不久前,我们
宣布了一个公开发布,并以MIT许可打开了
LuaVela的源代码
-Lua5.1的实现,它基于LuaJIT 2.0。 我们从2015年开始研究它,到2017年初,它已用于公司95%以上的项目中。 现在,我想回顾过去的道路。 什么情况促使我们开发自己的编程语言实现? 我们遇到了什么问题以及如何解决? LuaVela与其他LuaJIT叉子有何不同?
背景知识
本节基于我们对HighLoad ++的
报告 。 我们从2008年开始积极使用Lua编写产品的业务逻辑。 最初是香草Lua,从2009年开始-LuaJIT。 RTB协议为处理请求奠定了一个严格的框架,因此过渡到该语言的更快实现是一个合理的解决方案,从某种意义上说,这是必要的解决方案。
随着时间的流逝,我们意识到LuaJIT体系结构存在某些限制。 对我们来说最重要的是LuaJIT 2.0使用严格的32位指针。 这导致我们遇到以下情况:在64位Linux上运行,将进程内存的虚拟地址空间的大小限制为1 GB(在更高版本的Linux内核中,此限制增加为2 GB):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
这种限制成为一个大问题-到2015年,1-2 GB的内存已不再足以供许多项目加载逻辑所使用的数据。 值得注意的是,Lua虚拟机的每个实例都是单线程的,并且不知道如何与其他实例共享数据-这意味着在实践中,每个虚拟机可能要求的内存大小不超过2GB / n,其中n是服务器的工作流程数应用程序。
我们为该问题提供了几种解决方案:减少了应用服务器中的线程数量,尝试通过LuaJIT FFI组织对数据的访问,测试了向LuaJIT 2.1的过渡。 不幸的是,所有这些选择要么在经济上不利,要么从长远来看不能很好地扩展。 给我们留下的唯一一件事就是抓住机会,分叉LuaJIT。 此刻,我们做出的决定在很大程度上决定了项目的命运。
首先,我们立即决定不对语言的语法和语义进行任何更改,重点是消除LuaJIT的体系结构限制,这对公司来说是个问题。 当然,随着项目的发展,我们开始添加扩展(我们将在下面进行讨论)-但是我们将所有新的API与标准语言库隔离开来。
此外,我们放弃了跨平台,而只支持我们唯一的生产平台Linux x86-64。 不幸的是,我们没有足够的资源来充分测试我们将要对该平台进行的巨大更改。
快速浏览平台
让我们看看指针大小的限制是从哪里来的。 首先,在Lua 5.1中,
数字类型是C类型的double(有些小警告),它对应于IEEE 754标准定义的double precision类型。在此64位类型的编码中,突出显示了值的范围NaN。 特别是,如何在[0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF]。
因此,我们可以将一个“实”双精度数或某个实体打包到一个64位值中,从double类型的角度来看,这些实体将被解释为NaN,从我们平台的角度来看,这将更有意义-例如,根据对象的类型(高32位)和指向其内容的指针(低32位):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
这项技术有时称为NaN标记(或NaN装箱),TValue基本上描述了LuaJIT如何表示Lua中的变量值。 TValue还具有第三个假设,用于存储函数指针和用于展开Lua堆栈的信息,也就是说,在最终分析中,数据结构如下所示:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
上面定义中的frame.link字段的类型为uintptr_t,因为在某些情况下它存储指针,而在其他情况下则是整数。 结果是虚拟机堆栈的非常紧凑的表示形式-实际上,它是一个TValue数组,并且该数组的每个元素在情况上都被解释为一个数字,然后被解释为指向对象的类型化指针,或者被解释为有关Lua堆栈框架的数据。
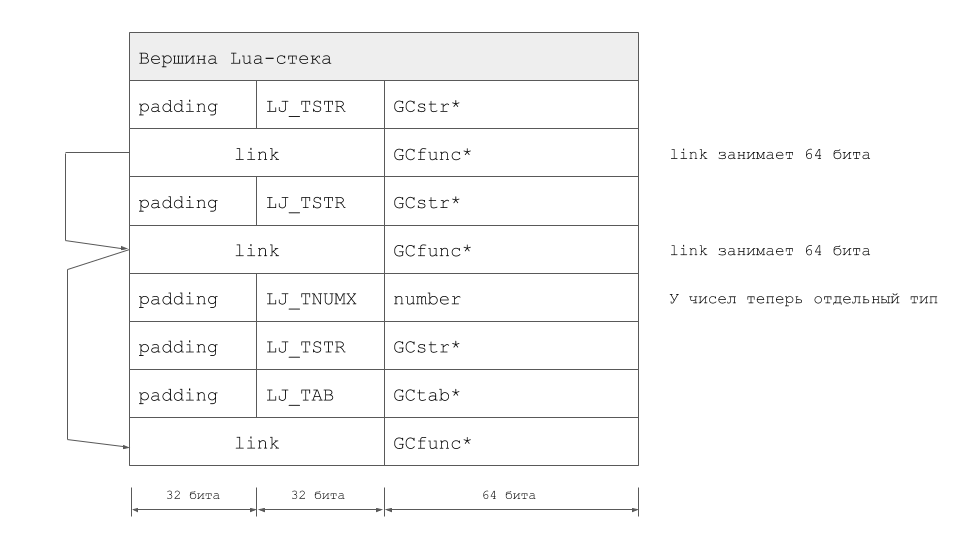
让我们来看一个例子。 想象一下,我们从LuaJIT这个Lua代码开始,并在print函数中设置了一个断点:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
此时的Lua堆栈如下所示:

一切都会好起来的,但是,一旦我们尝试在x86-64上启动,该技术就会开始失败。 如果我们在32位应用程序的兼容模式下运行,则会遇到上面已经提到的mmap限制。 64位指针根本无法使用。 怎么办 要解决此问题,我必须:
- 将TValue从64位扩展到128位:这样,我们在64位平台上获得了“诚实的” void *。
- 相应地更正虚拟机代码。
- 对JIT编译器进行更改。
事实证明,更改的总量非常重要,这使我们与原始LuaJIT疏远了。 值得注意的是,TValue扩展并不是解决问题的唯一方法。 在LuaJIT 2.1中,我们通过实现LJ_GC64模式进行了另一种选择。 彼得·考利(Peter Cawley)为这种操作模式的发展做出了巨大贡献,他在伦敦的一次会议上阅读了有关该方法的内容。 好吧,对于LuaVela,同一示例的堆栈如下所示:
最初的成功和项目的稳定
经过几个月的积极开发,是时候在战场上试用LuaVela了。 作为实验,我们从内存消耗方面选择了最有问题的项目:必须使用的数据量显然超过了1 GB,因此他们被迫使用各种解决方法。 最初的结果令人鼓舞:与这些项目中使用的LuaJIT配置相比,LuaVela稳定且显示出更好的性能。
同时,出现了测试问题。 幸运的是,我们不必从头开始,因为从开发的第一天开始,除了登台服务器,我们还可以使用:
- 执行所有公司项目的业务逻辑的应用程序服务器的功能和集成测试。
- 单个项目的测试。
如实践所示,这些资源足以调试并将项目置于最低的稳定状态(他们完成了开发程序集-已部署到暂存状态-有效且不会崩溃)。 另一方面,从长远来看,通过其他项目进行这样的测试是完全不合适的:像编程语言的实现这样复杂的项目不能拥有自己的测试。 此外,直接在项目中缺少测试纯粹是在技术上使错误的查找和纠正变得复杂。
在理想的世界中,我们不仅要测试我们的实现,还要进行一系列测试,以使我们能够
根据语言的
语义对其进行验证。 不幸的是,在这件事上我们有些失望。 尽管Lua社区愿意创建现有实现的分支,但直到最近,仍缺少一组类似的验证测试。 当FrançoisPerrad在2018年底
宣布 lua-Harness项目时,情况变得更好了。
最后,我们通过将Lua生态系统中最完整,最具代表性的测试套件集成到我们的存储库中,解决了测试问题:
- 语言创建者为实现Lua 5.1而编写的测试。
- LuaJIT作者Mike Pall在社区提供的测试 。
- lua线束
- CERN正在开发MAD项目测试的一部分。
- 我们在IPONWEB中创建了两套测试,到目前为止,这些测试将继续进行补充: 一套用于平台的功能测试, 另 一套使用cmocka框架测试C API,而所有这些测试都缺乏Lua代码级别的测试。
每一批测试的推出使我们能够检测和纠正2-3个严重错误-因此,显而易见,我们的努力得到了回报。 尽管测试语言运行时和编译器(静态和动态)的主题确实是无限的,但我们认为我们为项目的稳定开发奠定了坚实的基础。 我们
在2017年莫斯科的Lua和
HighLoad ++ 2018上两次谈论了测试我们自己的Lua实现的问题(包括诸如使用测试台和事后调试的主题)-欢迎对细节感兴趣的每个人观看这些报告的视频。 好吧,当然,请查看我们存储库中的
tests目录。
新功能
因此,我们可以使用由小型团队开发的Linux x86-64的Lua 5.1稳定实现,该团队逐渐“掌握”了LuaJIT的遗产并积累了专业知识。 在这种情况下,扩展平台和添加既不是Vanilla Lua也不是LuaJIT中没有的功能,但是可以帮助我们解决其他紧迫问题的功能的愿望变得很自然。
文档以RST格式提供了所有扩展的详细说明(使用cmake和&& make docs构建HTML格式的本地副本)。 有关Lua API扩展的完整说明,请参见此
链接 ,以及有关C API
的信息 。 不幸的是,在评论文章中不可能谈论所有事情,因此这里列出了最重要的功能:
- DataState-组织来自Lua虚拟机的多个独立实例对对象的共享访问的能力。
- 可以为协程设置超时并中断执行时间长于超时时间的程序的能力。
- 一组JIT编译器优化旨在抵抗在对象之间复制数据时跟踪数量的指数增长-我们在HighLoad ++ 2017上谈到了这一点,但是仅仅几个月前,我们还有新的工作思路尚待记录。
- 新工具包:采样分析器。 dumpanalyze编译器调试输出分析器等。
这些功能中的每一个都应单独撰写一篇文章-在评论中写下您想阅读的更多内容。
在这里,我想谈谈我们如何减少垃圾收集器的负载。
密封使您可以使垃圾收集器无法访问对象。 在我们的典型项目中,Lua虚拟机内部的大多数数据(高达80%)已经是业务规则,这是一个复杂的Lua表。 该表的生命周期(分钟)比已处理请求的生命周期(数十毫秒)长得多,并且其中的数据在查询处理期间不会更改。 在这种情况下,强制垃圾收集器一次又一次地围绕这个巨大的数据结构进行递归是没有意义的。 为此,我们以递归方式“密封”对象,并对数据进行重新排序,以使垃圾收集器永远不会到达“密封”对象或其内容。 在Vanilla Lua 5.4中,将
通过支持世代垃圾收集中的世代对象来
解决此问题。
重要的是要记住,“密封的”物体一定不能写。 不遵守此不变性会导致出现悬空的指针:例如,“密封”对象是指常规对象,而垃圾收集器在堆周围时跳过“密封”对象,而跳过常规对象-区别在于无法释放“密封”对象,和通常的一个可以。 在实现了对这个不变式的支持之后,我们实质上获得了
对对象的免费
免疫支持,而Lua中经常缺少这种支持。 我强调,不变的和“密封的”物体不是一回事。 第二个属性表示第一个属性,但反之则不然。
我还注意到,在Lua 5.1中,可以使用元表来实现免疫功能-解决方案非常有效,但就性能而言并不是最赚钱的。 有关“密封”,免疫力以及我们在日常生活中如何使用它们的更多信息,请参见
本报告。
结论
目前,我们对实施的稳定性和机会感到满意。 尽管由于最初的限制,我们的实现在便携性方面明显不如Vanilla Lua和LuaJIT,但它解决了我们的许多问题-我们希望这些解决方案对其他人有用。
另外,即使LuaVela不适合生产,我们也邀请您使用它作为切入点,以了解LuaJIT或其叉子的工作方式。 除了解决问题和扩展功能外,多年来,我们重构了代码库的重要部分,并撰写了有关项目内部结构的
培训文章 -其中许多内容不仅适用于LuaVela,而且适用于LuaJIT。
感谢您的关注,我们正在等待请求!