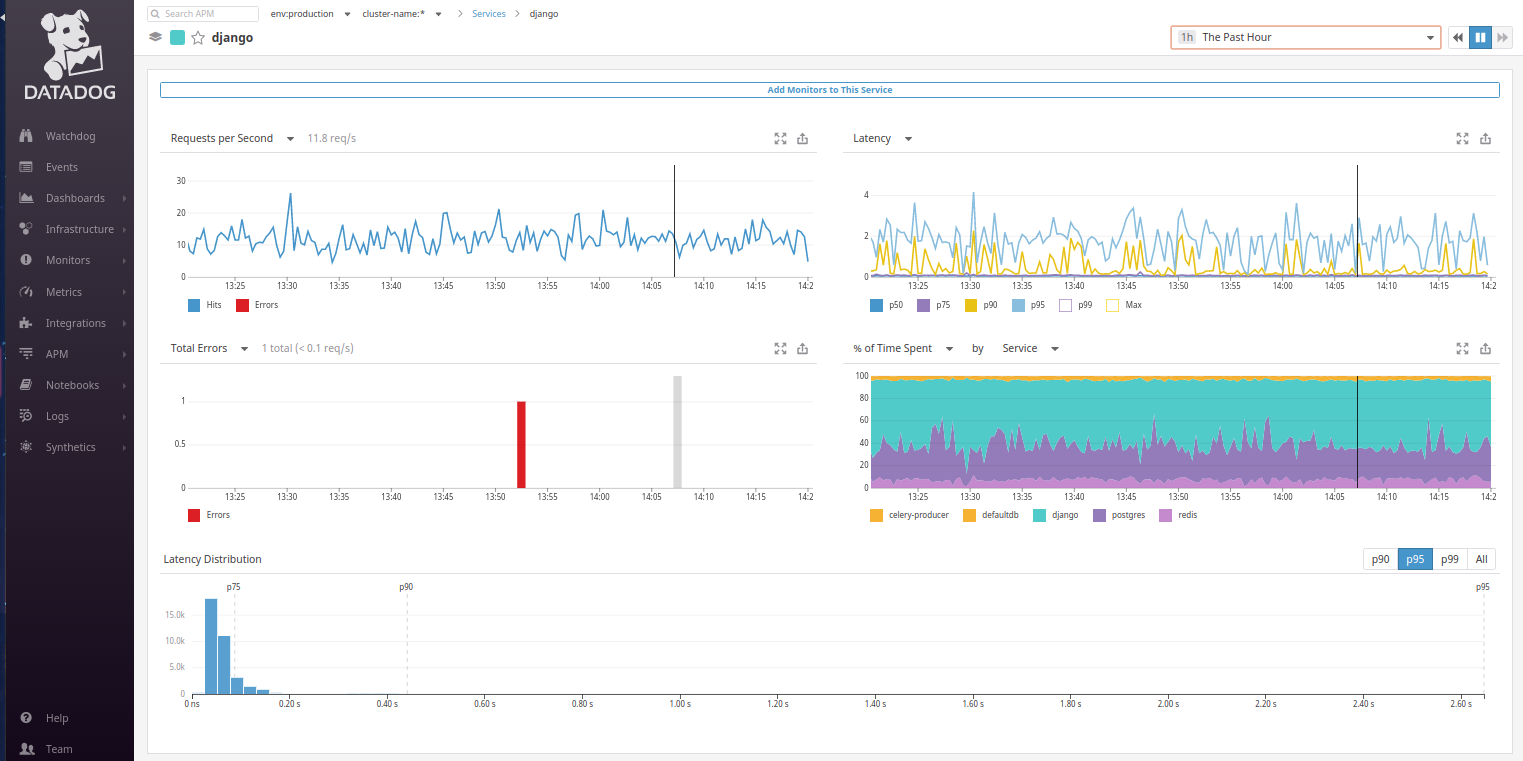
不幸的是,默认情况下,没有
Web交易时间表类似于我们在New Relic主面板上看到的
时间表 。 但是,可以配置它代替
“花费的时间百分比”图。 只需
按类型将其切换为
每个请求的平均时间 ...,现在熟悉的图表就会向我们显示!
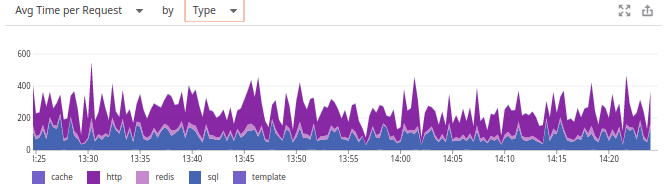
为什么Datadog选择不同的时间表对我们来说是一个谜。 同样令人沮丧的是,该系统不记得用户的选择(与两个竞争对手不同),因此只保存了自定义面板的创建。
但是,我对Datadog中有机会从这些图形切换到相关服务器的指标,阅读日志并评估Web服务器处理程序(Gunicorn)的负载感到高兴。 一切几乎都与New Relic中的相同...甚至更多(日志)!
图表下方是与New Relic完全相似的交易:
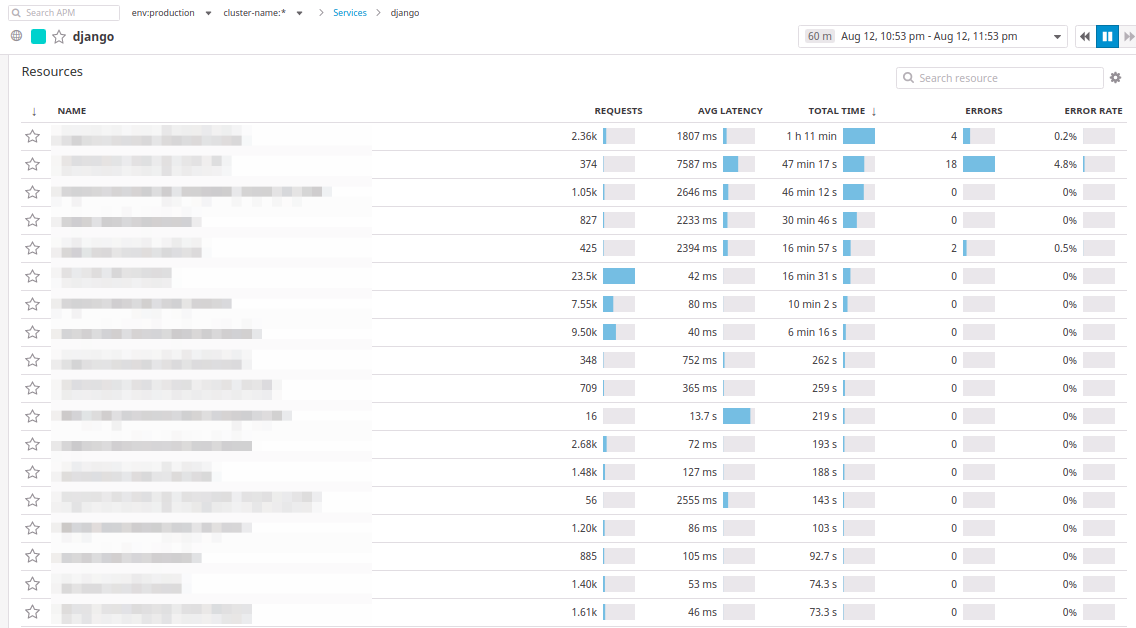
在Datadog中,事务称为
资源 。 您可以按请求数,平均响应时间,选定时间段内的最大经过时间对控制器进行排序。
您可以扩展资源并查看我们在New Relic中已经观察到的所有内容:
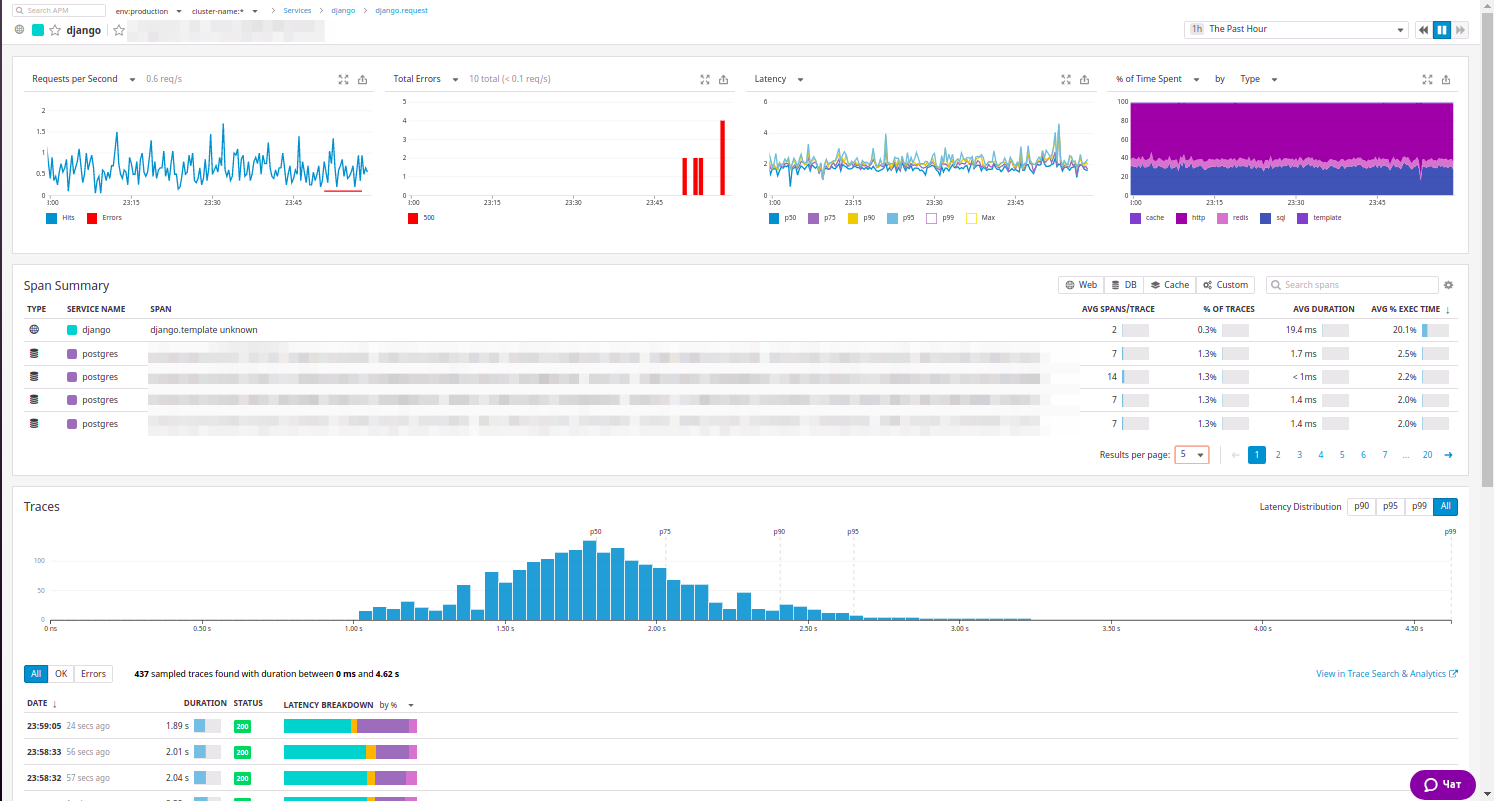
这里有关于资源的统计信息,内部调用的一般列表以及可以通过响应代码进行排序的请求示例……顺便说一下,我们的工程师真的很喜欢这种排序。
可以扩展和探究Datadog中的任何示例资源:

给出了查询参数,每个组件的经过时间的摘要图以及在其中可以看到调用顺序的瀑布图。 此外,还可以切换到瀑布图的树视图:

最有趣的是查看在其上执行请求的主机的负载,并查看请求日志。
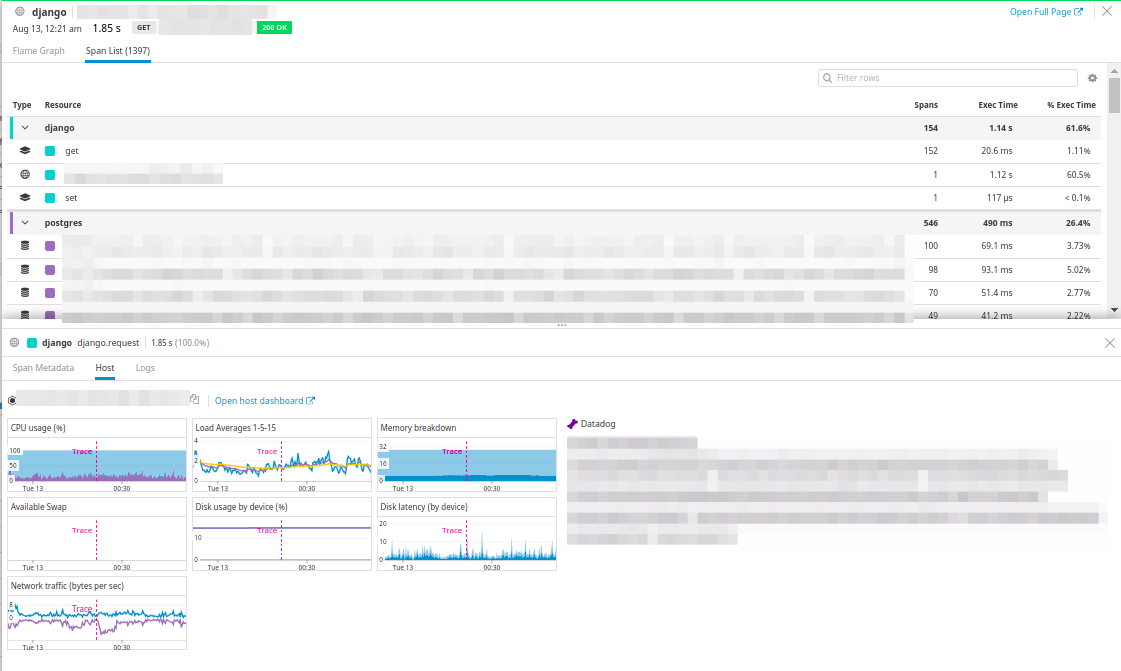
很棒的整合!
您可能想知道“
数据库”和“
外部服务”选项卡的位置,如“ New Relic”中那样。 它们不在这里:由于Datadog将应用程序解析为组件,因此PostgreSQL将被视为
独立的服务 ,而不是外部服务,值得寻找
aws.storage (对于应用程序可以访问的所有其他外部服务,它都是相同的)。

这是
postgres的示例:
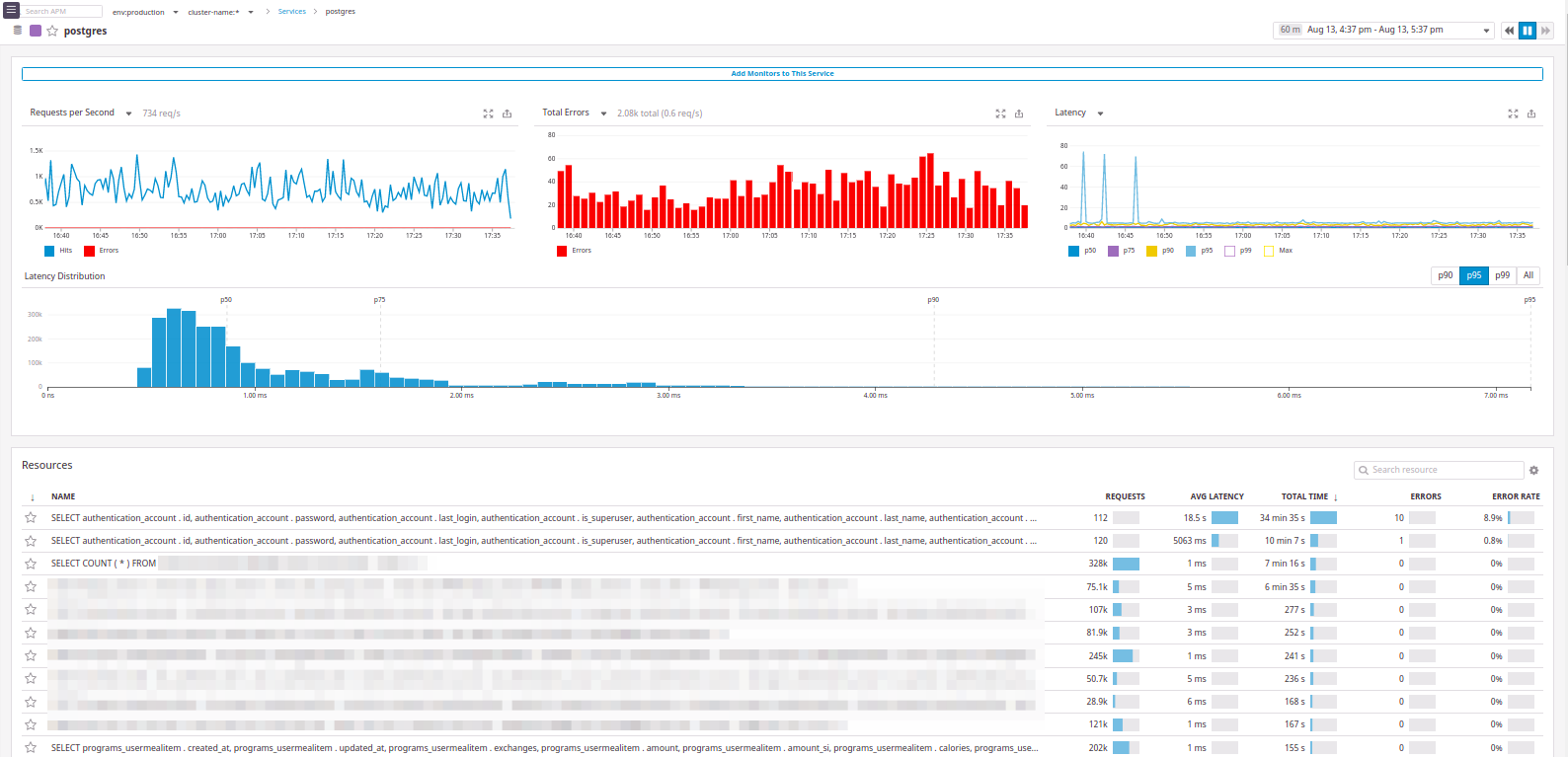
实际上,我们想要的一切都是:
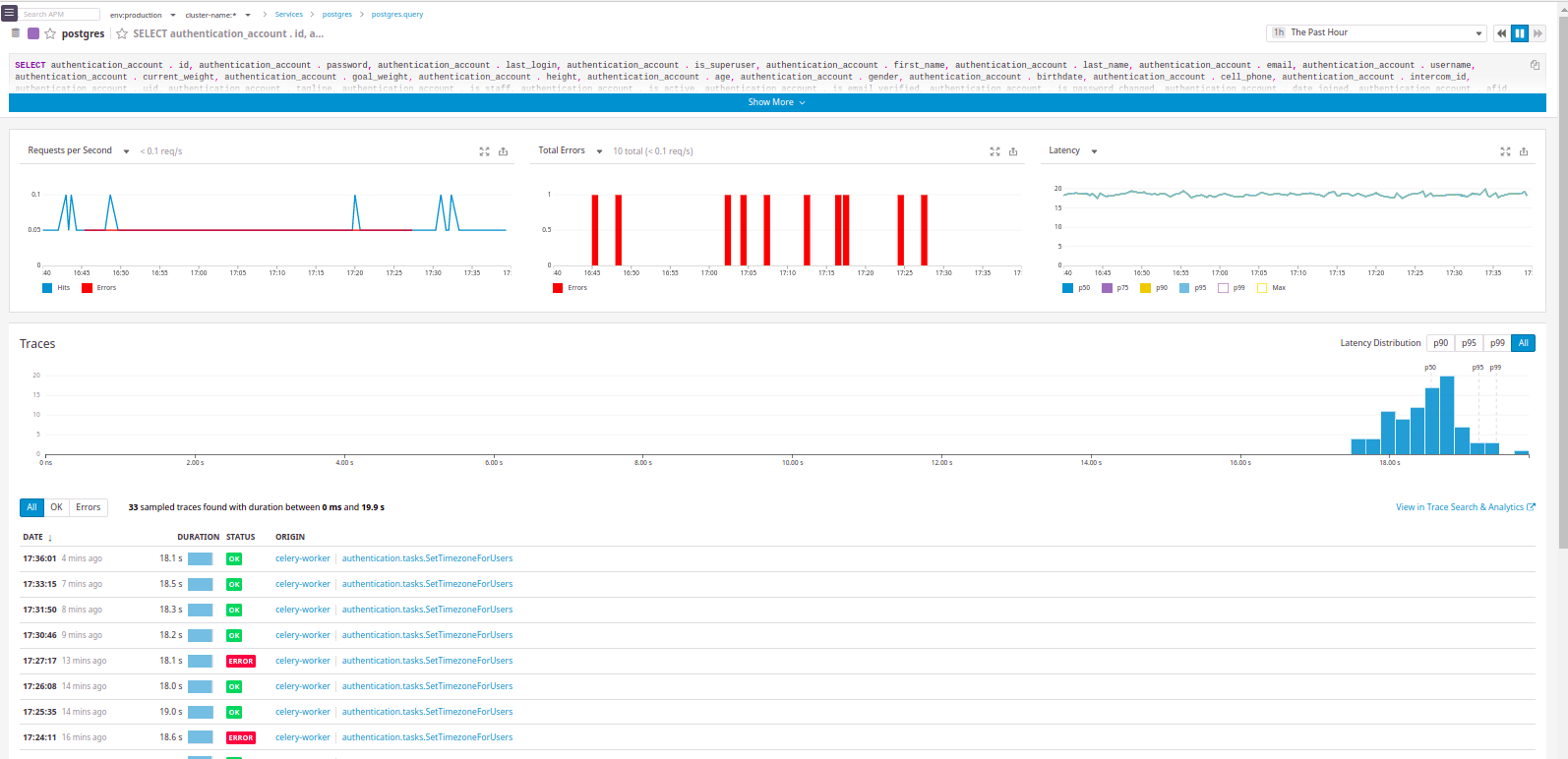
可以看出请求来自哪个“服务”。
记住Datadog与NGINX Ingress完美集成,并允许从请求到达集群的那一刻起进行端到端跟踪,并允许您接受statsd指标,收集日志和主机指标,这并不是多余的。
Datadog的一大优势在于其价格
包括监控基础架构,APM,日志管理和综合测试,即 您可以灵活选择计划。
2. Atatus
Atatus团队声称他们的服务“与New Relic相同,但更好。” 让我们看看是否真的是这样。
标题栏看起来确实一样,但是无法确定应用程序中使用的Redis和memcached。
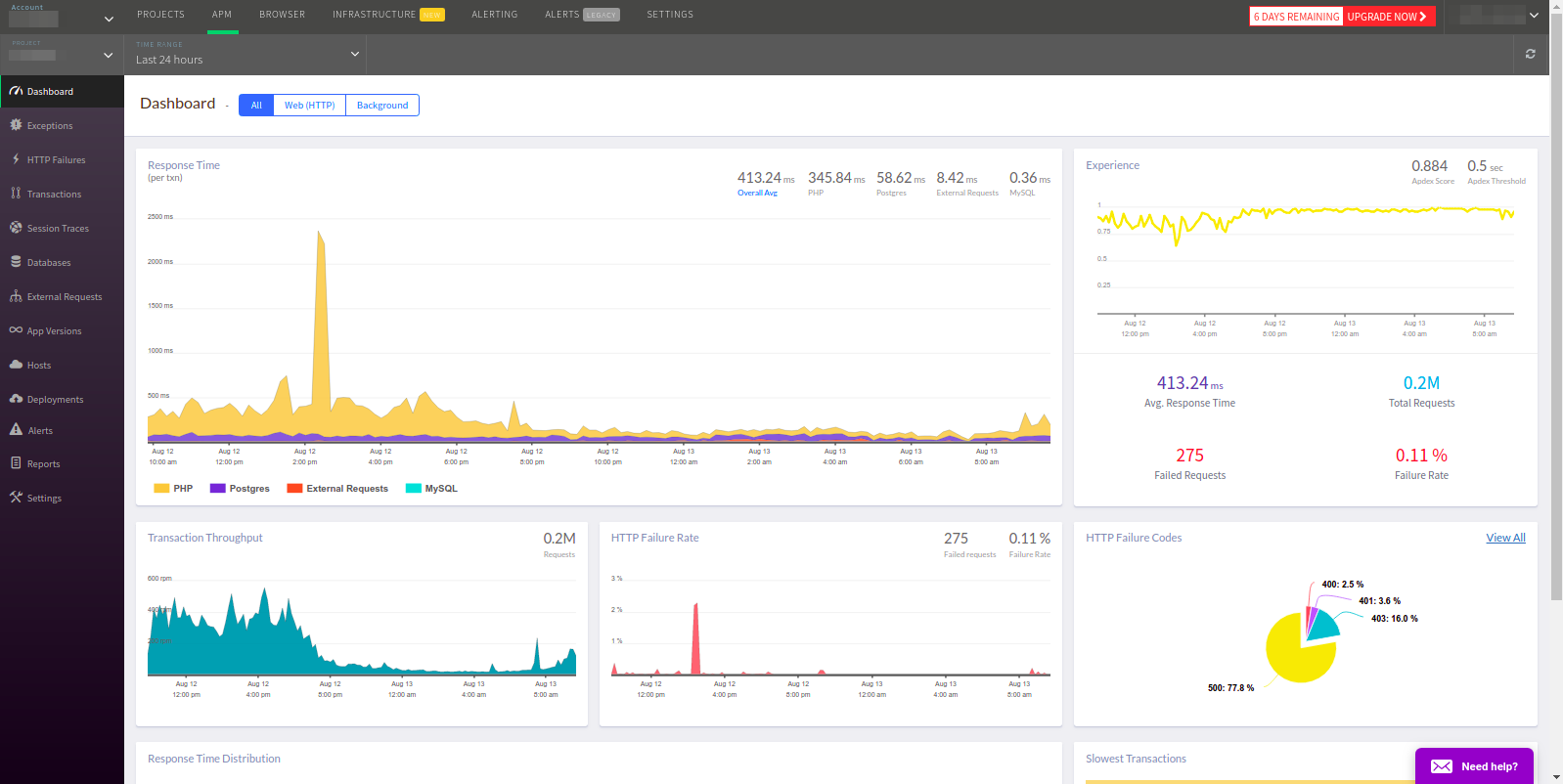
尽管通常只需要Web,但APM默认选择所有事务。 与Datadog一样,无法从主面板转到所需的服务。 而且,事务在错误之后列出,这对于APM来说似乎不太合逻辑。
在Atatus交易中,所有内容都尽可能类似于New Relic。 减号-您无法立即看到每个控制器的动态。 您必须在控制器表中查找它,并按“
最消耗时间”排序:

通常的控制器列表可在“
浏览”选项卡中找到:
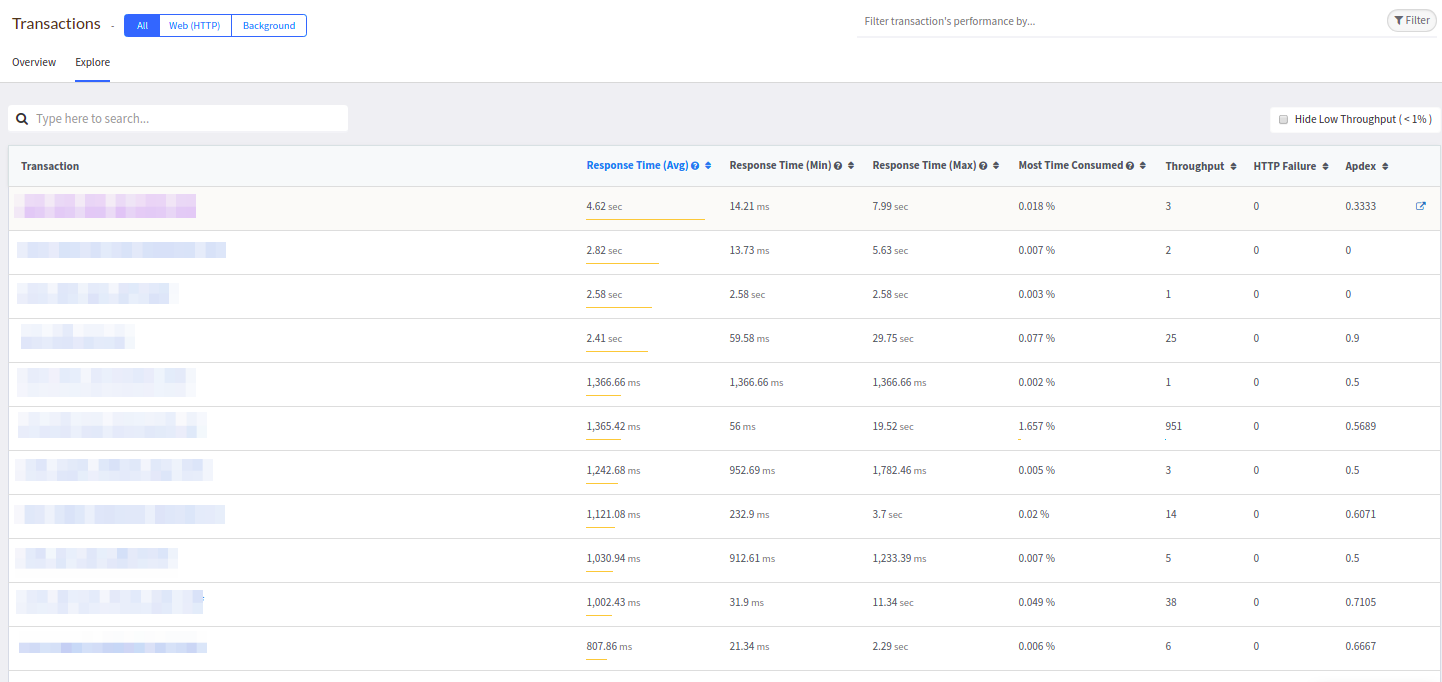
在某些方面,此表类似于Datadog,并且更类似于New Relic中的表。
可以部署每个事务,并查看应用程序做了什么:

该面板也更可能类似于Datadog:存在许多请求,即呼叫的总体情况。 顶部窗格提供了一个选项卡,其中包含
HTTP Failures错误和缓慢的
Session Traces请求示例:

如果进行事务处理,则会看到一个跟踪示例,您可以获取对数据库的查询列表并查看请求标头。 一切都类似于New Relic:

通常,Atatus对详细的跟踪记录感到满意-无需将典型的New Relic呼叫粘到提醒块中:
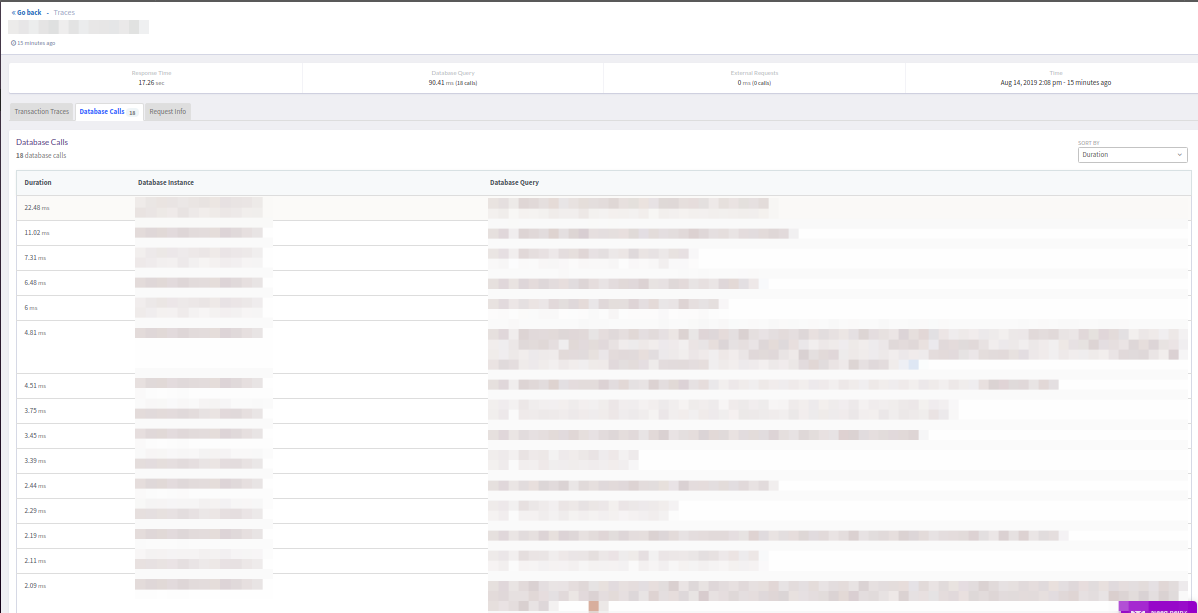
但是,没有足够的过滤器(例如在New Relic中)切断超快速请求(<5ms)。 另一方面,显示最终事务响应(成功或错误)是令人愉快的。
“
数据库”面板将帮助您检查应用程序对外部数据库的请求。 让我提醒您,尽管Redis和memcached也参与了该项目,但Atatus仅找到PostgreSQL和MySQL。
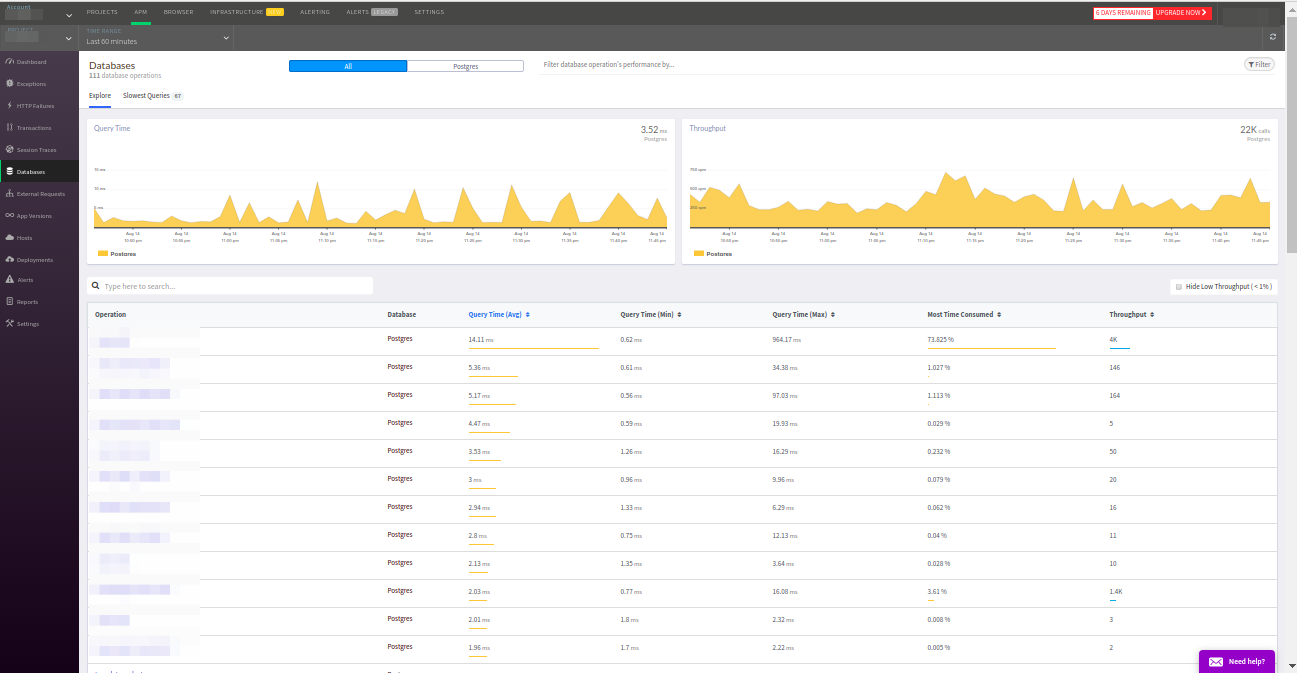
根据通常的标准对请求进行排序:响应频率,平均响应时间等。 我还要指出查询最慢的选项卡-这非常方便。 此外,该选项卡中的PostgreSQL数据与
pg_stat_statements扩展中的数据相吻合-极好的结果!
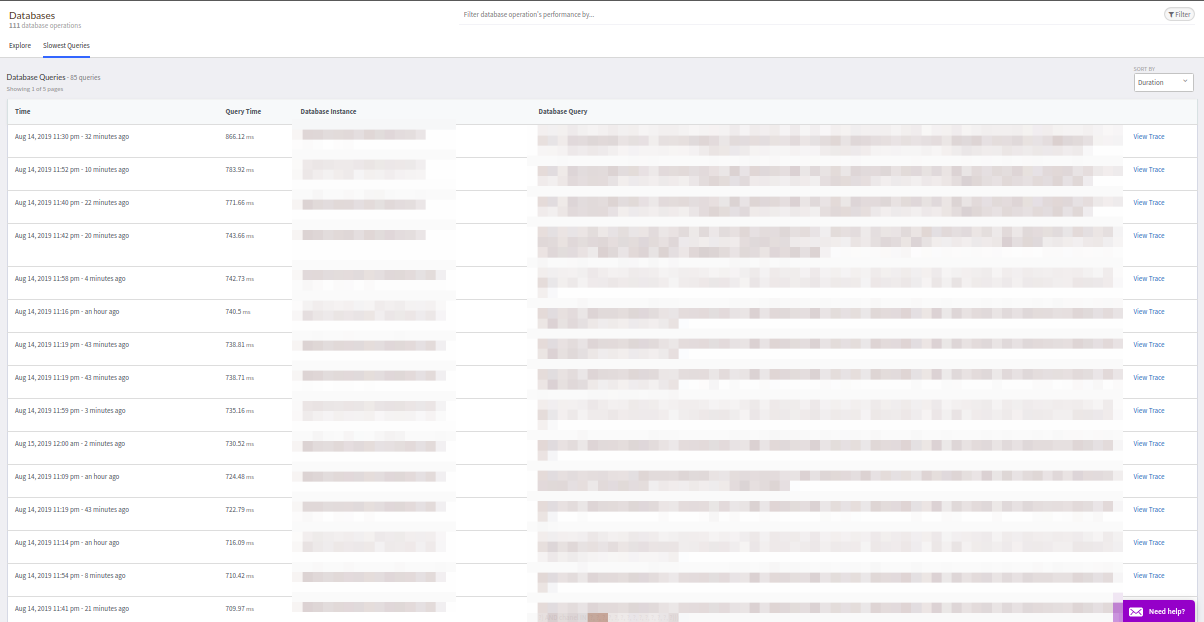
“
外部请求”选项卡与“数据库”相同。
结论
所提供的两种工具在APM的作用下均表现良好。 他们中的任何一个都可以提供必要的最低限额。 简要总结一下我们的印象如下:
数据狗
优点:
- 便捷的资费表(APM每主机成本31美元);
- 使用Python表现良好;
- 与OpenTracing集成的能力
- Kubernetes集成
- 与NGINX Ingress集成。
缺点:
- 由于模块错误(predis)导致应用程序无法访问的唯一APM
- 弱的PHP自动工具;
- 服务及其用途的定义有些奇怪。
阿塔图斯
优点:
缺点:
- 在较旧的操作系统(Ubuntu 12.05,CentOS 5)上不起作用;
- 自动工具较弱;
- 仅支持两种语言(Node.js和PHP);
- 接口运行缓慢。
鉴于Atatus的价格为每台服务器每月69美元,我们宁愿使用Datadog,它可以完全满足我们的需求(K8中的Web应用程序)并具有许多有用的功能。
聚苯乙烯
另请参阅我们的博客: