ClickHouse经常遇到字符串处理任务。 例如,无论是区分大小写的搜索还是压缩的数据搜索,都进行搜索,计算UTF-8字符串的属性或其他更奇特的内容。
一切始于ClickHouse开发经理Lesha Milovidov o6CuFl2Q来到我们的经济学院计算机科学系,并为学期论文和文凭提供了大量主题。 当我看到“ ClickHouse中的智能字符串处理算法”(我是一个对各种算法(包括实验算法)感兴趣的人)时,我立即制定了如何制作最酷文凭的计划。 我的喜悦和表情可以描述如下:

Clickhouse
ClickHouse仔细考虑了内存中数据存储的组织方式-按列。 每列的末尾都有15字节的填充,用于安全读取16字节的寄存器。 例如,ColumnString存储以null结尾的字符串以及偏移量。 使用此类数组非常方便。

也有ColumnFixedString,ColumnConst和LowCardinality,但是我们今天不再详细讨论它们。 此时的重点是,安全读取尾巴的设计非常漂亮,并且数据的局部性在处理中也起作用。
子串搜索
您很可能知道用于在字符串中查找子字符串的许多不同算法。 我们将讨论ClickHouse中使用的那些。 首先,我们介绍几个定义:
- 干草堆-我们正在寻找的线; 通常,长度用n表示。
- 针-我们正在寻找的字符串或正则表达式; 长度将由m表示。
在研究了大量算法之后,我可以说有2种(最多3种)子串搜索算法。 首先是以一种或另一种形式创建后缀结构。 第二种是基于内存比较的算法。 还有Rabin-Karp算法,该算法使用哈希,但是在同类算法中非常独特。 最快的算法并不存在,这完全取决于字母的大小,针的长度,干草堆和出现的频率。
在此处了解不同的算法。 以下是最受欢迎的算法:
- 纳特-莫里斯-普拉特,
- 博耶-摩尔,
- 博耶-摩尔-霍斯浦,
- 拉宾-鲤鱼,
- 双面(在glibc中使用,称为“ memmem”),
- BNDM
清单继续。 我们在ClickHouse诚实地尝试了所有内容,但最终我们选择了一个更加出色的版本。
Volnitsky算法
该算法于2010年末发布在程序员Leonid Volnitsky的博客上 。 它在某种程度上让人联想到Boyer-Moore-Horspool算法,只是一个改进版本。
如果m <4 ,则使用标准搜索算法。 从头将所有双字(2个连续字节)的指针保存到哈希表中,并以开放地址寻址| Sigma | 2个元素(实际上是2 16个元素),其中此bigram的偏移量将是值,而bigram本身将同时是哈希和索引。 初始位置将从干草堆开始处的位置m-2处。 我们在haystack之后执行步骤m-1 ,从干草堆中的该位置查看下一个bigram,并考虑哈希表中bigram的所有值。 然后,我们将使用常规比较算法比较两个内存。 剩下的尾巴将由相同的算法处理。
选择步骤m-1的方式是,如果大海捞针中出现针刺,那么我们肯定会考虑该条目的二元组-从而确保我们返回大海捞针中条目的位置。 我们通过bigram从末尾向哈希表添加索引这一事实保证了第一次出现。 这意味着,当我们从左到右移动时,我们将首先从行尾开始考虑二元组(也许最初考虑的是完全不必要的二元组),然后再接近起点。
考虑一个例子。 令干草堆为abacabaac和等于aaca针。 哈希表将为{aa : 0, ac : 1, ca : 2} 。
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
我们看到了二元组ac 。 从本质上讲,我们用平等代替:
0 1 2 3 4 5 6 7 8 9 abacabaaca aaca
不匹配。 在ac之后,哈希表中没有任何条目,我们进入步骤3:
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
哈希表中没有bigrams ba ,继续:
0 1 2 3 4 5 6 7 8 9 abacabaaca ^ -
针中有一个bigram ca ,我们查看偏移量并找到条目:
0 1 2 3 4 5 6 7 8 9 abacabaaca aaca
该算法具有许多优点。 首先,您不需要在堆上分配内存,并且堆栈上的64 KB现在已经不是先验的了。 其次,2 16是对处理器取模的极好数字。 这些只是movzwl指令(或者,我们开玩笑说是“ movsvl”)和家人。
平均而言,该算法被证明是最好的。 我们从Yandex.Metrica中获取数据,这些请求几乎是真实的。 一股流速度,越多越好,KMP:Knut-Morris-Pratt算法,BM:Boyer-Moore,BMH:Boyer-Moore-Horspool。
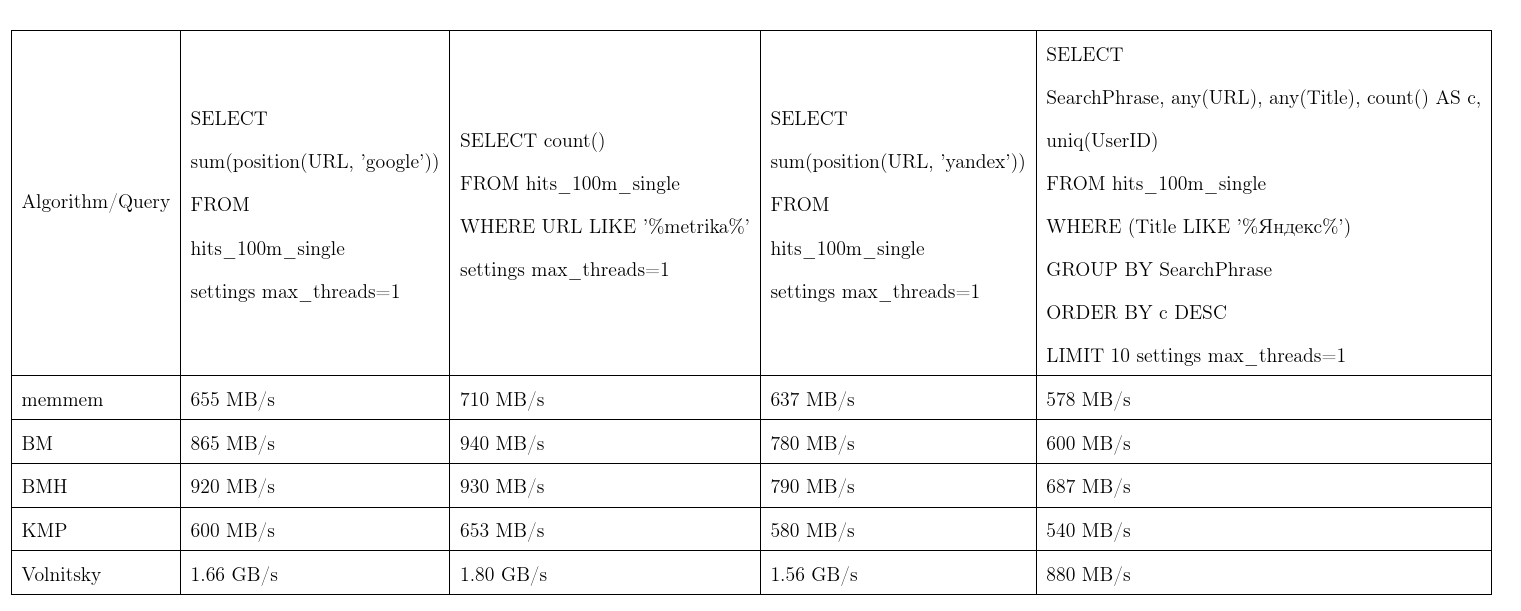
为了不成立,该算法可以工作二次时间:

它用在position(Column, ConstNeedle)函数position(Column, ConstNeedle) ,还用作正则表达式搜索的优化。
正则表达式搜索
我们将告诉您ClickHouse如何优化正则表达式搜索。 许多正则表达式内部都包含一个子字符串,该子字符串必须在干草堆内部。 为了不构建有限状态机并进行检查,我们将隔离这些子字符串。
要做到这一点很简单:任何打开的括号都会增加嵌套的水平,任何关闭的括号都会减少; 还有一些特定于正则表达式的字符(例如'。','*','?','\ w'等)。 我们需要在级别0处获取所有子字符串。请考虑一个示例:
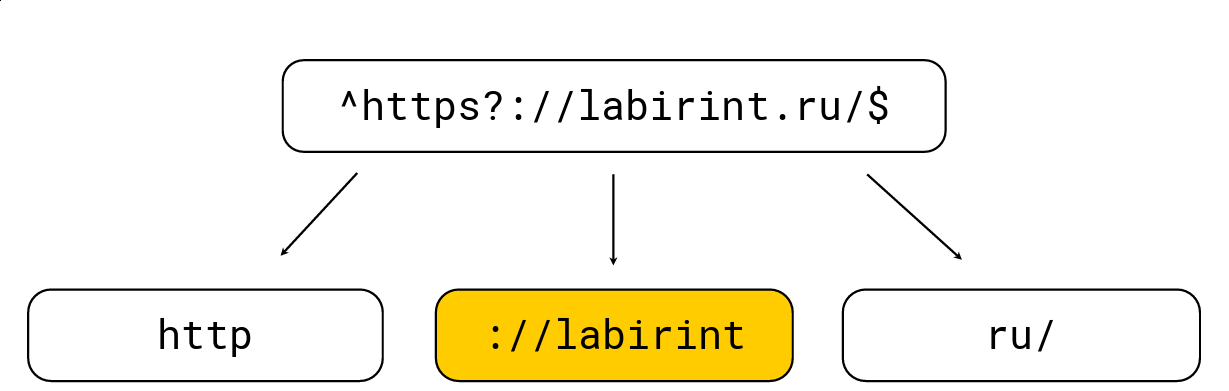
我们将其分为正则表达式必须位于干草堆中的那些子字符串,然后选择最大长度,在其上寻找候选对象,然后使用常规正则表达式引擎RE2进行检查。 在上面的图片中,有一个正则表达式,它由常规的RE2引擎以736 MB / s的速度处理,Hyperscan(稍后介绍)管理到1.6 GB / s,我们每个内核管理1.69 GB / s的压缩以及解压缩。 LZ4。 通常,这种优化是表面上的,它极大地加快了对正则表达式的搜索,但是通常它并未在工具中实现,这使我感到惊讶。
LIKE关键字也使用此算法进行了优化,只有在LIKE之后,非常简化的正则表达式才能通过%%%%%(任意子字符串)和_ (任意字符)。
不幸的是,并非所有的正则表达式都经过这样的优化,例如,从yandex|google ,不可能显式提取必须在干草堆中出现的子字符串。 因此,我们提出了一个完全不同的解决方案。
搜索许多子字符串
问题是有很多针头,我想了解一下大海捞针中是否至少包括一根针头。 有相当经典的搜索方法,例如Aho-Korasik算法。 但是他并不太快完成我们的任务。 我们稍后再讨论。
乐莎 ClickHouse喜欢非标准解决方案,因此我们决定尝试不同的方法,也许我们自己制定一种新的搜索算法。 他们做到了。
我们研究了Volnitsky算法并对其进行了修改,以使其开始立即搜索许多子字符串。 为此,您只需要添加所有行的二元组并将行索引存储在哈希表中。 该步长将至少从所有针长减去1中进行选择,以再次保证该属性,如果出现这种情况,我们将看到其二字组。 哈希表将增长到128 KB(标准算法处理的行长超过255,我们将考虑不超过256个针)。 我很懒,所以这是演示文稿中的一个示例(从左到右,从上到下阅读):


我们开始研究这种算法与其他算法相比的行为(行是从真实数据中提取的)。 对于少量的线路,他可以完成所有工作(指示速度和卸载速度-约2.5 GB / s)。
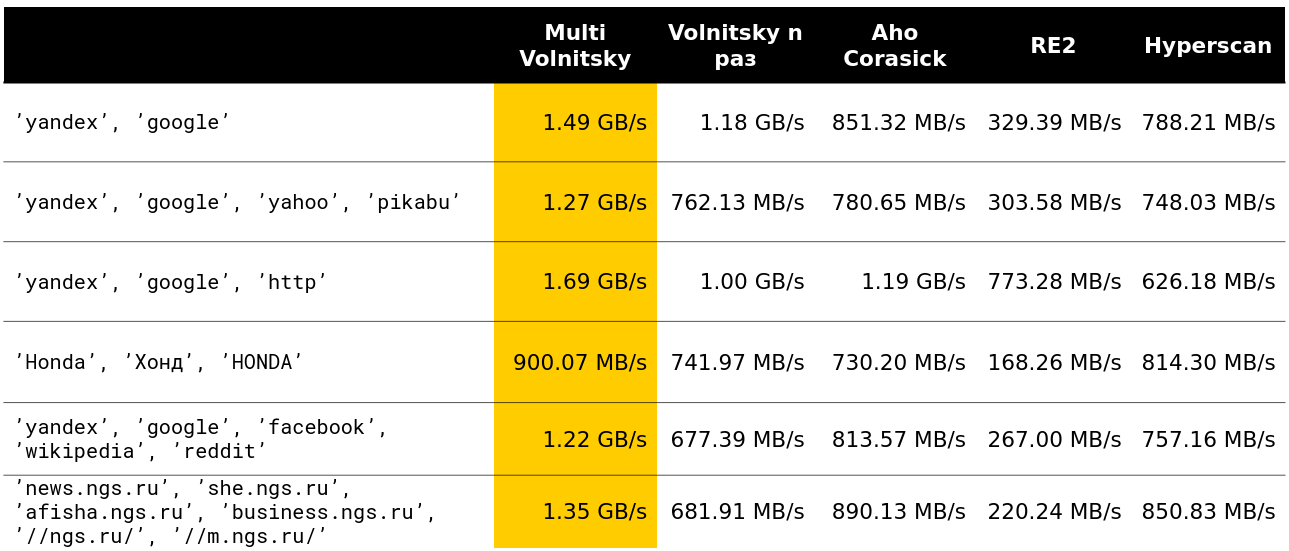
然后变得有趣。 例如,在大量类似的二元组中,我们输给了一些竞争对手。 这是可以理解的-我们开始比较许多内存并进行降级。

如果针的最小长度足够大,您将无法加速。 显然,我们有更多机会跳过整个草堆而无需为此付出任何代价。

引爆点开始于第13-15行。 我在集群上看到的请求中约有97%少于15行:
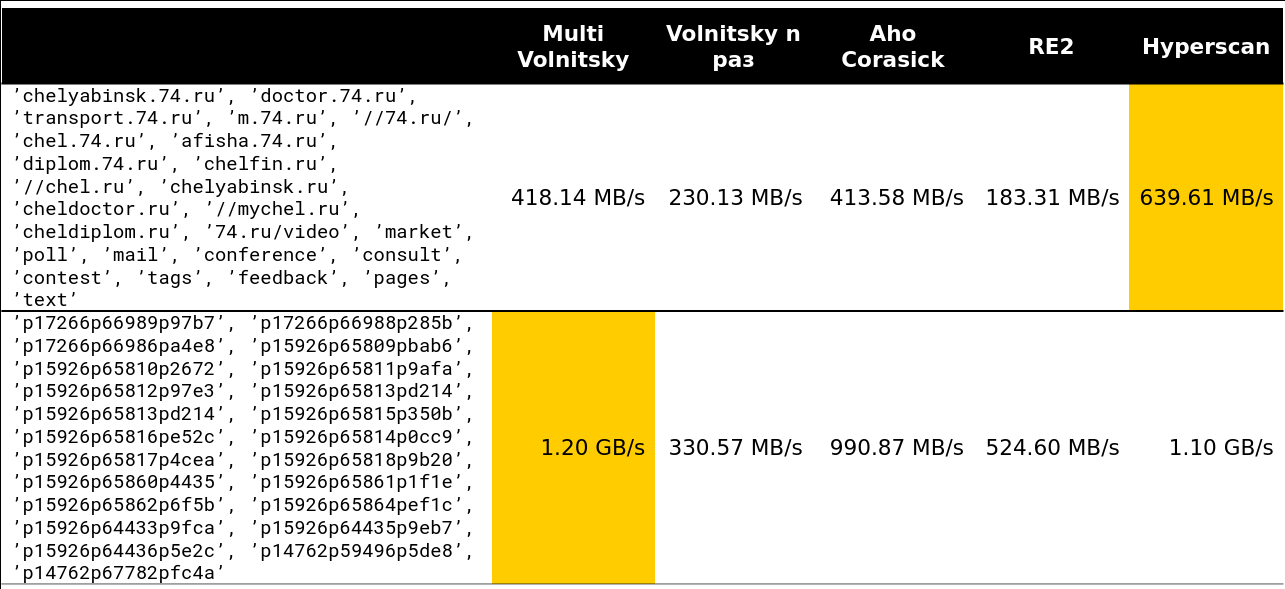
好吧,一张非常可怕的图片-41行,许多重复的二元组:

结果,在ClickHouse(19.5)中,我们通过此算法实现了以下功能:
multiSearchAny(h, [n_1, ..., n_k]) -1,如果至少一根针在干草堆中。
multiSearchFirstPosition(h, [n_1, ..., n_k]) -进入干草堆的最左侧位置(从1开始);如果找不到,则为0。
multiSearchFirstIndex(h, [n_1, ..., n_k]) -最左侧的针索引,在干草堆中找到; 0(如果未找到)。
multiSearchAllPositions(h, [n_1, ..., n_k]) -所有针的所有第一位置,均返回一个数组。
后缀为-UTF8(我们不进行规范化),-CaseInsensitive(我们添加4个大小写不同的双字),-CaseInsensitiveUTF8(存在一个条件,即大写字母和小写字母必须具有相同的字节数)。 在此处查看实现。
之后,我们想知道是否可以对许多正则表达式执行类似的操作。 他们找到了基准中已经损坏的解决方案。
通过许多正则表达式进行搜索
Hyperscan是Intel的一个库,可立即搜索许多正则表达式。 它使用启发式方法将子词与我们编写的正则表达式隔离开来,并使用许多SIMD搜索Glushkov自动机(该算法似乎称为Teddy)。
通常,一切都遵循最佳传统,即从正则表达式的搜索中获得最大收益。 该库确实执行其函数中声明的操作。

幸运的是,在ClickHouse的一个月的开发工作中,我能够在相当不错的查询水平上超过12年的开发工作,对此我感到非常满意。
在Yandex中,Hyperscan库也用于反垃圾邮件。 从评论来看,她冷静地处理了数千个正则表达式并快速搜索它们。
该库有几个缺点。 首先是未记录的内存消耗量,这是一个奇怪的功能,即干草堆必须小于2 32字节。 第二个-您无法免费返回第一个位置,最左边的针索引等。第三个-则有一些错误 。 因此,在ClickHouse,我们使用Hyperscan实现了以下功能:
multiMatchAny(h, [n_1, ..., n_k]) -1,如果至少一根针从干草堆中冒出来。
multiMatchAnyIndex(h, [n_1, ..., n_k]) -针multiMatchAnyIndex(h, [n_1, ..., n_k])干草堆multiMatchAnyIndex(h, [n_1, ..., n_k])任何索引。
我们很感兴趣,但是您怎么能不精确地而是近似地搜索呢? 并提出了几种解决方案。
近似搜索
近似搜索中的标准是Levenshtein距离-可以替换,添加和删除以从长度为m的字符串a获得长度为n的字符串b的最小字符数。 不幸的是,朴素的动态规划算法适用于O(mn) ; ShAD最好的头脑可以做到O(mn / log max(n,m)) ; 很容易想到O((n + m)⋅alpha) ,其中alpha是答案; 科学可以针对O((alpha-| n-m |)min(m,n,alpha)+ m + n) (算法很简单,至少要在ShAD中读取)做到这一点,或者如果更清晰一点,可以针对O(alpha ^ 2 + m + n) 。 还有一个缺点:在多项式最坏的情况下,摆脱二次时间是最不可能的-彼得·英迪克(Peter Indik)撰写了一篇非常有力的文章 。
有一个练习:想象一下,要替换Levenshtein距离中的一个字符,您要支付的罚款不是2个而是2个。 然后提出O((n + m)log(n + m))的算法 。
它仍然无法正常运行,时间太长且价格昂贵。 但是借助这样的距离,我们在查询中进行了错别字检测。
除了Levenshtein距离外,还有汉明距离。 和他在一起,一切都还不错,但是比Levenshtein的距离要好一些。 它不考虑字符的删除,而是仅考虑长度相同的两行不同字符的数量。 因此,如果我们将距离用于长度为m <n的字符串,则仅在搜索最接近的子字符串时使用。
对于O(| Sigma |(n + m)log(n + m),如何计算这样的差异数组(n-m + 1个元素的数组d,其中d [i]是从叠加层开始的第i个不同字符的数量) ) ? 首先,做| Sigma | 指示此符号是否等于所考虑符号的位掩码。 接下来,我们为每个Sigma蒙版计算答案并加-得到原始答案。
考虑一个例子。 abba ,substring ba ,二进制字母。 我们得到2个蒙版1001, 01和0110, 10 。
a 1001 01 - 0 01 - 0 01 - 1
b 0110 10 - 0 10 - 1 10 - 1
我们得到数组[0,1,2]-这几乎是正确的答案。 但是请注意,对于每个字母,匹配的数目只是固定的二进制指针与所有干草堆子字符串的标量积。 为此,当然有一个快速的傅立叶变换!
对于那些不知道的人:FFT可以在时间O(n log n)中将m <n的两个多项式相乘,前提是每单位时间执行系数运算。 卷积与标量积非常相似。 复制第一个多项式的系数,然后用所需的零数目扩展和补充第二个多项式就足够了,然后我们得到一个二进制字符串的所有标量乘积和另一个二进制字符串的所有子字符串的标量乘积O(n log n) -有点神奇! 但是请相信我,这是绝对真实的,有时人们会这样做。
但不在ClickHouse中。 对我们来说,与| Sigma | = 30已经很大,并且FFT并不是处理器最实用的实用算法,或者像普通人所说的那样,“常数很大”。
因此,我们决定考虑其他指标。 我们到了生物信息学,人们使用n克距离。 实际上,我们将所有n-gram的干草堆和needle都考虑在内,并考虑这些n-gram的2个多集。 然后,我们取对称差,并用n元语法除以两个多重集的基数之和。 我们得到一个从0到1的数字-越接近0,线条越相似。 考虑一个n = 4的示例:
abcda → {abcd, bcda}; Size = 2 bcdab → {bcda, cdab}; Size = 2 . |{abcd, cdab}| / (2 + 2) = 0.5
结果,我们之间的距离为4克,并从那里的SSE那里扎了很多想法,并且还稍微削弱了对双字节crc32哈希的实现。
检查实施 。 注意:非常引人注目的优化代码。
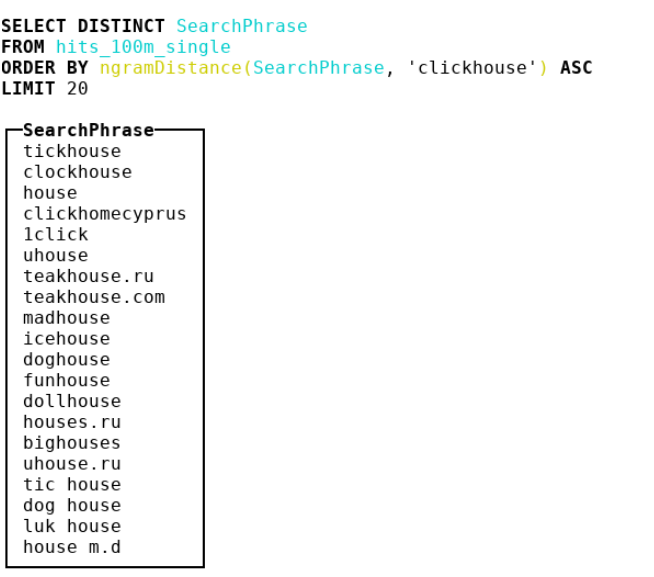
我特别建议您注意为ASCII和俄语代码点转换小写字母的肮脏技巧 。
ngramDistance(haystack, needle) -返回从0到1的数字; 越接近0,则越多的行彼此相似。
--UTF8,-CaseInsensitive,-CaseInsensitiveUTF8(俄语和ASCII的肮脏hack)。
Hyperscan也不会停滞不前-它具有近似搜索功能:通过Levenshtein的恒定距离,您可以搜索看起来像正则表达式的行。 创建距离+ 1自动机,通过删除,替换或插入字符(表示“精细”)将其互连,然后应用检查自动机是否接受特定行的常用算法。 在ClickHouse中,我们以以下名称实现了它们:
multiFuzzyMatchAny(haystack, distance, [n_1, ..., n_k]) -与multiMatchAny类似,仅具有距离。
multiFuzzyMatchAnyIndex(haystack, distance, [n_1, ..., n_k]) -与multiMatchAnyIndex类似,仅具有距离。
随着距离的增加,速度开始大大降低,但仍保持在相当不错的水平。
完成搜索并开始处理UTF-8字符串。 还有很多有趣的事情。
UTF-8线处理
我承认,要突破UTF-8编码字符串的幼稚实现的上限是很困难的。 拧紧SIMD特别困难。 我将分享一些有关如何执行此操作的想法。
回想一下有效的UTF-8序列是什么样的:
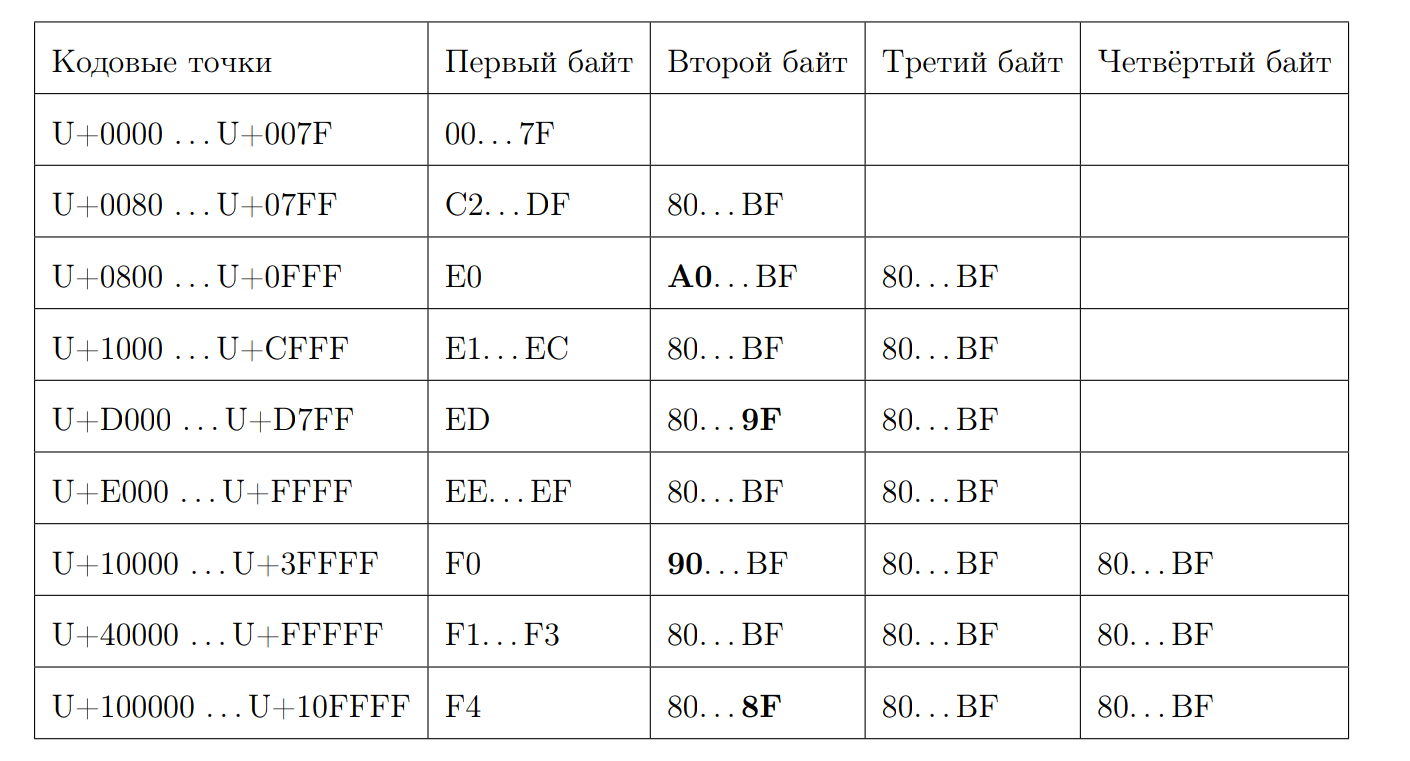
让我们尝试通过第一个字节来计算代码点的长度。 这是位魔术开始的地方。 再次,我们写一些属性:
-从0xC 和0xD开始有2个字节
-0xC2 = 11 0 00010
-0xDF = 11 0 11111
-0xE0 = 111 0 0000
-0xF4 = 1111 0 100,除了0xF4之外,没有别的,但是如果有0xF8,则情况会有所不同
-如果不是ASCII字符,则回答7减去结尾处第一个零的位置
我们计算长度:
inline size_t seqLength(const UInt8 first_octet) { if (first_octet < 0x80u) return 1; const auto first_zero = bitScanReverse(static_cast<UInt8>(~first_octet)); return 7 - first_zero; }
幸运的是,我们有可用的指令,可以从最高有效位开始计算零位的数量。
f = __builtin_clz(val)
计算bitScanReverse:
unsigned int bitScanReverse(unsigned int x) { return 31 - __builtin_clz(x); }
让我们尝试通过SIMD通过代码点计算UTF-8字符串的长度。 为此,将每个字节视为带符号的数字,并注意以下属性:
-0xBF = -65
-0x80 = -128
-0xC2 = -62
-0x7F = 127
-所有的第一个字节都在[0xC2,0x7F]中
-所有非首字节均位于[0x80,0xBF]中
该算法非常简单。 将每个字节与-65进行比较,如果大于此数字,则加1。 如果要使用SIMD,则通常是输入流中16字节的负载。 然后是一个字节比较,如果结果为正,则为字节0xFF,如果结果为负,则为0x00。 然后是pmovmskb指令,它将收集寄存器每个字节的高位。 然后下划线的数量增加,我们将内部函数用于popcnt SSE4指令。 该算法的方案可以通过一个例子说明:

事实证明,随着解压缩,每个内核的处理速度约为1.5 GB / s。
这些函数称为:
lengthUTF8(string) -返回正确编码的UTF-8字符串的长度,某些东西被认为是无效的,不会引发异常。
我们走得更远,因为我们希望通过UTF-8字符串处理获得更多功能。 例如,检查有效性并转换为有效的UTF-8表达式。
为了检查有效性,我采用了https://github.com/cyb70289/utf8/ ,它适用于ClickHouse(实际上只是改变了尾部的处理),并且获得了1.22 GB / s的速度,而朴素算法的速度为900 MB / s。 。 我不会描述算法本身,它对于感知来说相当复杂。
isValidUTF8(string) -如果字符串已使用UTF-8正确编码,则返回1,否则返回0。
toValidUTF8(string) -用 (U + FFFD)字符替换无效的UTF-8字符。 所有连续的无效字符都折叠为一个替换字符。 没有火箭科学。
通常,在UTF-8线路中,由于静态方案不太理想,因此总是很难提出经过优化的方案。
接下来是什么?
让我提醒您,这是我的论文。 当然,我为她辩护10/10。 我们已经和她一起去了Highload ++ Siberia(尽管在我看来,她对任何人都没什么兴趣)。 观看演示 。 我喜欢论文的实践部分导致了很多有趣的研究。 这就是文凭本身。 它有很多错别字,因为没人读。 :)
作为准备文凭的一部分,我做了很多其他类似的工作(链接导致合并请求):
- 优化的concat功能2倍 ;
- 制作最简单的python格式的请求 ;
-LZ4加速了4% ;
- 我在ARM和PPC64LE的SIMD方面做得很好 ;
-他还为一些FCS的学生提供了ClickHouse文凭的建议。
最后,根据我的经验, 勒莎每个月都想念我 ClickHouse是用于编写高性能代码的最令人愉悦的系统,其中提供文档,注释,出色的开发人员和devops支持。 ClickHouse确实很棒。 厌倦了转换JSON格式? 来Lesha询问任何级别的任务-他将为您提供该任务,并且在周末,您将从编写代码中获得极大的乐趣。
但是,随着ClickHouse及其设计的所有成就,可能与他们无关。 不主要在他们。
我在FCS经历了4年的本科学习,6月以优异的成绩从HSE毕业,在Yandex一支很棒的团队工作了一年半,表现出色。 一直没有经验 和铁 帖子中写的任何内容都行不通。 如果您从中获取最大收益,那么FCN非常酷。 感谢Vana Puzyrevsky ivan_puzyrevskiy ,Ignat Kolesnichenko,Gleb Evstropov,Max Babenko maxim_babenko参加了我在FCN上的有趣冒险。 同时还要感谢所有教给我一些知识的老师。