我以前很怕缓存。 我真的不想爬上去看看它是什么,我立即想像出一些发动机舱Luto企业的东西,只有奥林匹克奥林匹克的获胜者才能弄清楚。 事实证明并非如此。 事实证明,缓存在任何项目中都非常简单,易于理解并且非常容易实现。
在本文中,我将尽我所能解释有关缓存的简单知识。 您将学习如何在1分钟内实现缓存,如何通过键缓存,设置缓存生存期以及许多其他方面的知识,如果您被指示要在工作项目中缓存某些内容,并且不想弄混脸
为什么我说“受信任”? 通常,由于缓存是有意义的,因此可以应用到大型,高负载的项目中,每分钟有成千上万的请求。 在此类项目中,为了不使数据库过载,它们通常会缓存存储库调用。 尤其是如果已知以某个频率更新某个主系统的数据。 我们自己不编写此类项目,我们致力于它们。 如果项目很小并且不会威胁到过载,那么当然最好不要缓存任何东西-始终新鲜的数据总是比定期更新的数据更好。
通常,在培训岗位上,演讲者首先会在引擎盖下爬行,开始深入研究技术胆量,这使读者倍感困扰,只有到那时,当他翻阅了文章的大部分内容并且不了解任何内容时,它便会告诉读者它是如何工作的。 一切都会与我们不同。 首先,我们使它工作,并且最好以最少的努力,然后,如果您有兴趣,就可以在缓存层下面查看,在垃圾箱内部查看并微调缓存。 但是,即使您不这样做(并且从第6点开始),您的缓存也可以那样工作。
我们将创建一个项目,在其中我们将分析我承诺的所有缓存方面。 最后,像往常一样,将有一个指向项目本身的链接。
0.创建一个项目
我们将创建一个非常简单的项目,在其中我们可以从数据库中获取实体。 我向项目添加了Lombok,Spring Cache,Spring Data JPA和H2。 虽然,只有Spring Cache可以省掉。
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
我们只有一个实体,我们称其为User。
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
添加存储库和服务:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
当我们输入get()服务方法时,我们将其记录在日志中。
连接到Spring Cache项目。
@SpringBootApplication @EnableCaching
项目准备就绪。
1.缓存返回结果
Spring Cache做什么? Spring Cache只是缓存特定输入参数的返回结果。 让我们来看看。 我们将@Cacheable批注放在get()服务方法上,以缓存返回的数据。 我们将此注释命名为“用户”(我们将进一步分析为什么单独进行此操作)。
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
为了检查它是如何工作的,我们将编写一个简单的测试。
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
题外话,为什么我通常编写AbstractTest并从中继承所有测试。如果该类具有自己的@SpringBootTest批注,则每次都会为该类重新引发上下文。 由于上下文可能会持续5秒钟或40秒钟,因此无论如何这都会极大地阻碍测试过程。 同时,上下文通常没有区别,并且在同一类中运行每组测试时,无需重新启动上下文。 如果像我们这样,在抽象类上仅放置一个注释,例如,这将使我们仅引发一次上下文。
因此,如果可能的话,我宁愿减少在测试/组装过程中提出的上下文数量。
我们的测试做什么? 他创建了两个用户,然后两次将其从数据库中拉出。 回想一下,我们放置了@Cacheable批注,该批注将缓存返回的值。 从get()方法接收到对象后,我们将对象输出到日志中。 同样,我们将有关应用程序每次访问的信息记录到get()方法。
运行测试。 这就是我们在控制台中得到的。
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
如我们所见,前两次我们确实使用了get()方法,并实际上从数据库中获取了用户。 在所有其他情况下,都没有对方法的真正调用,应用程序通过键获取了缓存的数据(在这种情况下,这是id)。
2.缓存密钥声明
在某些情况下,缓存的方法会包含多个参数。 在这种情况下,可能有必要确定进行缓存的参数。 我们在方法中添加了一个示例,该示例会将由参数组装的实体保存到数据库中,但是如果已经存在具有相同名称的实体,则不会保存它。 为此,我们将name参数定义为缓存键。 它看起来像这样:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
让我们编写相应的测试:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
我们将尝试创建三个用户,其中两个的名称将相同
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
并且其中两个电子邮件将匹配
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
在创建方法中,我们记录该方法被调用的所有事实,并且还将记录该方法返回给我们的所有实体。 结果将是这样的:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
我们看到,实际上,该应用程序调用了3次该方法,并且仅两次调用了该方法。 一旦键与方法匹配,它就简单地返回一个缓存的值。
3.强制缓存。 @CachePut
在某些情况下,我们想缓存某个实体的返回值,但是同时,我们需要更新缓存。 对于此类需求,存在@CachePut批注。 它将应用程序传递到方法中,同时为返回值更新缓存,即使它已被缓存。
添加一些可以保存用户的方法。 我们将使用普通的@Cacheable批注标记其中一个,使用第二个@CachePut标记。
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
第一种方法将简单地返回缓存的值,第二种方法将强制更新缓存。 缓存将使用键#user.name执行。 我们将编写相应的测试。
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
根据已经描述的逻辑,第一次通过createOrReturnCached()方法保存名称为“ Vasya”的用户时,我们将收到一个缓存的实体,并且应用程序将不会自行输入该方法。 如果调用createAndRefreshCache()方法,则名为“ Vasya”的键的缓存实体将在缓存中被覆盖。 让我们运行测试,看看控制台中将显示什么。
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
我们看到user1已成功写入数据库和缓存。 当我们尝试再次记录具有相同名称的用户时,我们得到了第一个调用的缓存结果(user2,其ID与user1相同,这告诉我们该用户未被写入,这只是一个缓存)。 接下来,我们通过第二种方法写入第三个用户,即使使用缓存的结果,该用户仍然会调用该方法并将新结果写入缓存。 这是user3。 如我们所见,他已经有了一个新的ID。 之后,我们调用第一个方法,该方法采用user3添加的新缓存。
4.从缓存中删除。 @CacheEvict
有时有必要硬更新缓存中的某些数据。 例如,一个实体已经从数据库中删除,但是仍然可以从缓存中访问它。 为了保持数据的一致性,我们至少不需要在缓存中存储已删除的数据。
向该服务添加更多方法。
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
第一个只会删除用户,第二个也会删除用户,但是我们将使用@CacheEvict批注对其进行标记。 添加一个将创建两个用户的测试,此后将通过一种简单的方法删除一个用户,然后通过一个带注释的方法删除一个用户。 之后,我们将通过get()方法吸引这些用户。
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
符合逻辑的是,由于已经缓存了我们的用户,因此删除将不会阻止我们获取它,因为它已被缓存。 让我们看看日志。
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
我们看到应用程序两次都安全地使用了get()方法,并且Spring缓存了这些实体。 接下来,我们通过不同的方法删除它们。 我们以通常的方式删除了第一个,并且保留了缓存的值,因此当我们尝试使用户的ID为1时,我们成功了。 当我们尝试获取用户2时,该方法返回EntityNotFoundException-缓存中没有此类用户。
5.分组设置。 @缓存
有时,一个方法需要几个缓存设置。 @Caching注释用于这些目的。 它可能看起来像这样:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
这是对注释进行分组的唯一方法。 如果您尝试堆积类似
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
然后IDEA会告诉您事实并非如此。
6.灵活的配置。 缓存管理器
最终,我们找出了缓存,对我们而言,它不再是令人难以理解和恐惧的东西。 现在,让我们来看看幕后情况,看看我们如何大致配置缓存。
对于此类任务,有一个CacheManager。 无论Spring Cache在哪里,它都存在。 当我们添加@EnableCache批注时,Spring将自动创建这样的缓存管理器。 如果我们自动包装ApplicationContext并在断点处将其打开,则可以验证这一点。 除其他bin外,还将有一个cacheManager bean。
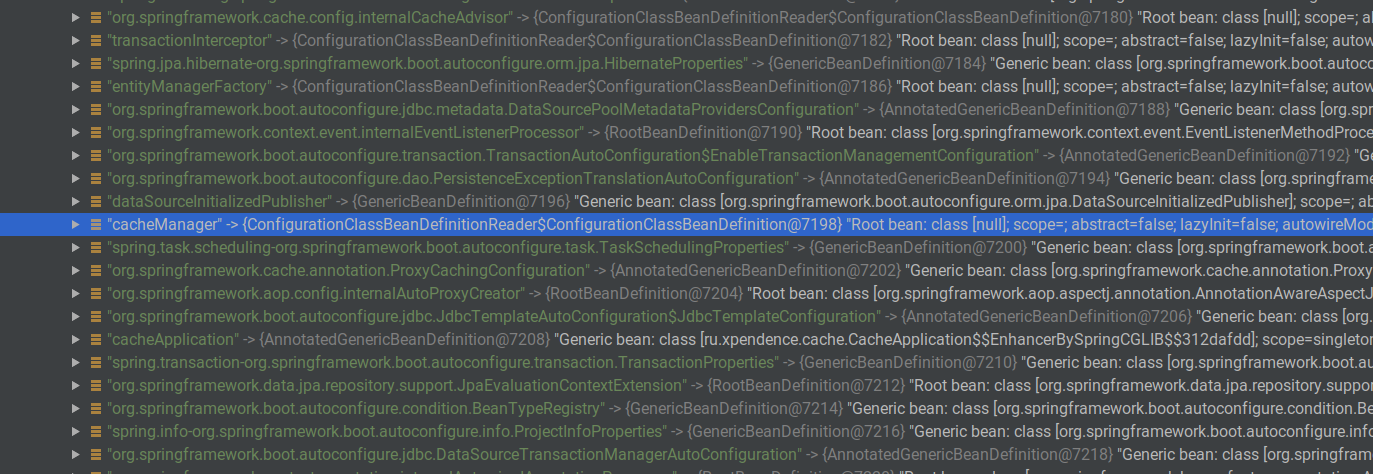
在已经创建了两个用户并将其放入缓存的阶段,我停止了该应用程序。 如果我们通过Evaluate Expression调用所需的bean,我们将看到确实存在这样的bean,它具有一个带有“ users”键的ConcurentMapCache和值ConcurrentHashMap,该值已经包含了缓存的用户。

反过来,我们可以与Habr和程序员一起创建我们的缓存管理器,然后根据自己的喜好对其进行微调。
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
剩下的只是选择我们将使用的缓存管理器,因为其中有很多。 我不会列出所有的缓存管理器,只要知道有这样的内容就足够了:
- SimpleCacheManager是最简单的缓存管理器,便于学习和测试。
- ConcurrentMapCacheManager-懒惰地初始化每个请求的返回实例。 还建议您测试和学习如何使用缓存以及一些诸如我们这样的简单操作。 为了认真处理缓存,建议使用以下实现。
- JCacheCacheManager , EhCacheCacheManager , CaffeineCacheManager是认真的“合作伙伴”缓存管理器,可以灵活地自定义并执行各种动作的任务。
作为我的谦虚文章的一部分,我将不介绍最后三个的缓存管理器。 相反,我们将以ConcurrentMapCacheManager为例,介绍设置缓存管理器的几个方面。
因此,让我们重新创建我们的缓存管理器。
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
我们的缓存管理器已准备就绪。
7.缓存设置。 使用寿命,最大尺寸等。
为此,我们需要一个相当流行的Google Guava库。 我拿了最后一个。
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
创建缓存管理器时,我们将覆盖createConcurrentMapCache方法,在该方法中,我们将从Guava调用CacheBuilder。 在此过程中,将要求我们通过初始化以下方法来配置缓存管理器:
- maximumSize-缓存可以包含的值的最大大小。 使用此参数,您可以尝试在数据库负载和JVM RAM之间找到折衷方案。
- refreshAfterWrite-将值写入高速缓存之后的时间,之后它将自动更新。
- expireAfterAccess-值的最后一次调用后的生存期。
- expireAfterWrite-写入缓存后值的生存期。 这是我们将定义的参数。
和其他。
我们在经理中定义记录的生存期。 为了不长时间等待,请设置1秒。
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
我们编写与这种情况相对应的测试。
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
我们将几个值保存到数据库中,如果数据被缓存,则不保存任何内容。 首先,我们保存两个值,然后等待1秒钟,直到缓存失效,然后再保存另一个值。
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
日志显示,首先我们创建了一个用户,然后尝试了另一个用户,但是由于数据已缓存,因此我们从缓存中获取数据(在两种情况下,当保存时和从数据库获取时)。 然后,高速缓存变坏了,因为一条记录告诉我们有关用户的实际保存和实际接收的信息。
8.总结
迟早,开发人员都需要在项目中实现缓存。 我希望本文能帮助您理解主题并大胆地研究缓存问题。
该项目的Github在这里:
https :
//github.com/promoscow/cache