有一次,我在探索Internet的深度时偶然发现了一个视频 ,其中一个人使用遗传算法训练蛇。 我也希望如此。 但是仅仅采取相同的方式并用python编写就不会有意思。 我决定对培训代理系统使用一种更现代的方法,即Q网络。 但是,让我们从头开始。
强化训练
在机器学习中,RL(强化学习)与其他领域大不相同。 不同之处在于,经典的ML算法从现成的数据中学习,而RL可以说是为自己创建了这些数据。 RL的想法是,除了称为代理的算法本身之外,还存在放置该代理的环境。 在每个阶段,代理必须执行某种动作(动作),并且环境将根据奖励(奖励)及其状态(状态)做出响应,代理基于该状态执行动作。
Dqn
应该对算法的工作原理进行解释,但是我会留下一个链接 , 链接到聪明人解释它的地方。
蛇的实现
找出c rl后,我们需要创建一个环境,在其中放置代理。 幸运的是,无需重新发明轮子,因为像open-ai这样的公司已经编写了体育馆,您可以使用它来编写自己的环境。 在图书馆中,它们已经大量存在。 从简单的atari游戏到复杂的3d模型。 但在这一切之中,没有蛇。 因此,我们继续进行其创建。
我不会描述在健身房中创建环境的所有时刻,但是我只会展示主类,在该类中需要实现几个功能。
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """ . , """ def reset(self): """ """ def render(self, mode='human'): """ """
但是要实现这些功能,我们需要提出一个奖励制度,并以何种形式提供有关环境的信息。
条件
在视频中,一个人向蛇赋予了与墙壁,蛇和苹果8个方向的距离。 那是24个数字。 我决定减少数据量,但要使其复杂一些。 首先,我将结合到墙壁的距离和到蛇的距离。 简而言之,我们将告诉她到可以在碰撞中杀死的最近物体的距离。 其次,只有3个方向,它们将取决于蛇的运动方向。 例如,起步时蛇会抬头,因此我们将告诉它到上,左和右墙的距离。 但是,当蛇的头部向右转时,我们将已经报告了到右,上,下墙壁的距离。 为了简单起见,我将提供图片。

我还决定玩苹果。 我们将以坐标系中(x,y)坐标的形式显示有关此信息,该坐标系始于蛇的头部。 坐标系统还将改变其在蛇头后面的方向。 图片之后,我认为它肯定应该变得清晰。
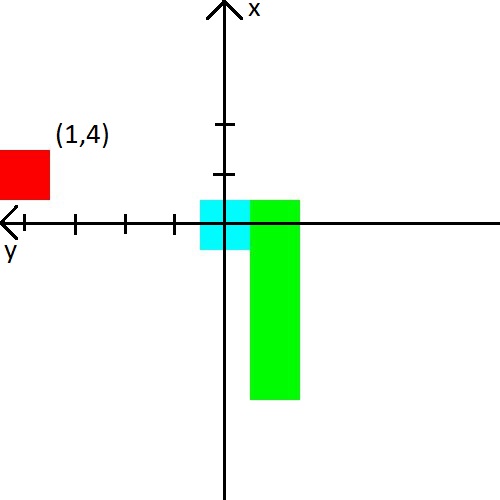
奖赏
如果您可以提出带有状态的某种特征,并希望神经网络能够解决这个问题,那么有了这个奖励,一切都会变得更加复杂。 这取决于她代理是否会学习以及他是否会学习我们想要的东西。
我将立即提供经过稳定训练的奖励系统。
- 每一步的奖励是-0.25。
- 死亡时-10。
- 死亡时,最多15个步骤-100。
- 当吃一个苹果sqrt(吃的苹果数 )* 3.5。
并举例说明导致不良奖励制度的原因。
- 如果您在前几个步骤中没有给死亡足够小的报酬,那么蛇会更喜欢靠墙杀死。 这比寻找苹果要容易得多:)
- 如果您对这些步骤给予积极的回报,那么蛇将开始不断旋转。 因为在她看来,这比寻找苹果更有利可图。
- 在许多其他情况下,蛇根本不会学习。
总结
编写蛇的主要兴趣是通过对蛇的环境了解甚少来了解蛇的学习方式。 她学习得很好,因为苹果的平均食用率达到23,在我看来,这并不是很差。 因此,该实验可以认为是成功的。
源代码