
2017年,我们赢得了发展阿尔法银行投资业务交易核心的竞争并开始工作(在HighLoad ++ 2018上
,阿尔法银行投资业务交易核心主管Vladimir Drynkin提交了有关投资业务核心的报告)。 该系统用于汇总来自各种来源的各种格式的交易数据,将数据统一化,保存并提供对它们的访问。
在开发过程中,该系统不断发展并开始运行,在某个时刻,我们意识到,我们不仅在设计要解决严格定义的任务的应用程序软件方面,还使我们进一步结晶:我们得到了一个
用于构建具有以下功能的分布式应用程序的
系统 :
持久存储 。 我们的经验构成了新产品
Tarantool Data Grid (TDG)的基础。
我想谈谈在开发过程中提出的TDG架构和解决方案,向您介绍基本功能,并说明我们的产品如何成为构建完整解决方案的基础。
在体系结构上,我们将系统划分为单独的
角色 ,每个
角色负责解决特定范围的任务。 应用程序的一个正在运行的实例实现一种或多种类型的角色。 集群可以具有多个相同类型的角色:
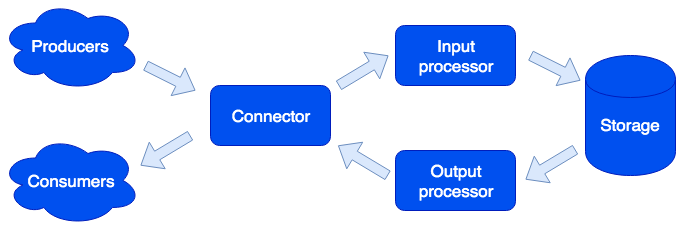
连接器
连接器负责与外界的交流; 它的任务是接受请求,解析请求,如果请求成功,则将数据发送给输入处理器进行处理。 我们支持HTTP,SOAP,Kafka,FIX等格式。 该体系结构使您可以简单地添加对新格式的支持,IBM MQ支持即将推出。 如果请求解析失败,则连接器将返回错误;否则,连接器将返回错误。 否则,他将答复该请求已成功处理,即使在进一步处理期间发生错误也是如此。 这样做是有目的的,以便与不知道如何重复请求的系统一起使用(反之亦然),请过分积极地进行。 为了不丢失数据,使用了一个修复队列:对象首先进入它,并且只有在成功处理后才将其删除。 管理员可以收到有关修复队列中剩余对象的通知,并且在消除软件错误或硬件故障后,请重试。
输入处理器
输入处理器按特性对接收到的数据进行分类,并调用适当的处理程序。 处理程序是在沙箱中运行的Lua代码,因此它们不会影响系统的功能。 在此阶段,可以将数据简化为所需的格式,并且如果有必要,可以运行任意数量的可以实现必要逻辑的任务。 例如,在基于Tarantool数据网格的MDM(主数据管理)产品中,添加新用户时,我们运行单独的任务,以免减慢请求的处理速度。 沙盒支持读取,更改和添加数据的请求;它允许您在所有角色上执行某些功能,例如存储并汇总结果(映射/缩小)。
处理程序可以在文件中描述:
sum.lua local x, y = unpack(...) return x + y
然后,在配置中声明:
functions: sum: { __file: sum.lua }
为什么是卢阿? Lua是一种非常简单的语言。 根据我们的经验,在与他见面几个小时后,人们开始编写解决问题的代码。 这些不仅是专业开发人员,而且还包括分析师。 另外,由于使用了jit编译器,Lua非常快。
贮藏
存储器存储持久性数据。 保存之前,将验证数据是否符合数据模式。 为了描述该方案,我们使用扩展的
Apache Avro格式。 一个例子:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string"}, {"name": "first_name", "type": "string"}, {"name": "last_name", "type": "string"} ], "indexes": ["id"] }
基于此描述,将自动生成用于Tarantula DBMS的DDL(数据定义语言)和用于数据访问的
GraphQL模式。
支持异步数据复制(计划添加同步)。
输出处理器
有时有必要通知外部使用者新数据的到来,因为这有输出处理器的作用。 保存数据后,可以将它们传输到适当的处理程序(例如,将其转换为使用者所需的格式),然后将其传输到连接器以进行发送。 修复队列也在这里使用:如果没有人接受该对象,则管理员可以稍后重试。
缩放比例
连接器,输入处理器和输出处理器的角色是无状态的,这使我们能够水平扩展系统,只需添加具有所需类型角色的应用程序新实例即可。 对于水平存储扩展,使用了
一种使用虚拟存储桶进行集群组织的
方法 。 添加新服务器后,后台旧服务器中的部分存储区将移至新服务器; 这对用户是透明的,并且不会影响整个系统的运行。
资料属性
对象可以很大,并且可以包含其他对象。 我们确保添加和更新数据的原子性,将对象以及所有依赖项保存在一个虚拟存储桶中。 这消除了跨多个物理服务器的对象“拖影”。
支持版本控制:对象的每次更新都会创建一个新版本,我们总是可以制作一个时间片,然后观察一下整个世界。 对于不需要很长历史记录的数据,我们可以限制版本数,甚至可以只存储一个-最后一个-也就是说,实际上禁用某种类型的版本控制。 您还可以按时间限制历史记录:例如,删除某个类型超过1年的所有对象。 还支持归档:我们可以卸载早于指定时间的对象,从而释放集群中的空间。
任务
在有趣的功能中,值得注意的是能够根据用户的请求或从沙箱以编程方式运行任务的功能:

在这里,我们看到了另一个角色-跑步者。 该角色没有状态,并且如有必要,可以将其他具有该角色的应用程序实例添加到群集中。 跑步者的责任是完成任务。 如上所述,可以从沙箱中创建新任务。 它们在存储中排队,然后在运行器上运行。 这种任务称为Job。 我们还有一种称为任务的任务-这些任务是用户定义的任务,已计划运行(使用cron语法)或按需运行。 为了运行和跟踪此类任务,我们有一个方便的任务管理器。 为了使此功能可用,您必须启用调度程序角色。 该角色具有状态,因此不会扩展,但这不是必需的; 但是,与其他所有角色一样,她可能拥有一个副本,如果主人突然拒绝,副本可以开始工作。
记录仪
另一个角色称为记录器。 它从所有群集成员收集日志,并提供一个用于通过Web界面上传和查看日志的界面。
服务项目
值得一提的是,该系统使创建服务变得容易。 在配置文件中,您可以指定应将哪些请求发送到在沙箱中运行的用户编写的处理程序。 在此处理程序中,您可以例如执行某种分析查询并返回结果。
该服务在配置文件中描述:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
GraphQL API是自动生成的,并且该服务可用于调用:
query { sum(x: 1, y: 2) }
这将调用
sum处理程序,它将返回结果:
3
查询分析和指标
为了了解系统和查询分析,我们实现了对OpenTracing协议的支持。 系统可以根据需要将信息发送到支持该协议的工具,例如Zipkin,这将使您了解如何执行请求:
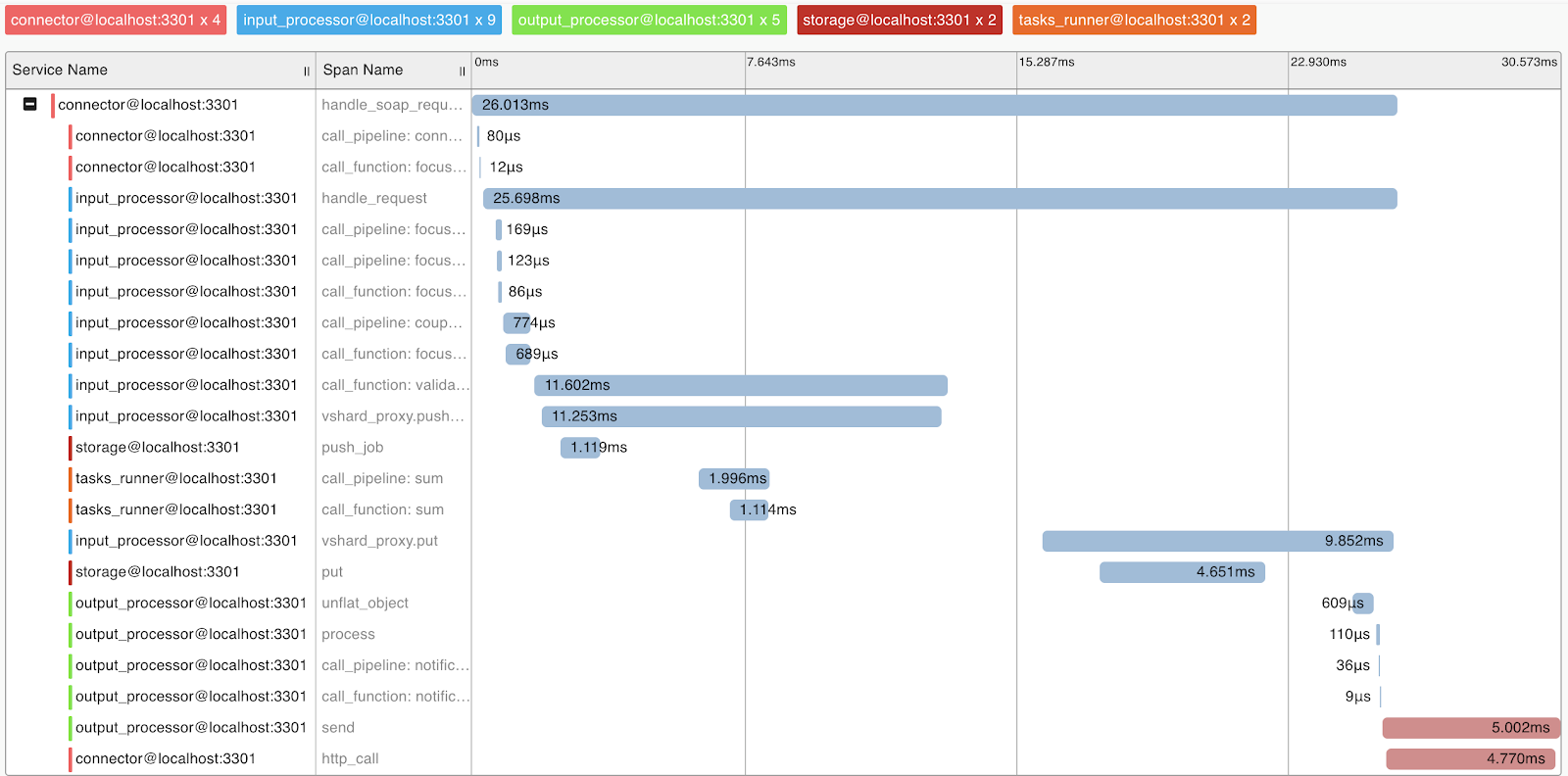
自然,该系统提供了内部指标,可以使用Prometheus进行收集并使用Grafana进行可视化。
部署
可以使用RPM软件包或存档中的Tarantool Data Grid进行部署,使用交付或Ansible中的实用程序,还支持Kubernetes(
Tarantool Kubernetes Operator )。
通过UI或通过我们提供的API使用脚本,将实现业务逻辑(配置,处理程序)的应用程序作为存档加载到Tarantool数据网格集群中。
应用实例
我可以使用Tarantool数据网格创建哪些应用程序? 实际上,大多数业务任务都以某种方式与处理数据流,存储和访问它有关。 因此,如果您有大量数据流需要安全地存储并可以访问它们,那么我们的产品可以为您节省大量开发时间,并专注于您的业务逻辑。
例如,我们想要收集有关房地产市场的信息,以便随后获得例如最佳交易的信息。 在这种情况下,我们区分以下任务:
- 机器人从开源收集信息-这些将成为我们的数据源。 您可以使用现成的解决方案或以任何语言编写代码来解决此问题。
- 接下来,Tarantool数据网格将接受并保存数据。 如果来自不同来源的数据格式不同,则可以用Lua语言编写代码,这将导致转换为单一格式。 在预处理阶段,例如,您还可以过滤重复报价或在数据库中另外更新有关市场上运营的代理商的信息。
- 现在,您已经在集群中有了一个可伸缩的解决方案,可以在其中填充数据并制作数据样本。 然后,您可以实现新功能,例如,编写将查询数据并发布一天中最赚钱的要约的服务-这将需要在配置文件中包含几行内容以及一些Lua代码。
接下来是什么?
我们的首要任务是使用
Tarantool数据网格增加开发的便利性。 例如,这是一个支持概要分析和调试沙盒处理程序的IDE。
我们也非常注意安全问题。 目前,我们正在通过FSTEC俄罗斯认证,以确认其高度安全性并满足个人数据信息系统和国家信息系统中使用的软件产品认证的要求。