嗨,大家好,Alfastrakhovaniya工程研讨会的日期是“秘密信息”,这激发了我们的技术思维。

Apache Spark是一个很棒的工具,它使您可以在相当适度的计算资源上(我的意思是集群处理)快速轻松地处理大量数据。
传统上,jupyter笔记本用于临时数据处理。 与Spark结合使用,这使我们能够处理长期存在的数据帧(Spark处理资源分配,日期帧位于群集中的某个位置,其生存期受Spark上下文的生存期限制)。
将数据处理转移到Apache Airflow之后,帧的生存时间大大减少-Spark上下文在同一Airflow语句中“存在”。 如何解决这个问题,为什么解决问题以及Livy与它有什么关系-请仔细阅读。
让我们看一个非常非常简单的示例:假设我们需要对大表中的数据进行规范化,然后将结果保存在另一个表中以进行进一步处理(数据处理管道的典型元素)。
我们将如何做:
- 将数据加载到数据框中(从大表和目录中选择)
- 用眼睛看着结果(它是否正常工作)
- 将数据框保存到Hive表(例如)
根据分析结果,我们可能需要在第二步中插入一些特定处理(字典替换或其他操作)。 在逻辑方面,我们分三个步骤
在jupyter笔记本中,这就是我们的工作方式-我们可以任意长时间处理下载的数据,从而控制Spark资源。
逻辑上可以将这样的分区转移到Airflow。 也就是说,拥有这种图形

不幸的是,当使用Airflow + Spark组合时这是不可能的:每个Airflow语句都在其自己的python解释器中执行,因此,除其他外,每个语句都必须以某种方式“持久化”其活动的结果。 因此,我们的处理一步就被“压缩”了,即“非正规化数据”。
如何将Jupyter Notebook的灵活性带回Airflow? 显然,上面的示例“不值得”(相反,也许可以证明这是一个很好的可理解的处理步骤)。 但是,仍然如何-如何使Airflow语句在相同的Spark上下文中在公共数据帧空间上执行?
欢迎丽芙
另一个Hadoop生态系统产品可以抢救-Apache Livy。
我不会在这里描述它是什么“野兽”。 如果非常简短且黑白两色-Livy允许您将python代码“注入”到驱动程序执行的程序中:
- 首先,我们创建一个Livy会话
- 之后,我们可以在此会话中执行任意python代码(非常类似于jupyter / ipython意识形态)
除此之外,还有一个REST API。
回到简单的任务:使用Livy,我们可以保存非规范化的原始逻辑
- 在第一步(图的第一条语句)中,我们将加载并执行数据框中的数据加载代码
- 在第二步(第二条语句)中-执行代码以对此数据帧进行必要的附加处理
- 在第三步中-将数据框保存到表中的代码
在气流方面可能如下所示:
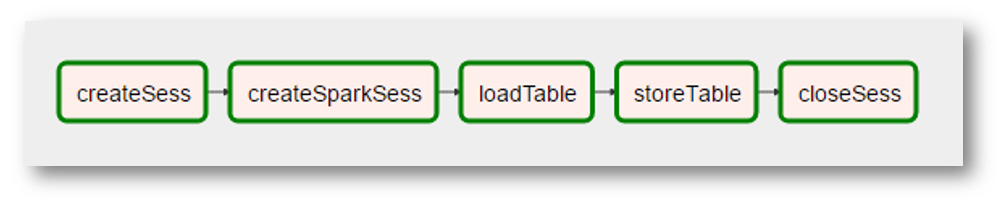
(由于图片是非常真实的屏幕截图,因此添加了其他“现实”-创建Spark上下文成为一个具有奇怪名称的单独操作,由于不需要数据,对数据的“处理”消失了,等等)。
总而言之,我们得到
- 在Livy会话中执行python代码的通用气流语句
- 能够将python代码“组织”成相当复杂的图形(为此目的是Airflow)
- 解决更高级别优化的能力,例如,我们需要按什么顺序执行转换,以便Spark可以将常规数据保留在群集内存中的时间尽可能长
用于准备建模数据的典型管道包含对10个表的大约25个查询,很明显,某些表的使用频率比其他表高(非常“常见的数据”),并且存在一些需要优化的地方。
接下来是什么
我们进一步思考了技术能力,这是如何进行技术转换将其转变为这种范例的测试。 以及如何进行上述优化。 我们仍处于旅程的开始–当有有趣的事情时,我们一定会分享的。