Google的新成果提供了一种神经网络架构,可以模拟生物的内在本能和反射,然后在整个生命中进行进一步的培训。
并且还大大减少了网络内的连接数量,从而提高了连接速度。
人工神经网络虽然在原理上与生物神经网络相似,但与它们的区别仍然很大,无法以其纯粹的形式用于创建强大的AI。 例如,现在不可能在模拟器(或鼠标,甚至是昆虫)中创建人的模型,以现代神经网络的形式给他“大脑”并进行训练。 就是行不通。
即使抛弃了学习机制上的差异(例如,在大脑中没有错误反向传播算法的精确模拟)以及缺乏多尺度时间相关性(基于这些差异,生物大脑也无法建立其工作),人工神经网络还有其他一些问题,使得他们无法充分模拟活着的大脑。 由于现在使用的数学仪器存在这些固有的问题,强化学习被设计为在奖励的基础上尽可能地模仿生物的训练,实际上并没有达到我们想要的效果。 尽管它基于真正的正确想法。 开发者自己开玩笑说大脑是RNN + A3C(即用于训练的循环网络+行为者批评算法)。
生物大脑和人工神经网络之间最明显的差异之一是,活脑的结构是经过数百万年的进化而预先配置的。 尽管负责哺乳动物较高神经活动的新皮层具有近似均匀的结构,但大脑的总体结构由基因清楚地定义。 而且,除了哺乳动物以外的动物(鸟,鱼)根本没有新皮层,但同时它们表现出复杂的行为,这是现代神经网络无法实现的。 一个人在大脑结构上也有身体上的局限性,这很难解释。 例如,一只眼睛的分辨率大约为100兆像素(约1亿个感光棒和视锥),这意味着从两只眼睛来看,视频流应为大约200兆像素,且频率至少为每秒15帧。 但实际上,视神经能够穿过自身的距离不超过2-3兆像素。 而且它的连接完全不指向大脑的最近部分,而是指向视觉皮层的枕骨部分。
因此,在不损害新皮层的重要性的情况下(粗略地说,它可以在出生时被视为随机启动的现代神经网络的类似物),事实表明,即使一个人在预定的大脑结构中也发挥着巨大作用。 例如,如果一个婴儿只有几分钟的年龄才能露出舌头,那么由于镜像神经元,它也会伸出舌头。 孩子们的笑声也会发生同样的事情。 众所周知,出生时的婴儿被“缝合”时对人脸的识别能力很高。 但更重要的是,所有生物的神经系统都针对其生活条件进行了优化。 如果宝宝饿了,它不会哭几个小时。 他会累的。 或害怕某事而闭嘴。 直到无法接近的葡萄饿死为止,狐狸才会精疲力尽。 她将进行几次尝试,确定他很痛苦然后离开。 这不是学习过程,而是生物学预定义的行为。 而且,不同的物种也有不同。 一些捕食者立即赶赴猎物,而另一些则坐在伏击中很长时间。 他们不是通过反复试验就了解到这一点,而是他们的本能是由本能给出的。 同样,许多动物从生命的一开始就制定了避免捕食者的程序,尽管他们实际上还无法学习它们。
从理论上讲,训练神经网络的现代方法能够从完全连接的网络中创建出这种经过预先训练的大脑的相似度,将不必要的连接归零(实际上是将它们切断),而仅留下必要的连接。 但这需要大量示例,尚不知道如何训练它们,最重要的是,目前尚无固定方法来修复大脑的“初始”结构。 随后的训练改变了这些权重,一切都变糟了。
Google的研究人员也提出了这个问题。 是否有可能创建类似于生物学的初始大脑结构,即已经为解决问题进行了优化,然后仅对其进行了重新训练? 从理论上讲,这将极大地缩小解决方案的空间,并允许您快速训练神经网络。
不幸的是,现有的网络结构优化算法(例如神经体系结构搜索(NAS))在整个模块上运行。 添加或删除后,必须从头开始重新训练神经网络。 这是一个资源密集的过程,不能完全解决问题。
因此,研究人员提出了一个简化版本,称为“重量不可知神经网络”(WANN)。 这个想法是用一个“普通”权重代替神经网络的所有权重。 而且,在学习过程中,并不是像普通的神经网络那样在神经元之间选择权重,而是选择网络本身的结构(神经元的数量和位置),权重相同将显示最佳结果。 然后,对其进行优化,以使网络在此总权重的所有可能值下正常工作(对于神经元之间的所有连接都是常见的!)。
结果,这给出了一个神经网络的结构,该结构不依赖于特定的权重,但是对每个人都适用。 因为它的工作归因于整体网络结构。 这类似于尚未在出生时用特定比例进行初始化的动物的大脑,但由于其总体结构已经包含了嵌入的本能。 并且在终生训练过程中随后对秤进行微调,使该神经网络变得更好。
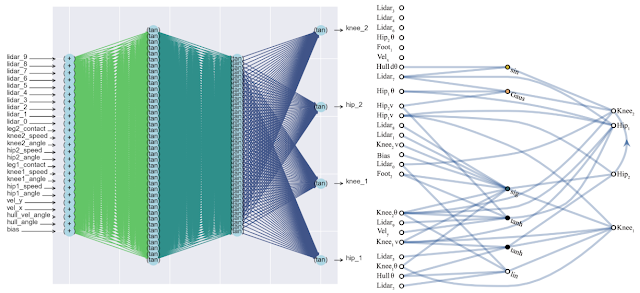
这种方法的副作用是可以大大减少网络中神经元的数量(因为仅保留最重要的连接),从而提高了速度。 下面是经典的完全连接神经网络(左)和匹配的新神经网络(右)的复杂性比较。
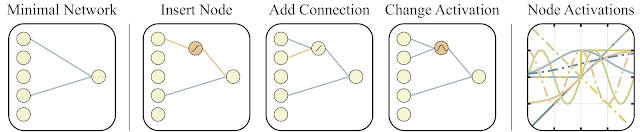
为了搜索这种架构,研究人员使用了拓扑搜索算法(NEAT)。 首先,创建一组简单的神经网络,然后执行以下三个动作之一:将新的神经元添加到两个神经元之间的现有连接中,将具有随机连接的新连接添加到另一个神经元中,或者神经元中的激活函数发生变化(请参见下图)。 然后,与传统的NAS不同,在神经元之间搜索最佳权重,在这里,所有权重都用一个单个数字初始化。 并进行了优化,以找到在这一总权重的各种值范围内最有效的网络结构。 因此,获得了一个网络,该网络不依赖于神经元之间的特定权重,而是在整个范围内都可以正常工作(但所有权重仍然是由一个数字发起的,与正常网络中的不同)。 此外,作为优化的另一个目标,他们试图使网络中神经元的数量最少。
以下是该算法的概述。
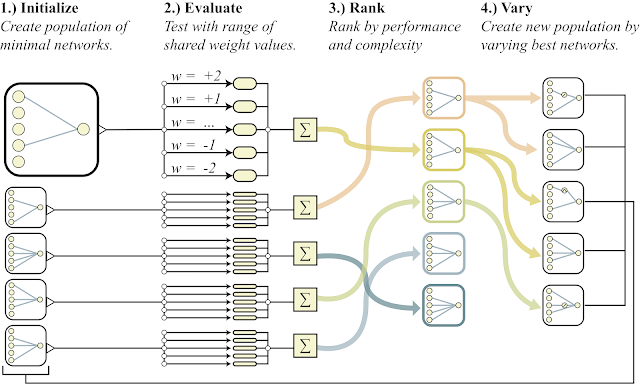
- 创建大量的简单神经网络
- 每个网络使用一个数字初始化其所有权重,并使用一个广泛的数字进行初始化:w = -2 ... + 2
- 根据解决方案的质量和神经元数量(向下)对生成的网络进行排序
- 在最佳代表部分,添加了一个神经元,一个神经元的一种连接或激活功能发生了变化
- 这些经过修改的网络在第1点中用作初始)
所有这些都是很好的,但是对于神经网络已经提出了数百个(如果不是数千个)不同的想法。 这在实践中可行吗? 是的,确实如此。 下面是这种网络体系结构针对经典摆式小车问题的搜索结果的示例。 从图中可以看出,神经网络适用于总重量的所有变体(+1.0更好,但也尝试将摆锤从-1.5提升)。 优化此单个权重后,它会开始完美完美地工作(图中的“微调权重”选项)。
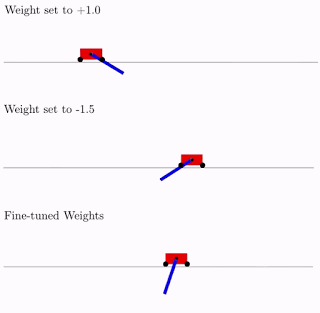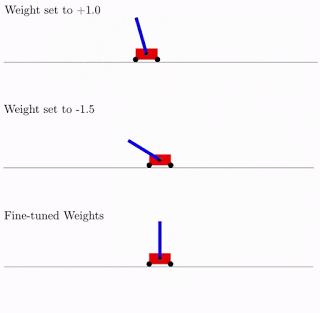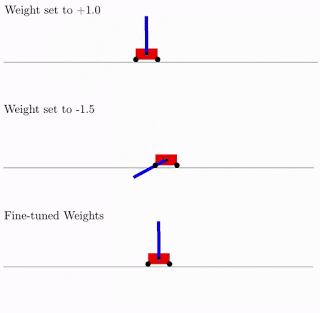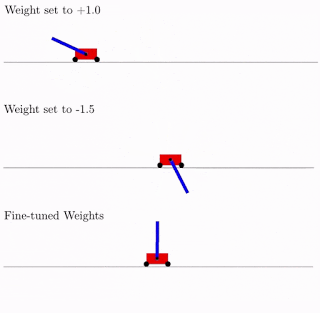
通常,您可以重新训练为单个总权重,因为架构的选择是在有限的离散数量的参数上完成的(在上面的示例中为-2,-1,1,2)。 并且您可以获得更准确的最佳参数,例如1.5。 您可以使用最佳的总权重作为重新训练所有权重的起点,就像在神经网络的经典训练中一样。
这类似于动物的训练方式。 动物在出生时具有接近最佳的本能,并使用基因赋予的这种大脑结构作为最初的本能,因此在生命过程中,动物会在特定的外部条件下训练大脑。 有关更多详细信息,请参见《自然》杂志上的最新文章 。
以下是WANN为基于像素的机器控制任务找到的网络示例。 请注意,这是乘坐“裸露的直觉”进行的,所有关节的总重量相同,而无需对所有重量进行经典的微调。 同时,神经网络的结构极其简单。
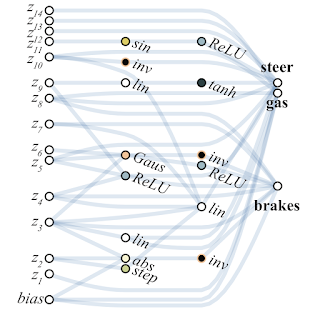

研究人员建议从WANN网络创建合奏,作为WANN的另一个用例。 因此,通常在MNIST上随机初始化的神经网络的准确性约为10%。 选定的单个WANN神经网络的收益率约为80%,但是来自WANN的具有不同总权重的集合已经显示> 90%。
结果,谷歌研究人员提出的搜索最佳神经网络初始结构的方法不仅模仿动物学习(具有内在的最佳本能并在生活中进行再训练),而且避免了通过经典进化算法对整个网络进行全面学习而模拟整个动物的生活,既简单又快速的网络。 仅需稍微训练即可获得完全最佳的神经网络就足够了。
参考文献
- Google AI博客条目
- 交互式文章,您可以在其中更改总重量并监视结果
- 自然界文章,关于出生时嵌入本能的重要性