我决定共享它,但我自己也不会忘记如何使用简单的统计工具来分析数据。 匿名调查被用作示例,说明了2014年和2019年乌克兰程序员的薪水,服务年限和职位。 (1)
分析步骤
- 数据预处理和初步分析( 任何对代码感兴趣的人 )
- 数据的图形表示。 分布密度函数。
- 我们制定原假设(H0)(2)
- 选择一个指标进行分析
- 我们使用引导方法来形成一个新的数据数组。
- 我们计算p值(3)以确认或反驳该假设
数据预处理
经过一些操作(
代码在此处 ),我们以以下形式显示数据:
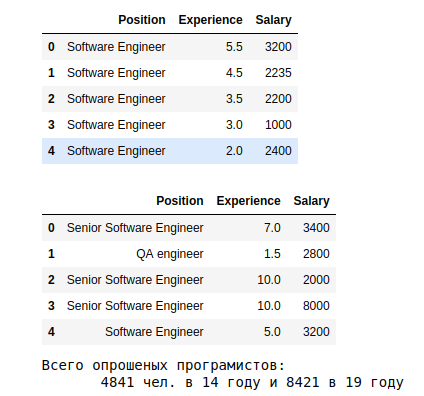
一年的更多分组(第19次):

最初的估计如下。
一个 结果表明,平均有19个工作了10年以上的人获得了3.5k以上的收入。 经验的依赖-> zp
c。 平均s.p. 在19年,根据专业化程度的不同,它们展示了10倍的传播-从System Architect的5k到Junior QA的575。
s 最后一块显示按行业分布。 有关软件工程师的大多数数据,无资格。
我们提请注意19年级的特征: 第9年的经验有些问题,并且没有根据初中,中级和高级的水平进行分类。 您可以更好地了解第9年异常值的原因。 但是对于此分析,我们将其保持不变。
但是有了类别-值得整理一下。 在19年中,软件工程师2739人(占总人数的35%)没有表明资格水平。 让我们为那些指出的人计算平均值和偏差。
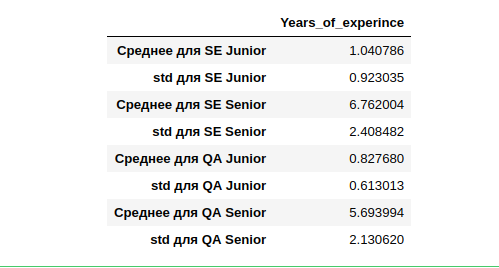
事实证明,SE Junior的平均工作经验(显示出来的人)是一年,与一年的偏差相当大。 SE Senior的经验最丰富,偏差也较大,为2.4年。
如果我们尝试计算中位数并使用表示该指标的人员的平均经验,然后对未表示该指标的人员进行分类,则可能无法正确地对整个样本进行聚类。 我们将特别在其他专业(而非SE和QA)上犯错误,即 数据太少。 而且,与第14年相比,它们很少。
我还能使用什么?
让我们仅将薪水水平作为技能水平的可靠指标! (我认为会有异议)。
首先,我们建立第19年的工资分配情况。
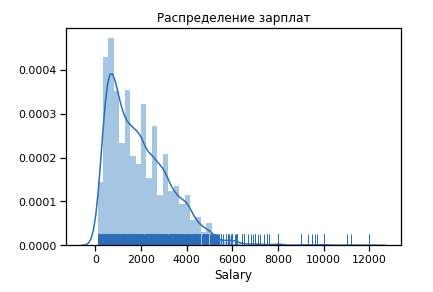
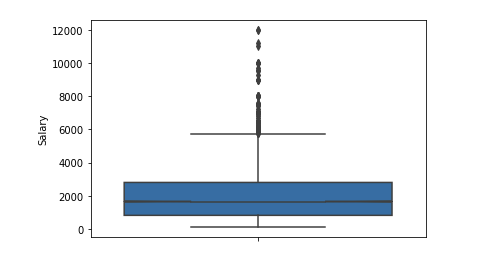
6 $ k之后的异常值显着数。 我们保留了限制范围[400-4000]。 任何程序员都应该获得超过400 :)
df_new = data_19_1[(data_19_1['Salary'] > 400) & (data_19_1['Salary'] < 4000)] sns.distplot(df_new['Salary'], rug=True, norm_hist=True)
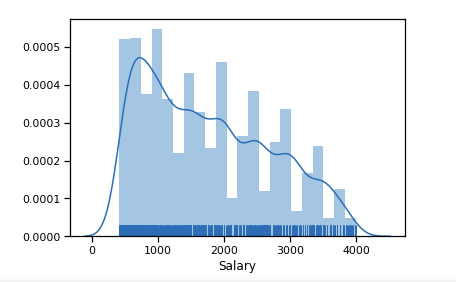
已经接近正态分布。
我们根据RFP撰写19年的技能水平。 3600美元的范围使我们可以很好地分为3类-1200美元
df_new.reset_index() df_new.loc['level'] = 0 df_new.loc[df_new.Salary <= 1200, 'level'] = 'Junior' df_new.loc[(df_new.Salary > 1200) & (df_new.Salary <= 2400), 'level'] = 'Middle' df_new.loc[df_new.Salary > 2401, 'level'] = 'Senior'
抽奖-19年的类别密度。
sns.set(style="whitegrid") fig, ax = plt.subplots() fig.set_size_inches(11.7, 8.27) plt.title(' 19 ') sns.barplot(x='level', y='Salary', hue='Experience', hue_order=[1,3,5,7,10], palette='Blues', \ data=df_new, ci='sd')

通过添加指定数量的体验(左上角),您可以看到不同的细微差别。 例如,Junior的平均年薪为1k,他的工作经验为5年。 在高级广告中,锡的最大散点(每列顶部的黑色短线)和许多其他有趣的细节。
这是前两个阶段结束的地方,我们使用引导程序进行假设检验。
我们制定原假设(H0)
在第一阶段,我们发现指定的工作经验并不十分准确地表示资格水平。 然后我们形成零假设(需要反驳的假设)
有很多选项(例如):
- 第14年薪资对资历的依赖性与第19年相同。
- 初级薪资自14年以来没有变化。
但是,由于指示的经验是一个不好的指标,并且某些类别的计算可能会造成混淆,因此我们采用一种简单且更具实质性的选择:
与19相同的14处的
平均sn值是我们的零假设H0(2)。
也就是说,我们假设5年的薪水没有变化。
尽管假说非常逼真,但尽管如此,我们仍可以通过计算原假设的P值来准确地进行检查。
第14年的平均薪水为$ 1797,置信区间为95%[300.0 4000.0]
19年的平均工资为1949美元,其置信区间为95%[300.0 5000.0]
14年和19年的平均工资差异:152美元
分析指标
选择平均值作为我们的度量标准是合乎逻辑的。 其他选项也是可能的,例如中位数,这通常在有大量异常值的情况下执行。 但是,将平均值作为估计值很容易理解,也可以提供一个好主意。
编写自举功能。
我们计算我们的统计数据。
p值= 0.0
P值最高为0.05被认为无关紧要,在我们的情况下,它等于0。这意味着原假设被
反驳 -14和19年的平均工资不同,这不是偶然的结果,也不是大量的异常值。
平均而言,我们生成了1万个这样的数组,与数据本身相比,无法获得更多的此类分离。
尽管我们在前两个阶段花费了大量精力,但我们制定了正确的假设并选择了正确的指标。 在具有大量变量的更复杂的任务中,如果没有此类初步步骤,则分析可能会导致错误的解释。 不要跳过它们。
通过对14年和19年薪水水平的研究,我们得出以下结论:
- 根据调查数据,指定的经验并不是确定薪资和资格水平的完全合适的标准。
- 技能水平的划分很可能会根据薪水水平进行划分。
- 程序员的薪水从14增加到19(平均8.5%),这不是偶然的结果。
谢谢您的关注。 我将很高兴发表评论和批评。
资料来源
- https://jobs.dou.ua/salaries/ (调查结果)
- https://zh.wikipedia.org/wiki/空假设
- https://zh.wikipedia.org/wiki/P-value