尽管神经网络不久前就开始用于语音合成( 例如 ),但是它们已经成功地超越了传统方法,并且每年他们都会遇到越来越多的任务。
例如,几个月前,通过语音克隆Real-Time-Voice-Cloning实现了语音合成。 让我们尝试弄清它的组成,并实现我们的多语言(俄语-英语)音素模型。
建筑
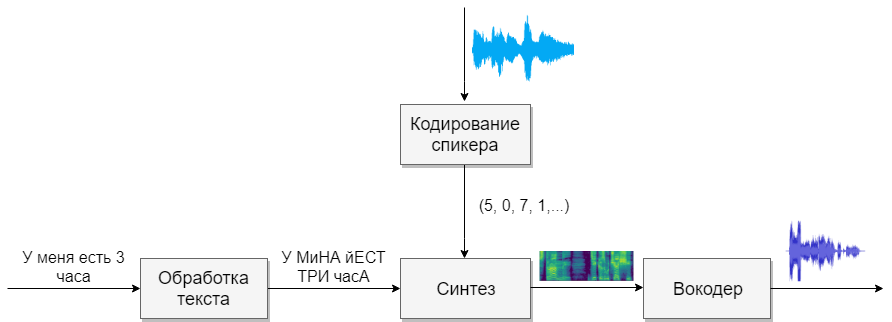
我们的模型将包含四个神经网络。 第一个将文本转换为音素(g2p),第二个将我们要克隆的语音转换为符号矢量(数字)。 第三个将基于前两个的输出来合成梅尔频谱图。 最后,第四个将接收来自频谱图的声音。
数据集
该模型需要大量演讲。 以下是有助于此目的的基础。
文字处理
第一个任务是文本处理。 想象一下将以进一步表达形式的文本。 我们将用数字表示数字,并打开缩写。 在有关综合的文章中阅读更多内容 。 这是一项艰巨的任务,因此假设我们已经处理了文本(已在上面的数据库中处理过)。
下一个要问的问题是使用字形还是音素记录。 对于单音和单语语音,字母模型也适用。 如果您想使用多语音多语言模型,那么我建议您使用转录(也是Google)。
G2p
对于俄语,有一个称为Russian_g2p的实现。 它建立在俄语规则之上,可以很好地处理任务,但是有缺点。 并非所有单词都强调,也不适合多语言模型。 因此,以为她创建的字典为基础,添加英语字典并为神经网络提供数据(例如1,2 )
在训练网络之前,值得考虑一下来自不同语言的声音听起来是否相似,并且可以为它们选择一个字符,而这是不可能的。 声音越多,模型学习起来就越困难,如果声音太少,则模型会带有重音。 记住要用强调的元音强调单个字符。 对于英语来说,次要压力起着很小的作用,我无法区分。
扬声器编码
该网络类似于通过语音识别用户的任务。 在输出处,不同的用户获得带有数字的不同向量。 我建议使用基于本文的CorentinJ本身的实现。 该模型是具有768个节点的三层LSTM,然后是256个神经元的完全连接层,给出了256个数字的向量。
经验表明,受过英语培训的网络可以说俄语。 由于培训需要大量数据,因此这大大简化了生活。 我建议您采用已经受过训练的模型,并从VoxCeleb和LibriSpeech用英语进行再培训,以及发现的所有俄语演讲。 编码器不需要语音片段的文本注释。
培训课程
- 运行
python encoder_preprocess.py <datasets_root>以处理数据 - 在单独的终端中运行“ visdom”。
- 运行
python encoder_train.py my_run <datasets_root>来训练编码器
综合性
让我们继续进行综合。 我知道的模型不能直接从文本中获得声音,因为它很困难(数据太多)。 首先,文本产生频谱形式的声音,然后,第四个网络将转换为熟悉的声音。 因此,我们首先了解频谱形式如何与语音相关联。 更容易找出如何从声音中获取频谱图的反问题。
声音被分为25 ms的段,以10 ms为增量(大多数型号中的默认设置)。 然后,使用每个片段的傅立叶变换,计算频谱(谐波振荡,其总和给出原始信号)并以图形形式显示,其中垂直条带是一个段的频谱(在频率上),水平条带是一段的频谱(在时间上)。 该图称为频谱图。 如果频率是非线性编码的(较低的频率比较高的频率更好),则垂直标度将发生变化(需要减少数据),因此此图称为梅尔频谱图。 这就是人类听力的工作方式,我们在低频处的听觉会比高频处的听觉更好,因此不会受到音质的影响
有几种好的频谱图合成实现,例如Tacotron 2和Deepvoice 3 。 这些模型中的每一个都有其自己的实现,例如1、2、3、4 。 我们将使用(如CorentinJ)Rayhane-mamah的Tacotron模型。
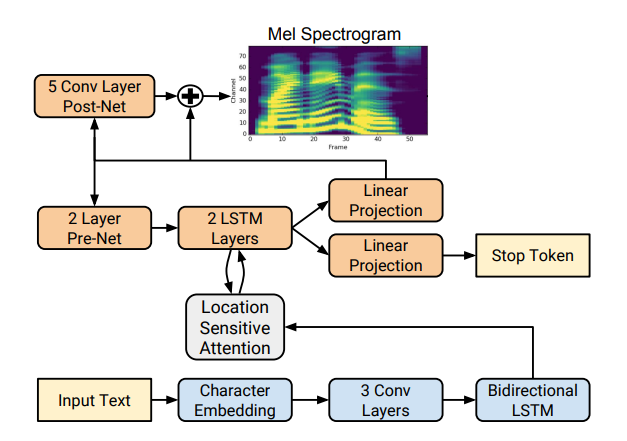
Tacotron基于带有注意机制的seq2seq网络。 阅读文章中的详细信息。
培训课程
如果您不仅合成英语语音hparams.p,还合成preprocess.py,请不要忘记编辑utils / symbols.py。
合成需要来自不同扬声器的大量清晰,标记清晰的声音。 在这里,外语是没有帮助的。
- 运行
python synthesizer_preprocess_audio.py <datasets_root>创建已处理的声音和声谱图 - 运行
python synthesizer_preprocess_embeds.py <datasets_root>对声音进行编码(获取声音符号) - 运行
python synthesizer_train.py my_run <datasets_root>来训练合成器
声码器
现在只剩下将频谱图转换为声音了。 为此,最后一个网络是声码器。 问题是,如果使用傅立叶变换从声音中获得频谱图,是否可以使用逆变换再次获得声音? 答案是肯定的。 组成原始信号的谐波振荡既包含振幅也包含相位,并且我们的频谱图仅包含有关振幅的信息(为了减少参数并使用频谱图),因此,如果执行傅立叶逆变换,则会得到不良声音。
为了解决这个问题,他们发明了一种快速的Griffin-Lim算法。 他对频谱图进行了傅立叶逆变换,得到了一种“不好的”声音。 然后,他直接对该声音进行转换,并接收一个已经包含有关相位的少量信息的频谱,并且振幅在此过程中不会改变。 接下来,再次进行逆变换并获得更清晰的声音。 不幸的是,由这种算法产生的语音质量尚待提高。
它被WaveNet , WaveRNN , WaveGlow等神经语音 编码器所取代。 CorentinJ使用了Fatchord的WaveRNN模型

对于数据预处理,使用两种方法。 要么从声音中获取频谱图(使用傅立叶变换),要么从文本中获取频谱图(使用合成模型)。 Google建议使用第二种方法。
培训课程
- 运行
python vocoder_preprocess.py <datasets_root>合成频谱图 - 运行
python vocoder_train.py <datasets_root>进行声码器
合计
我们获得了可以克隆语音的多语言语音合成模型。
运行工具箱: python demo_toolbox.py -d <datasets_root>
例子可以在这里听到
提示和结论
- 需要大量数据(> 1000票,> 1000小时)
- 仅在合成至少4个句子时,运算速度才与实时相当
- 对于编码器,请使用英语的预训练模型,并稍加重新训练。 她过得很好
- 接受过“干净”数据训练的合成器效果更好,但比接受大量但脏数据训练的合成器效果更差
- 该模型仅对我研究过的数据有效
您可以使用colab在线合成语音,或者在github上查看我的实现并下载我的权重 。