“顾问+”-律师,会计师等的参考系统。 它像手表一样稳定工作。 在本文中,建议您根据文本输出的需要来设置此时钟,即:查看如何处理系统使用python提供的文本信息。 在此过程中,使用标题中声明的文本元素。
栅栏上的阴影
作为长期在帮助程序“ Consultant +”中工作的律师,我在该系统中始终缺乏常规功能。 该功能如下。 当法规中出现任何更改时,K +员工以两列文本的形式发布更改概述:

左边的列是以前的样子,右边的列是现在生效的规范。 现在(几年前),功能已更新,更改
以粗体突出
显示并立即可见。 这一切都非常方便。 但是有些不舒服的事情。
首先,没有给出一些规范,因为 它们的数量对于K +员工来说太大了,您必须转到系统链接,其次,您不能只是通过将它们粘贴到常规的excel或word表中来抓取并复制这两列。
也许这是有意进行的,以便用户更积极地使用系统,包括不从那里进行任何传输。
好,必须修复它。
任务 :在可能的地方和不在可能的地方将文本分散在两列中-删除准则并将其全部放入Excel电子表格中。 同时,让我们看看如何使用python来更改文本中的字体,对齐方式和其他琐事。
例如,为将来的程序提供了一个示例,我们从K +对“ On JSC”定律的更改中获取。 该法律经常更改,因此需要做的工作。
将更改保存到常规txt文件中(例如,.txt版本)。 您会得到如下内容:

因此,很明显,每个更改之间都用一条实线分开,在保存之后,该更改采取了许多“ ???”的形式。 还有一个变化的方向不容忽视。 除了某些方面,一切看起来都很简单。
因此,遇到具有以下形式的更改:

另外,由于各个变化的长度明显不同,这一问题变得更加复杂。
我们进入K +。
创建一个新的Consult.py文件,并在其中添加第一行:
from __future__ import unicode_literals import codecs import openpyxl
openpyxl模块已经很熟悉,它允许您使用Excel,但是另外两个是新的。 它们的功能是正确处理俄语字符,这些字符通常会被程序错误地读取。
预先在程序外部创建一个新的空excel文件,并将其命名为version2.xlsx。 我们将使用程序打开该文件,并将数据写入其中。 这将是我们的最终文件。
因此,程序将打开excel文件并输入:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
同样在上面,我们创建了3个空列表,我们将在其中收集数据:test,test2,test3。
接下来,在变量“ a”中,我们将所有可能落入更改名称形式的内容放入。 在y中-将有一条分隔线。 长度相同:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
现在有趣的部分。
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
我们打开了cp1251编码的.txt文件。 通过strip方法,每行从头到尾都没有空格。
如果该行以单词“ old”开头,则将其跳过。 为什么我们需要保留“旧”和“新”,这已经很清楚了。 接下来,我们将这一行划分为:从开头到35个字符,从39个字符到结尾。 也就是说,我们消除了中间的差距:

我们将空间的内容放在col3的行中间,因为 如果将更改写在一行中,则它可能不是空格:

此外,如果该行以change标头开头(我们将这些标头写入变量a),那么我们将立即将此行写为excel而不进行任何拆分,并添加行-x + = 1(或x = x + 1)。我们遇到了,我们很想念。
考虑以下代码片段:
if len(col2)==0:
如果字符串的2个部分的长度为0,即不存在,则test2获取字符串的第一部分。 如果该行中有空格,但该行的第二部分不存在,则该行的第一部分和第二部分分别属于test和test2。
如果行中有空格,并且该行不为空并且其长度超过60个字符,则将其添加到test3。
如果该行是空的,也就是说,我们经历了整个更改,那么我们会将收集到的所有内容写到excel单元格中,同时检查测试中的空白(以便它不为空)和test3的长度。
最后,保存excel文件:
wb.save('2.xlsx')
python中的样式,字体和文本对齐
为我们的餐桌增添些美丽。
特别是,我们将使输出数据时,更改标头以粗体突出显示,并且文本本身更小且格式化以便于阅读。
Python允许您执行此操作。 为此,我们需要在将结果记录在excel文件中的地方添加和更改代码:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
也就是说,实际上,我们仅添加了适用的方法.font和.alignment。
整个程序采用以下形式:
代号 from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
因此,最后,在由程序处理文件之后,我们有了一个相当不错的表格,其中法律有所变化:
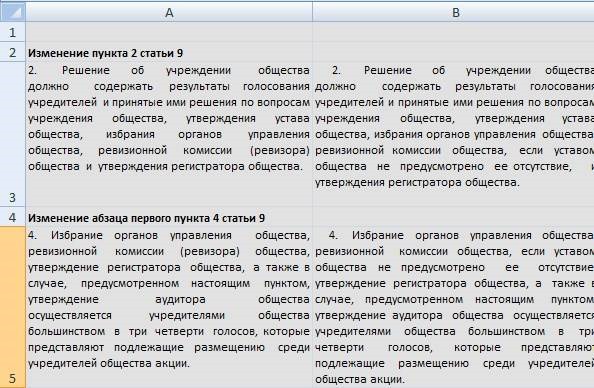
该程序可以从
此处的链接下载。
该程序处理的示例文件
在此处 。