大家好 在本文中,我将告诉您为什么我们九个月前在Avito选择Kafka的原因以及它的含义。 我将分享一种用例-消息代理。 最后,我们来谈谈应用Kafka即服务方法所获得的好处。
问题

首先,有一点背景。 一段时间以前,我们开始放弃单片架构,现在在Avito中已经有数百种不同的服务。 他们有自己的存储库,自己的技术堆栈,并负责自己的业务逻辑部分。
大量服务的问题之一是通信。 服务A通常想知道服务B拥有的信息,在这种情况下,服务A通过同步API访问服务B。 服务B想知道服务G和D会发生什么,而服务G和D又对服务A和B感兴趣。当有许多这样的“好奇”服务时,它们之间的联系就变成了一个纠结的球。
而且,在任何时候,服务A都可能变得不可用。 在这种情况下,服务B和与其相关的所有其他服务该怎么办? 而且,如果您需要进行一系列连续的同步调用以完成业务操作,则整个操作失败的可能性会更高(并且此链越长,则失败的可能性就越大)。
技术选择

好的,问题很明显。 您可以通过在服务之间建立集中式消息传递系统来消除它们。 现在,每个服务都足以仅了解此消息传递系统。 另外,系统本身必须具有容错能力并且可以在水平方向扩展,并且在发生事故的情况下,必须为随后的处理积累呼叫缓冲区。
现在让我们选择将在其上实现消息传递的技术。 为此,请先了解我们对她的期望:
- 服务之间的消息不应丢失;
- 邮件可能重复
- 消息可以存储和读取到几天的深度(持久缓冲区);
- 服务可以订阅他们感兴趣的数据;
- 多个服务可以读取相同的数据;
- 消息可能包含详细的批量有效负载(事件承载状态传输);
- 有时您需要一个消息顺序保证。
对于我们来说,选择具有最高吞吐量的最具扩展性和可靠性的系统(每秒几千字节的消息至少要发送10万条消息)也至关重要。
在这个阶段,我们告别了RabbitMQ(难以在高rps下保持稳定),SkyTools的PGT(不够快且可扩展性差)和NSQ(不持久)。 所有这些技术都在我们公司中使用,但它们不适合手头的任务。
然后,我们开始为我们寻找新技术-Apache Kafka,Apache Pulsar和NATS Streaming。
第一个掉落脉冲星的人。 我们认为Kafka和Pulsar是相当相似的解决方案。 尽管Pulsar经过大型公司的测试,但它是较新的并且具有较低的延迟(理论上),我们还是决定将Kafka排除在两者之外,以作为执行此类任务的事实上的标准。 将来我们可能会返回Apache Pulsar。
剩下两个候选人:NATS Streaming和Apache Kafka。 我们对这两种解决方案进行了详细的研究,并且两者都完成了任务。 但是最后,我们担心NATS Streaming的相对年轻(以及主要开发商之一Tyler Treat决定离开该项目并开始自己的项目-Liftbridge的事实)。 同时,NATS流的群集模式不允许强大的水平缩放(这在2017年添加分区模式之后可能不再是问题)。
但是,NATS Streaming是用Go编写的一项很酷的技术,并得到了Cloud Native Computing Foundation的支持。 与Apache Kafka不同,它不需要Zookeeper即可工作( 可能很快就会对Kafka说同样的话 ),因为它内部实现了RAFT。 同时,NATS Streaming更易于管理。 我们不排除将来我们会再次使用这项技术。
尽管如此,Apache Kafka如今已成为我们的赢家。 在我们的测试中,它被证明是非常快的(每秒读取和写入超过100万条消息,消息量为1 KB),足够可靠,可扩展且具有被大公司销售的可靠经验。 此外,Kafka支持至少几家大型商业公司(例如,我们使用Confluent版本),并且Kafka具有发达的生态系统。
点评卡夫卡
在开始之前,我立即推荐一本很棒的书- “ Kafka:权威指南” (这也是俄语翻译,但术语使大脑有些破损)。 在其中,您可以找到基本了解Kafka甚至更多的必要信息。 Apache文档本身和Confluent博客也写得很好并且易于阅读。
因此,让我们看一下卡夫卡是如何鸟瞰的。 基本的Kafka拓扑结构包括生产者,消费者,经纪人和动物园管理员。
经纪人

经纪人负责存储您的数据。 所有数据都以二进制形式存储,并且代理对它们是什么以及它们的结构是一无所知。
每种逻辑类型的事件通常都位于其自己的单独主题(主题)中。 例如,广告创建事件可以属于item.created主题,而广告更改事件可以属于item.changed。 主题可以视为事件的分类器。 在主题级别,您可以将以下配置参数设置为:
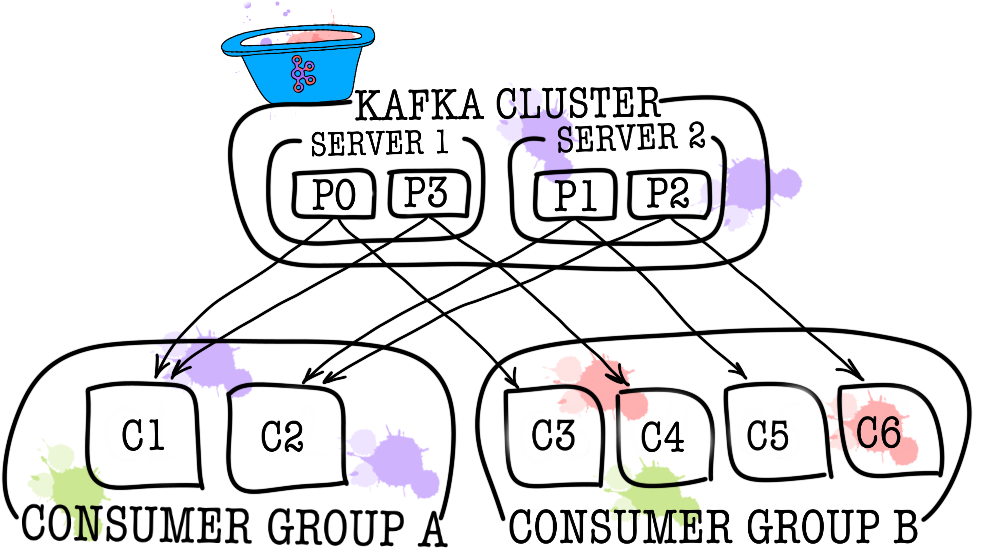
反过来,每个主题又分为一个或多个分区(partition)。 事件最终在分区中消失。 如果群集中有多个代理,则将在所有代理之间尽可能平均地分配分区,这将使您可以将在一个主题中读写一次的负载扩展到多个代理。
在磁盘上,每个分区的数据都存储为段文件,默认情况下等于1 GB(通过log.segment.bytes控制)。 一个重要功能是仅按段从分区中删除数据(触发保留时)(您无法从分区中删除一个事件,只能删除整个段,并且只能删除不活动的数据)。
动物园管理员
Zookeeper充当元数据存储库和协调器。 谁能说出代理是否还活着(您可以通过zookeeper-shell命令ls /brokers/ids通过Zookeeper的眼睛查看ls /brokers/ids ),哪个代理是控制器( get /controller ),分区是否与其副本处于同步状态( get /brokers/topics/topic_name/partitions/partition_number/state )。 同样,生产者和消费者将首先去动物园管理员那里,找出哪个经纪人存储哪些主题和分区。 如果为该主题指定了大于1的复制因子,则Zookeeper将指示哪些分区是引导分区(它们将被写入和读取)。 如果代理崩溃,则将在zookeeper中记录有关新领导者分区的信息(从1.1.0版开始, 是异步的, 这很重要 )。
在旧版本的Kafka中,zookeeper还负责存储偏移量,但是现在它们存储在代理上的特殊主题__consumer_offsets (尽管您仍然可以将zookeeper用于这些目的)。
使您的数据变成南瓜的最简单方法就是通过Zookeeper丢失信息。 在这种情况下,将很难理解从何处读取内容。
制片人
生产者通常是直接将数据写入Apache Kafka的服务。 生产者选择一个主题,主题信息将存储在该主题中,并开始向其中写入信息。 例如,生产者可以是广告服务。 在这种情况下,他将向主题主题发送事件,例如“广告创建”,“广告更新”,“广告删除”等。 每个事件都是一个键值对。
默认情况下,如果未设置键(丢失顺序),则所有事件均以循环方式由分区分区分发;如果存在键,则通过MurmurHash(键)分发所有事件(在同一分区内排序)。
在此立即值得注意的是,Kafka仅保证一个分区内的事件顺序。 但是实际上,这通常不是问题。 例如,您可以保证将同一公告的所有更改添加到一个分区(从而在公告中保留这些更改的顺序)。 您还可以在事件字段之一中传递序列号。
消费类
消费者负责从Apache Kafka检索数据。 如果您回到上面的示例,则使用者可以是一个审核服务。 该服务将订阅公告服务的主题,并且当出现新广告时,它将接收并分析其是否符合某些指定的策略。
Apache Kafka会记住使用者最近收到的事件( __consumer__offsets使用了__consumer__offsets服务主题),从而保证了使用者成功阅读后不会两次收到相同的消息。 不过,如果您使用选项enable.auto.commit = true并将跟踪用户在主题中的位置的工作完全交给Kafka,则可能会丢失数据 。 在生产代码中,使用者的位置通常是手动控制的(开发人员控制必须发生读取事件的提交时间)。
在一个使用者不足的情况下(例如,新事件的流量非常大),可以通过在使用者组中将它们链接在一起来添加更多的使用者。 从逻辑上讲,使用者组是完全相同的使用者,但是数据在组成员之间分配。 这使每个参与者都可以分享他们的信息,从而提高阅读速度。
测试结果

在这里,我不会写很多解释性文字,只是分享结果。 在3台物理机器(12个CPU,384GB RAM,15k SAS DISK,10GBit / s Net)上进行了测试,在lxc中部署了代理和Zookeeper。
性能测试
在测试过程中,获得了以下结果。
- 9个生产者同时记录1KB大小的消息的速度-每秒1300000个事件。
- 9个使用者同时读取1KB消息的速度-每秒1,500,000个事件。
容错测试
在测试过程中,获得了以下结果(3个经纪人,3个动物园管理员)。
- 中间商之一的异常终止不会导致集群暂停或无法访问。 这项工作照常进行,但是其余经纪人的工作量很大。
- 如果一个群集由三个代理组成且min.isr = 2,则两个代理的异常终止会导致该群集无法写入,但可读性强。 如果min.isr = 1,则群集将继续可用于读取和写入。 但是,此模式与对高数据安全性的要求相矛盾。
- Zookeeper服务器之一的异常终止不会导致群集关闭或无法访问。 工作照常进行。
- 两个Zookeeper服务器的异常终止会导致群集不可访问,直到至少其中一个Zookeeper服务器被还原。 该声明对于由3个服务器组成的Zookeeper集群是正确的。 结果,经过研究,决定将Zookeeper群集增加到5个服务器以提高容错能力。
卡夫卡即服务

我们确保Kafka是一项出色的技术,它使我们能够为我们解决任务集(实现消息代理)。 尽管如此,我们还是决定禁止服务直接访问Kafka并使用数据总线服务将其关闭。 我们为什么要这样做? 实际上有几个原因。
数据总线接管了所有与Kafka集成相关的任务(消费者和生产者的实现和配置,监视,警报,日志记录,扩展等)。 因此,与消息代理的集成尽可能简单。
数据总线允许从特定语言或库中提取数据以与Kafka一起使用。
数据总线允许其他服务从存储层抽象。 也许到了某个时候,我们会将Kafka更改为Pulsar,并且没人会注意到任何事情(所有服务仅了解数据总线API)。
数据总线接管了事件模式的验证。
实现了使用数据总线身份验证。
在数据总线的保护下,我们可以在不停机的情况下谨慎地更新Kafka版本,集中进行生产者,消费者,经纪人等的配置。
数据总线允许我们添加Kafka中不需要的功能(例如主题审核,监视群集中的异常,创建DLQ等)。
数据总线允许对所有服务集中实施故障转移。
目前,要开始将事件发送到消息代理,只需将一个小型库连接到您的服务代码即可。 仅此而已。 您有机会用一行代码编写,阅读和扩展。 整个实现对您而言是隐藏的,只有几根棒(像批处理的大小)伸出。 在后台,数据总线服务在Kubernetes中增加了必要数量的生产者和消费者实例,并为其添加了必要的配置,但是所有这些对于您的服务都是透明的。
当然,没有灵丹妙药,这种方法有其局限性。
- 与第三方库不同,数据总线需要自己支持。
- 数据总线增加了服务与消息代理之间的交互次数,与裸Kafka相比,这导致性能降低。
- 并非所有内容都可以简单地从服务中隐藏起来,我们不想在数据总线中复制KSQL或Kafka Streams的功能,因此有时您必须允许服务直接运行。
在我们的案例中,优点胜过缺点,因此决定用单独的服务覆盖消息代理是合理的。 在运营的一年中,我们没有发生任何严重的事故和问题。
PS感谢我的女友Ekaterina Oblyalyaeva为本文提供的精美图片。 如果您喜欢它们, 还有更多插图。