近年来,使用“变压器”模型的
神经机器翻译 (NMP)取得了非凡的成功。 基于深度神经网络的IMF通常仅根据数据本身就在大量文本(文本对)的并行情况下从头到尾进行培训,而无需分配确切的语言规则。
尽管取得了所有成功,但NMP模型可能对输入数据的细微变化敏感,这些细微变化可能以各种错误的形式表现出来-过度翻译,过度翻译和错误翻译。 例如,下一个德国提案中,高质量的NMP模型“变压器”将正确翻译。
“ Der Sprecher des Untersuchungsausschusses帽子,Gericht zu Ziehen,跌倒了,Zeugen weiterhin weigern死了,Eine Aussage zu machen。”
(机器翻译:“调查委员会发言人宣布,如果传唤的证人继续拒绝作证,他将被带上法庭。”)
翻译:调查委员会的一名代表宣布,如果受邀证人继续拒绝作证,他将被追究责任。
但是,当您对传入句子进行少量更改,将单词geladenen替换为同义词vorgeladenen时,翻译会发生巨大变化(并且变得不正确):
“ Der Sprecher des Untersuchungsausschusses帽子,Gericht zu Ziehen,Vorgeladenen Zeugen weiterhin weigern下降,Eine Aussage zu machen。”
(机器翻译:“调查委员会宣布,如果被邀请的证人继续拒绝作证,他将被绳之以法。)。
翻译:调查委员会宣布,如果被邀请的证人继续拒绝作证,他将被绳之以法。
NMP模型缺乏稳定性,因此不允许将商业系统应用于无法接受相似程度的不稳定性的任务。 因此,学习可持续翻译模型不仅是可取的,而且经常是必需的。 同时,尽管计算机视觉研究人员社区积极研究了神经网络的稳定性,但有关稳定学习NMP模型的材料很少。
在我们的
论文 “具有双重对抗输入的可持续机器翻译”中,我们提出了一种方法,该方法使用生成的对抗示例来改善小输入变化下机器翻译模型的稳定性。 我们会教一个稳定的NMP模型,以克服考虑到该模型的知识而产生的竞争性示例,并扭曲其预测。 我们证明了这种方法提高了标准测试中NMP模型的效率。
AdvGen进行模型训练
理想的NMP模型应该为略有差异的不同输入生成相似的转换。 我们的方法的想法是使用竞争性输入来干扰翻译模型,以期提高其稳定性。 这是使用对抗生成(AdvGen)算法完成的,该算法生成有效的竞争示例,这些示例会干扰模型,然后将其输入模型进行训练。 尽管此方法的灵感来自于生成对抗网络(GSS)的思想,但它并未使用区分器网络,而只是在训练中使用了竞争性示例,实质上使训练集变得多样化和扩展。
第一步是使用AdvGen激怒数据。 我们首先使用变压器根据原始传入要约,目标输入要约和目标输出要约计算转移损失。 然后,AdvGen会根据其均匀分布的假设随机选择原始句子中的单词。 每个单词都有一个类似单词的对应列表,即 替代候选人。 AdvGen从中选择最有可能导致变压器输出错误的词。 然后,此生成的敌对语句将反馈给转换器,从而开始防御阶段。
 首先,将转换模型应用于输入句子(左下),然后将翻译损失与目标输出句子(在上方)和目标输入句子(在右中间,以“ <sos>”开头)一起计算。 然后,AdvGen接受原始句子,单词选择分布,候选单词和翻译损失作为输入,并创建一个对抗性源代码示例。
首先,将转换模型应用于输入句子(左下),然后将翻译损失与目标输出句子(在上方)和目标输入句子(在右中间,以“ <sos>”开头)一起计算。 然后,AdvGen接受原始句子,单词选择分布,候选单词和翻译损失作为输入,并创建一个对抗性源代码示例。在防御阶段,对抗性源代码将反馈给转换器。 再次计算翻译损失,但是这次使用有争议的输入源。 AdvGen使用与以前相同的方法,使用目标输入句子,从注意力矩阵计算出的单词选择分布,候选单词替换和翻译损失来创建有争议的源代码示例。
 在防御阶段,对抗性源代码将成为变压器的输入,并计算翻译损失。 AdvGen使用与之前相同的方法,根据目标输入创建有争议的源代码示例。
在防御阶段,对抗性源代码将成为变压器的输入,并计算翻译损失。 AdvGen使用与之前相同的方法,根据目标输入创建有争议的源代码示例。最后,将对抗语句反馈到转换器,并基于对抗源示例,目标输入的对抗示例和目标语句来计算稳定性损失。 如果文本中的干预导致了重大损失,则将损失降到最低,以便当模型遇到类似的扰动时,她不会重复相同的错误。 另一方面,如果干扰导致较小的损失,则什么也不会发生,这表明该模型已经能够应对此类干扰。
模型表现
我们将其应用于从中文到英语以及从英语到德语的标准翻译测试中,证明了我们方法的有效性。 与变压器的竞争模型相比,我们的翻译量分别显着提高了BLE和2.8个BLEU,并创造了新的翻译质量记录。
 标准测试中变压器模型的比较
标准测试中变压器模型的比较然后,我们使用类似于AdvGen所述的过程,在嘈杂的数据集上评估模型的性能。 我们以纯输入数据为例,例如在翻译人员的标准测试中使用的那些输入数据,并随机选择我们用相似的替换词。 我们发现,与其他最新模型相比,我们的模型显示出更高的稳定性。
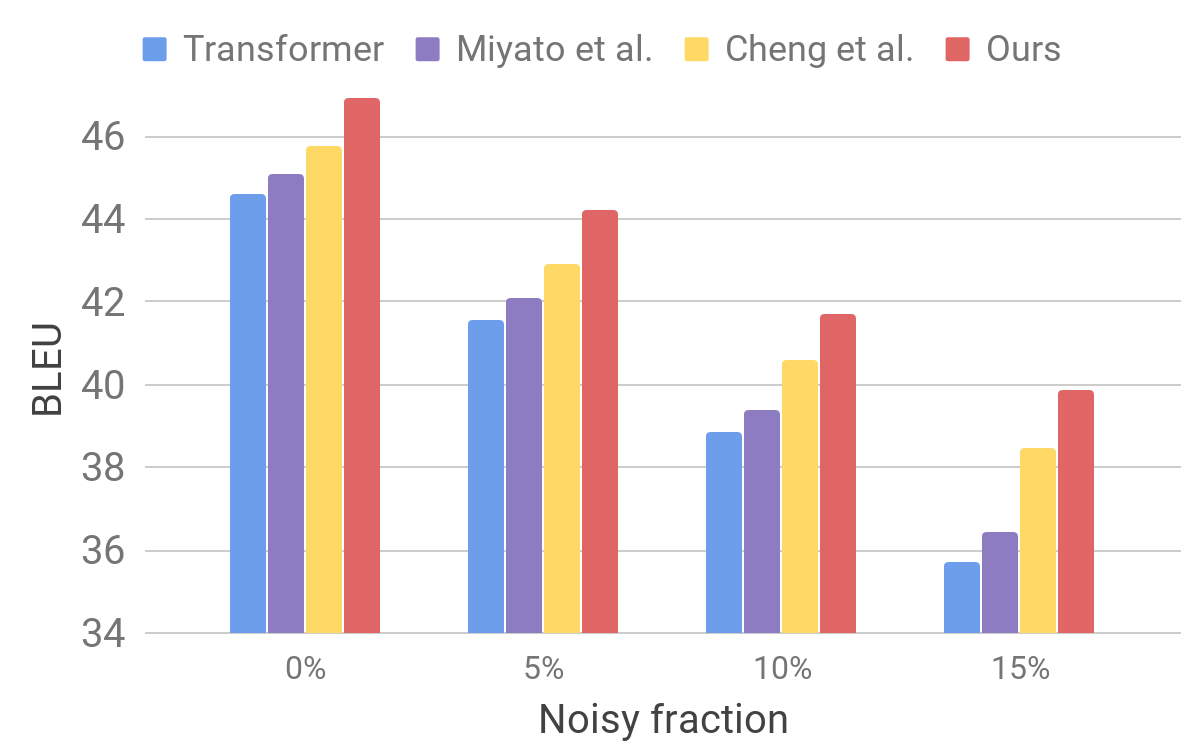 变压器和其他模型在人为噪声输入数据上的比较
变压器和其他模型在人为噪声输入数据上的比较这些结果表明,我们的方法能够克服传入句子中出现的小干扰,并提高泛化效率。 他在竞争性翻译模型方面处于领先地位,并在标准测试中实现了创纪录的翻译效率。 我们希望我们的翻译器模型将成为改善解决以下许多问题的结果的稳定基础,尤其是那些对输入文本不敏感或敏感的问题。