在
上一篇文章中,我们讨论了如何尝试使用Watcher并提出了测试报告。 我们会定期进行此类测试,以平衡大型公司或运营商云的功能以及其他关键功能。
要解决的问题的高度复杂性可能需要几篇文章来描述我们的项目。 今天,我们发布了有关平衡云中虚拟机的系列文章的第二篇。
一些术语
VmWare引入了DRS(分布式资源调度程序)实用程序,以平衡其虚拟化环境的负载。
如
searchvmware.techtarget.com/definition/VMware-DRS所写
“ VMware DRS(分布式资源调度程序)是一种实用程序,可在虚拟环境中平衡计算负载与可用资源。 该实用程序是称为VMware Infrastructure的虚拟化程序包的一部分。
用户使用VMware DRS定义在虚拟机(VM)之间分配物理资源的规则。 可以将该实用程序配置为手动或自动控制。 可以轻松地添加,删除或重组VMware资源池。 如果需要,可以在不同业务部门之间隔离资源池。 如果一个或多个虚拟机的工作负荷发生巨大变化,则VMware DRS会在物理服务器之间重新分配虚拟机。 如果减少了总体工作量,则某些物理服务器可能会暂时关闭并且工作量会得到合并。”为什么需要平衡?
我们认为,DRS是云不可或缺的功能,尽管这并不意味着DRS应该随时随地使用。 根据云的用途和需求,对DRS和平衡方法可能会有不同的要求。 也许在某些情况下根本不需要平衡。 甚至有害。
为了更好地了解DRS客户的需求和需求,并考虑其目标。 云可以分为公共云和私有云。 这是这些云与客户目标之间的主要区别。
我们为自己得出以下结论:
对于提供给大型企业客户的
私有云 ,可以在以下限制条件下应用DRS:
- 信息安全和计费相似性规则,以实现平衡;
- 发生事故时是否有足够的资源;
- 虚拟机数据驻留在集中式或分布式存储系统上;
- 管理,备份和平衡程序的时间多样性;
- 仅在客户端主机的总数之内进行平衡;
- 仅在严重失衡之间进行平衡,才能最有效,最安全地迁移VM(毕竟迁移可能会失败);
- 平衡相对“安静”的虚拟机(“嘈杂”虚拟机的迁移可能需要很长时间);
- 考虑“成本”的平衡-存储系统和网络上的负载(具有针对大型客户的自定义体系结构);
- 平衡考虑到每个VM的个人行为;
- 下班后(晚上,周末,节假日)保持平衡是可取的。
对于为小型客户提供服务的
公共云 ,可以使用具有高级功能的DRS进行更多使用:
- 缺乏信息安全限制和相似性规则;
- 云内的平衡;
- 在任何合理时间保持平衡;
- 平衡任何虚拟机;
- 平衡“嘈杂的”虚拟机(以免干扰其余虚拟机);
- 虚拟机数据通常位于本地驱动器上;
- 考虑平均存储和网络性能(云架构是统一的);
- 根据通用规则和数据中心行为的可用统计信息进行平衡。
问题复杂度
平衡的困难在于DRS必须在许多不确定因素下工作:
- 每个客户信息系统的用户行为;
- 信息系统服务器运行的算法;
- DBMS服务器行为
- 加载计算资源,存储,网络;
- 彼此之间在争夺云资源方面的服务器交互。
随着时间的流逝,大量虚拟应用程序服务器和数据库在云资源上的负载不断增加,其后果可能会发生,并且在不可预测的时间之后会产生不可预测的影响。 即使是用于控制相对简单的过程(例如,用于控制发动机,家用热水系统),自动控制系统也需要使用复杂的
比例积分微分反馈算法。

我们的任务要复杂许多数量级,并且存在即使没有发生用户外部影响的情况,系统也无法在合理的时间内将负载平衡到既定值的风险。
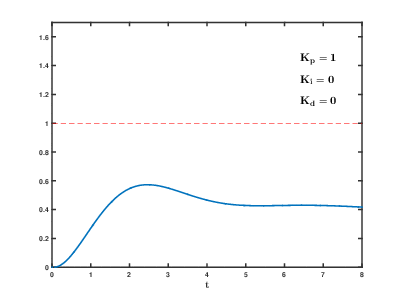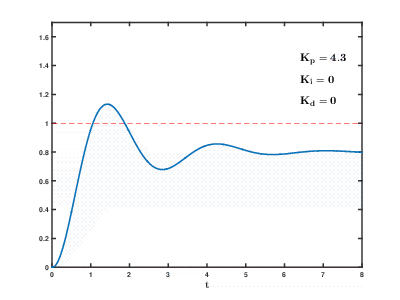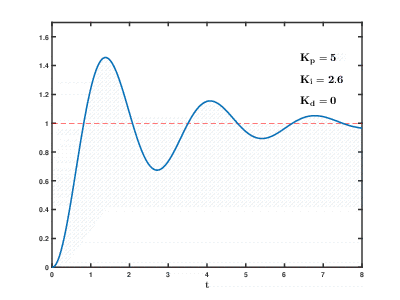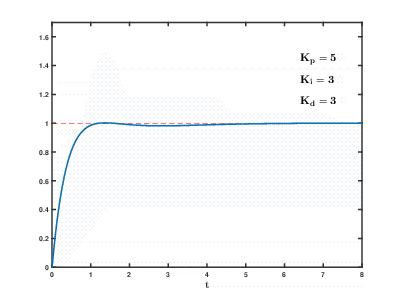
我们发展的历史
为了解决这个问题,我们决定不从头开始,而是以现有经验为基础,并开始与该领域的专家进行互动。 幸运的是,我们对问题的理解是完全吻合的。
第一阶段
我们使用了基于神经网络技术的系统,并尝试在此基础上优化我们的资源。
这个阶段的兴趣是测试新技术,其重要性是应用非标准方法来解决问题,而在其他条件相同的情况下,标准方法实际上已经用尽了。
我们启动了系统,然后我们真正达到了平衡。 云的规模无法让我们获得开发人员宣布的乐观结果,但是很明显,平衡是可行的。
而且,我们有相当严重的局限性:
- 要训练神经网络,虚拟机需要运行数周或数月而无需进行重大更改。
- 该算法被设计为基于对早期“历史”数据的分析进行优化。
- 为了训练神经网络,需要足够大量的数据和计算资源。
- 优化和平衡很少能完成-每隔几个小时一次,这显然是不够的。
第二阶段
由于我们对事务状态不满意,因此我们决定修改系统,以回答
主要问题 -我们是为谁做的?
首先是企业客户。 因此,我们需要一个高效运行的系统,并具有那些只能简化实施的公司限制。
第二个问题是“运营”一词的含义是什么? 经过短暂的辩论,我们认为可以在5-10分钟的响应时间基础上进行构建,以使短期跳跃不会使系统引起共振。
第三个问题是要选择平衡服务器数量的多少?
这个问题是由自己决定的。 通常,客户端不会使服务器聚合变得很大,这与本文中将聚合限制为30至40台服务器的建议是一致的。
另外,通过分割服务器池,我们简化了平衡算法的任务。
第四个问题是,神经网络在长期的学习过程和难得的平衡中适合我们多少? 我们决定放弃它,转而使用更简单的运算算法,以便在几秒钟内获得结果。
在
此可以找到使用这种算法的系统描述及其缺点
。我们实施并启动了该系统,并获得了令人鼓舞的结果-现在,它可以定期分析云负载并就移动虚拟机提出建议,这些建议在很大程度上是正确的。 即使到现在,我们仍然可以通过提高现有虚拟机的质量来实现为新虚拟机释放10-15%的资源。

当RAM或CPU检测到不平衡时,系统会向Tionics调度程序发出命令以执行所需虚拟机的实时迁移。 从监视系统可以看出,虚拟机从一个(上)主机移至另一(下)主机,并释放了上层主机上的内存(以黄色圆圈突出显示),分别占用了下层主机上的内存(以白色圆圈突出显示)。
现在,我们试图更准确地评估当前算法的有效性,并试图找出其中可能存在的错误。
第三阶段
您似乎可以对此保持冷静,等待有效的证明并结束本主题。
但是以下明显的优化机会正在推动我们迈入新的阶段。
- 例如, 此处和此处的统计数据表明,两处理器和四处理器系统的性能明显低于单处理器的系统。 这意味着与单处理器处理器相比,所有用户从多处理器系统中购买的CPU,RAM,SSD,LAN,FC所获得的收益要低得多。
- 资源规划人员自己可以处理严重的错误, 这是有关此主题的文章之一 。
- 英特尔和AMD提供的用于监视RAM和缓存的技术使您能够研究虚拟机的行为,并将其放置为使嘈杂的邻居不会干扰安静的虚拟机。
- 扩展参数集(网络,存储,虚拟机优先级,迁移成本,迁移准备情况)。
合计
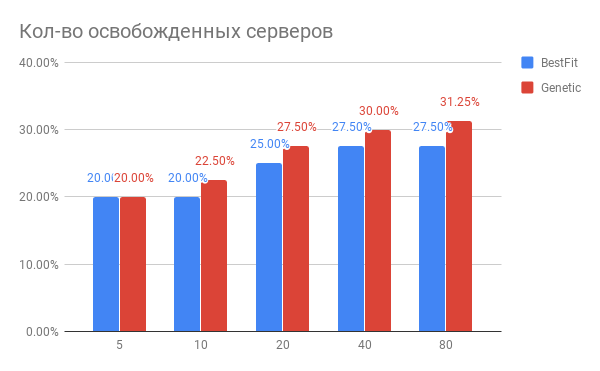
我们改进平衡算法的工作结果是一个明确的结论,即由于采用了现代算法,可以实现数据中心资源(25-30%)的显着优化并提高客户服务质量。
当然,基于神经网络的算法是一个有趣的解决方案,需要进一步开发,并且由于存在限制,因此不适用于解决私有云的体积特征问题。 同时,在较大规模的公共云中,该算法显示了良好的结果。
在以下文章中,我们将告诉您有关处理器,调度程序和高级平衡功能的更多信息。