你好 X5 Retail Group的互联大数据临时分析团队。
在本文中,我们将讨论我们的A / B测试方法以及我们每天面临的挑战。
大数据X5拥有大约200名员工,其中包括70名科学家日期和分析师日期。 我们的主要业务是从事特定产品-需求,分类,促销活动等。 除了他们,还有我们独立的临时分析团队。
我们是:
- 我们帮助业务部门处理不适合现有产品的数据分析请求;
- 如果产品团队需要更多的帮助,我们会提供帮助;
- 我们从事A / B测试-这是团队的主要职能。
我们工作的情况与典型的A / B测试有很大不同。 通常,该技术与在线和在线指标相关:更改如何影响转化,保留率,点击率等。 大多数实验都与界面更改有关:重新布置横幅,重新粉刷按钮,替换文本等。
X5的业务有所不同-它是遍布全国的15,000家各种格式的离线商店。 此功能强加了某些限制。 首先,可以测试的一组指标变化很大,其次,对实验施加了限制。 就人工而言,更改在线商店店面设计的任务无法与更改离线商店中部门顺序的任务相提并论。
该公司拥有一支参与忠诚度计划的团队,其飞行员最接近经典的A / B测试理念。 对于“普通” A / B测试,我们遇到的问题是非常不典型的。 例如:
- 如果更改香肠和糕点部门的订单,商店的财务状况将如何改变?
- 客户流失的模式将如何影响财务业绩?
- 设置postamate将如何影响商店性能?
客户认为某种改变将对其中一项指标产生积极影响(我们将在后面讨论)。 我们的工作是帮助他们根据数据验证其假设。
指标
我们正在测试哪些指标?
RTO ,
平均检查和
流量是我们开放空间机翼中最常用的词。
业务的主要指标之一,也是最难测试的指标。
该商店的每日营业额以百万卢布为单位。 因此,指标的价差至少以几千卢布衡量。 确定样本大小的复杂而漫长的公式表示,方差越大,任何有意义的结论都需要更多的数据。 为了在如此大的PTO分散度下,即使要达到十分之一的效果,商店的飞行员也需要花费六个月的时间。
想象一下董事会的反应,如果在与他们的会议上说飞行员需要在所有商店花六个月甚至一年的时间? =)
我们有两种标准方法。
第一种方法:我们不考虑整个商店的RTO,而是某种产品类别。 例如,由于商店中两个部分的重新布置(“蛋糕”和“香肠”),预计这两个类别的PTO都会增加。 一类的RTO比整个商店的RTO小得多,因此分散性较低。 在这种情况下,我们希望这些类别中的飞行员与其余类别隔离。
第二种方法:我们采样时间。 观察单位不是整个飞行员的商店PTO,而是每周或每天的PTO。 因此,我们增加了观察次数,同时保持了原始数据的方差。
- 平均支票或RTO /支票数 -一张支票的平均金额。
部分更改旨在使人们购买更多商品,因此,如果我们使用通常的指标进行类比,则我们会测试RTO /支票数量或平均支票数量。
测试此指标的难度与零售的具体情况有关。 例如,随着“ 3为2的价格”促销活动的试点推出,计划购买一种产品的人将购买三种产品,而支票的金额将增加。 但是,如果他后来变得不太可能去商店并且飞行员实际上没有那么成功怎么办?
为了避免在检验影响平均检查的假设时得出错误的结论,我们同时查看流量变化。 我们无法直接跟踪有多少人来到商店,因为 并非所有访问者都是忠诚度计划的客户,因此,对于A / B测试,每张支票都是对客户的“独特访问”。 类似于PTO,我们考虑不同时间间隔的流量:每天的流量,每小时的流量。
平均检查与流量之间的关系非常重要:飞行员是否可以增加平均检查,但减少流量并最终不会导致PTO增加,而是导致PTO减少? 飞行员可以在不改变平均费用的情况下帮助增加流量吗?
在我们可以改变商品价格的框架中,有一些飞行员-有些人的价格上涨了,而有些人则相反。 由于我们不影响生产成本,因此通过改变价格,我们可以改变商品的保证金。 这样的飞行员会导致流量增加,并增加平均检查量。 但这是否意味着该试点成功了,并且值得在该网络的所有商店中更改价格? 不,人们很可能会开始更多地购买负利润或小利润的商品而放弃高利润的商品。 因此,RTO并不总是跟随总利润的增加;因此,值得分别测试这些指标。
好吧,假设我们已经确定了目标指标。 以下问题:
- 客户计划接收什么尺寸的效果?
- 在实验中实际上可以检测到什么效果?
- 实验需要多长时间?
- 哪一组?
实验总结
在线用户进行的A / B测试具有显着优势-他们具有很高的推广能力。 换句话说,在实验过程中获得的结论可以按比例缩放到所有用户。 实验设置保证了泛化能力:对照组和测试组是随机组成的,几乎两个组均来自同一分布,您可以在两个组中捕获大量流量-会有预算。
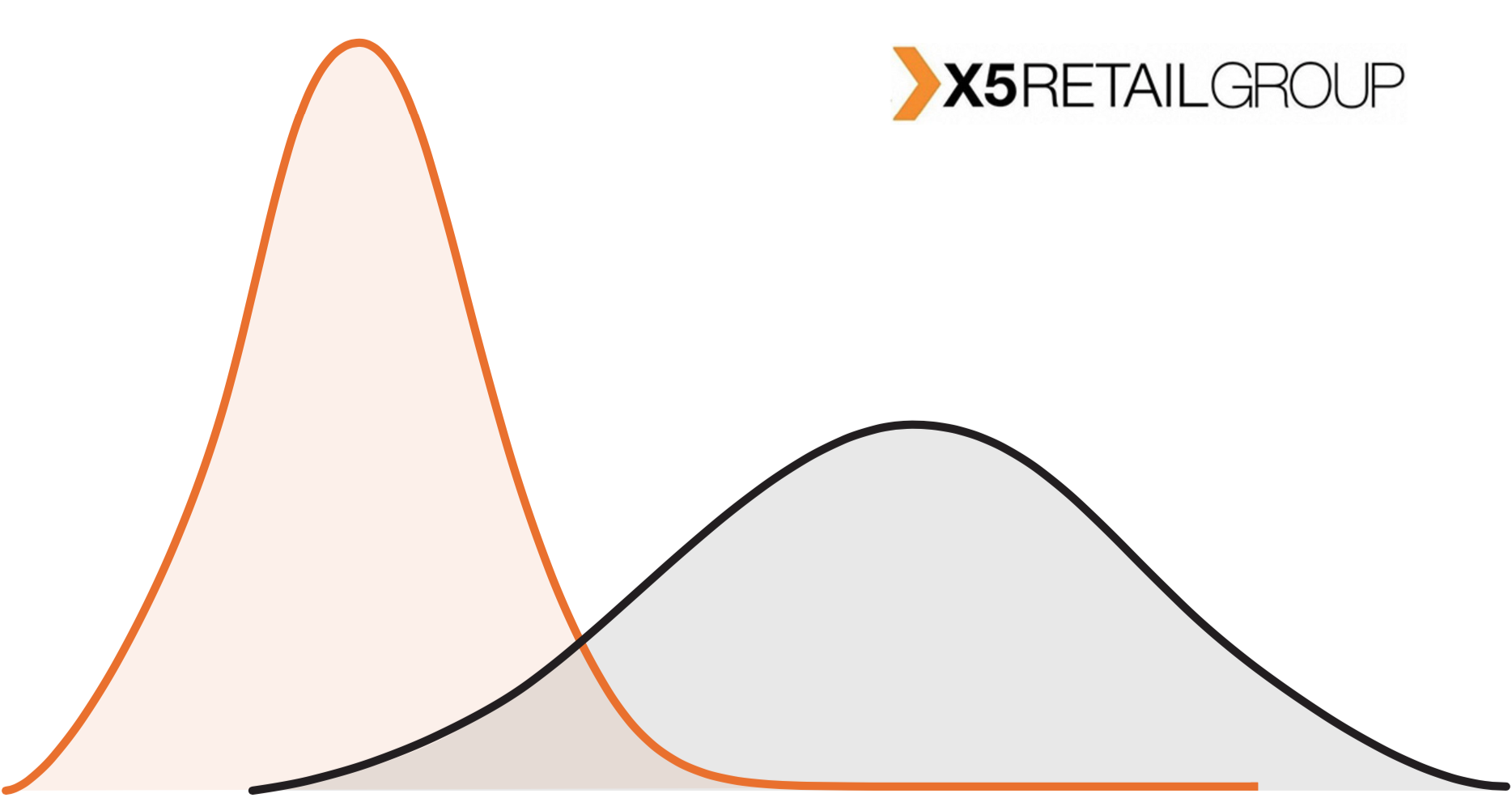
对于离线零售,这些设置都不起作用。 首先,商店的数量是有限制的。 其次,商店之间存在很大差异。 实际上,居住区中的Perekrestok商店和商务中心附近的Perekrestok是来自不同分布的完全不同的对象。

在图中,我们看到测试组中的商店与整个网络的商店不同。 这是一个非常典型的情况:在Pyaterochka连锁店中,不仅在城市,而且在小居民区都设有商店。 大型飞行员通常会在城市举行。 无论我们收到什么影响,在整个网络上扩展它都是错误的。
我们通过以下公式评估飞行员的总效果:

a是试点组的分布与网络中所有商店的相交区域。
请注意,这不是统计定律的结果,而是我们对考虑累积影响的逻辑性的假设。
理想的选择是为测试组招募代表性样本,即真正反映网络整个状态的商店。 但是代表性导致样本异质性,因为 PTO较低或较高的商店将被采样。
小组人数,飞行员时长和可察觉的影响最小
现在最重要的是-效果的大小和飞行员的持续时间。 通常,我们面临以下三种情况之一:
- 客户有飞行员的时间限制以及可以合作的商店数量;
- 客户知道他希望收到的效果规模,并要求指出飞行员需要的商店数量(然后是商店本身);
- 客户愿意接受我们的报价。
不能说任何一种情况都比较简单,因为无论如何我们都在准备一个影响误差表。
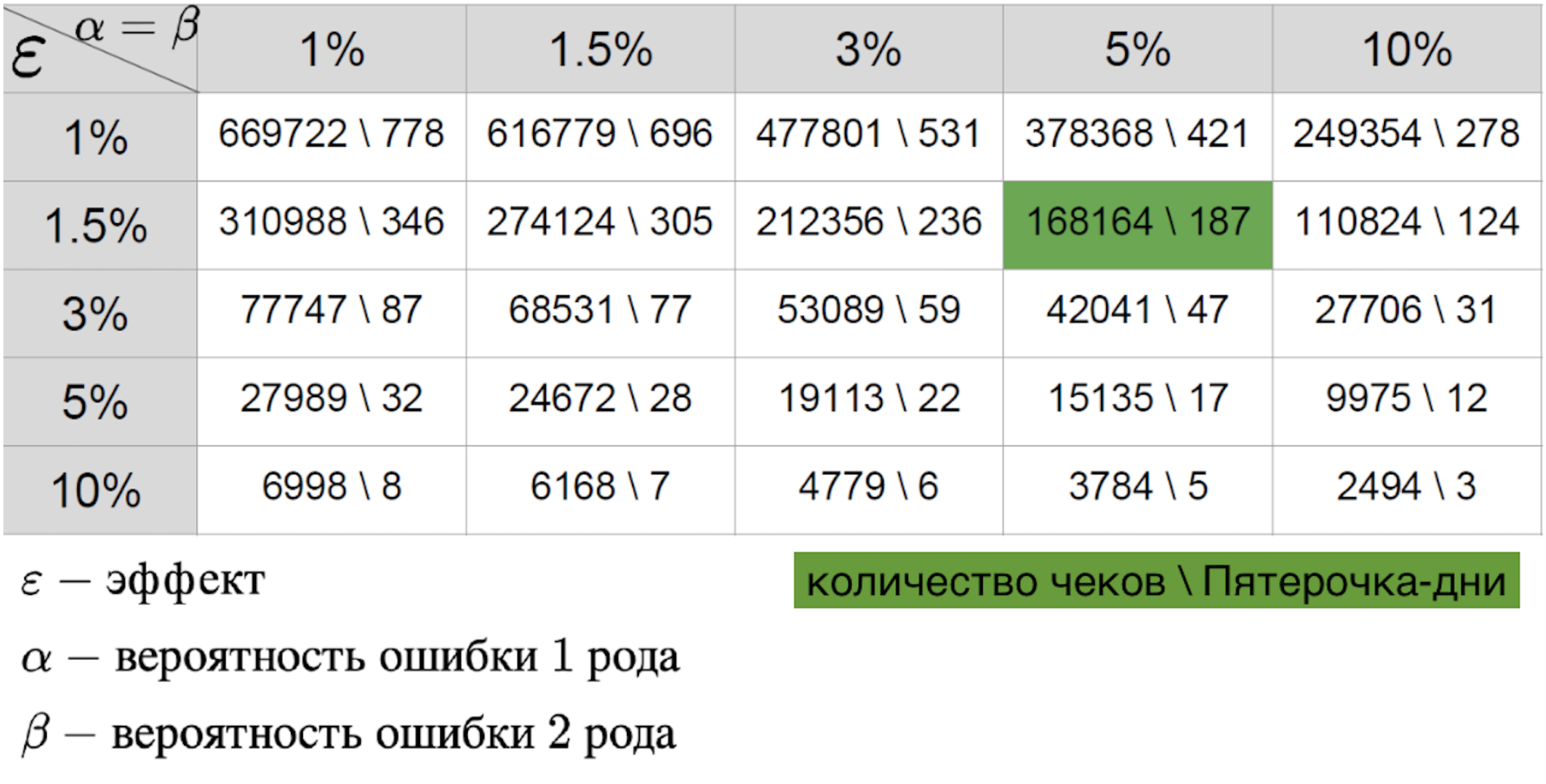
对她很重要:
- 第一种错误-不在时看到效果的可能性;
- 第二种错误-跳过效果时的可能性;
- 成功试点所预期的效果大小。
这三个参数的组合使您可以计算所需的飞行员持续时间。 表格中的值是样本数量-在这种情况下,每天进行试点所需的收据数量或商店中的平均度量标准。 如果我们谈论现实世界,那么通常第一类和第二类错误的概率是5-10%。 从表中可以看出,由于存在此类固定错误,我们需要421 Pyaterochka天才能赶上百分之一的影响。 看来这个数字相当不错-毕竟,每天421 Pyaterochka是40家商店的试点,为期10天。 但是,只有一个“但是”-很少有飞行员真正期望百分之一的效果。 通常我们讲的是百分之一的十分之一。 鉴于RTO是以十亿计的,成功试点的效果的十分之一可以大大增加收入。 因此,我想测量最小的影响。 但是效果大小越小,第二种方法的误差就越大。 这是可以理解的:微小的影响类似于随机噪声,很少被认为是与规范的真正偏离。 在下面的图形中可以清楚地看到这一点,我们希望在具有较大方差的数据中捕获较小的影响。

A / A测试
在试验开始之前,您需要确定测试和控制组。 客户可能有或没有试点组。 我们准备通过请求限制在这两种情况下为他提供帮助-例如,商店应严格位于三个特定区域。
假设我们以某种方式选择了一个测试和对照组。 如何确保所选的组很好,并且您真的可以对它们进行A / B测试? 似乎一切听起来都很和谐:我们给观察值打了分,根据公式可以得出0.7%的效果,我们找到了类似的商店。 现在什么不适合我们?
不幸的是,很多严肃的事实:
- 样本中的元素并非来自同一分布-我们的样本是来自不同商店的观察结果的混合,并且每个商店都有自己的分布。
- 样本的要素不是独立的-样本中有一个商店的观测值很多,它们之间有联系;
- 在没有飞行员的情况下无法保证均等- 我们根本不确定如果没有飞行员,那么商店的统计信息不会有所不同。
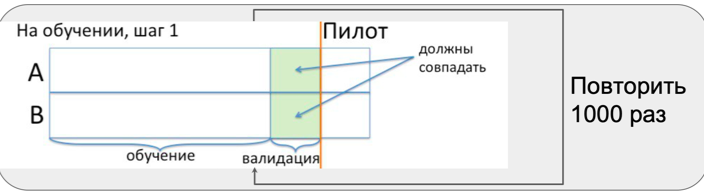
在根据误差和影响选择观察次数的公式的计算中,未考虑所有这些问题。 为了了解上述问题的影响程度,我们进行了A / A测试。 实际上,这是在商店中没有飞行员时对商店中的整个飞行员进行的模拟。 这个时期称为预试。

在试行期间,我们多次重复了三个步骤:
- 选择类似的团体;
- 两组平等测试;
- 增加测试组的效果并测试均等性。

匹配相似的群体
我们没有发明自行车,因此我们正在寻找具有最近邻居的旧方法的类似群体。 为商店生成特征的策略是另一种艺术。 我们发现了三种工作方法:
- 根据我们正在测试的指标,每个商店都由一个特征向量来描述。 例如,当检查平均支票时,我们描述了8周的每日平均支票-我们为商店获得56个标牌。 然后,我们计算一对商店的标牌之间的欧几里得距离。
- 查找动态相似的商店。 存储的度量绝对值可能有所不同,但趋势却是重合的-通过某些数学操作,可以将这些存储视为相同。
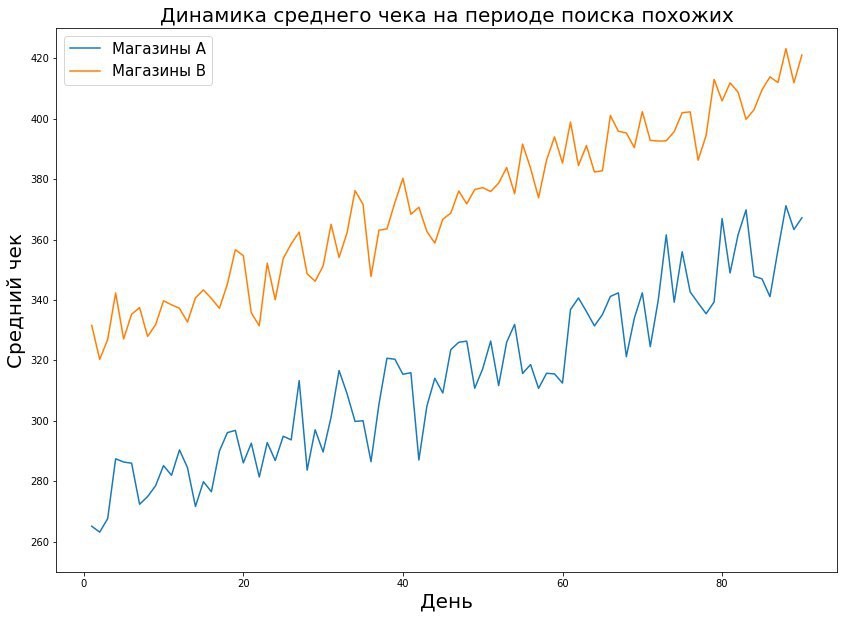
- 预测商店在试用期内的表现(将来),并根据它们选择类似的商品-但是在这里,我们需要一个能准确预测飞行员表现的预言家。
我们坚持一个非常简单的假设:如果在试点之前商店是相似的,那么如果没有试点变更,它们将保持相似。
您会注意到,即使在这三种工作方法中,也可以在许多方面进行变化:考虑功能的天数/周数,评估指标动态的方法等。
没有万能药,在每个实验中,我们都会根据目标选择不同的选项。 但这很简单:找到一种选择最接近邻居的方法,该方法会给出第一类和第二类的合理错误。 它们来自何处,我们进一步说明。
测试均值是否相等或第一种方法的错误
回想一下,在这一点上,我们:
- 与客户确定效果的大小和飞行员的持续时间
- 解释了第一类和第二类错误的本质
- 建立了选择相似群体的方法
此阶段的目标是确保我们在第3节中选择的方法找到这样的组,以使飞行员在这些商店中的指标(RTO,平均检查,流量)在统计上没有差异。
在循环中,我们通过某种统计检验和自举法反复选择选定的组以实现相等性。 如果错误比例(即,组彼此不相等)高于阈值,则拒绝该方法并选择一个新的方法。 因此,直到我们达到所需的错误阈值。
重要的是要找出不存在效果时我们捕获效果的频率,即 我们的选择方法是否响应商店之间的随机差异。
添加效果或第二种方法的错误
这是一个合理的问题,但是我们是否不会以将实际效果也视为噪声而忽略它们的方式进行自我训练? 换句话说,我们是否能够检测到效果?
在最后一步确保各组重合后,我们向其中一个组添加了人工效果,即 我们保证试点成功并取得成功。
这次的目标是找出平等假设被拒绝的频率,即 该测试能够区分两组。 在这种情况下的错误是假定组是相等的。 我们将此错误称为第二种错误。
同样,在周期中,我们测试对照组和“嘈杂”测试组是否相等。 如果我们很少犯错误,那么我们认为选择组的方法已通过验证。 它可以用来在试点期间选择组,并确保如果试点产生了效果,我们将能够检测到它。

关于异质性
我们已经提到,数据异质性是我们所面临的最大敌人之一。 不均匀性是由多种根本原因引起的:
- 购物的异质性-每个商店都有自己的平均指标值(在莫斯科RTO商店中,访问量远大于在乡村商店中)
- 一周中各天的异质性-流量的分布不同以及一周中不同日期的平均检查不同:星期二的流量看起来不像星期五的流量
- 天气的异质性-人们在不同的天气条件下购物的方式有所不同
- 一年中时间的异质性-冬季的流量与夏季的流量不同-如果飞行员持续数周,则必须考虑到这一点。
不均匀性增加了方差,如上所述,在评估PTO存储库时,方差已经具有巨大的意义。 捕获效果的大小直接取决于方差。 例如,将色散降低四倍,可以检测到一半效果。
在最简单的情况下,我们正在努力解决线性化的异质性问题。
假设我们在两家商店中进行了为期三天的试点(是的,这与所有关于效果大小的规定公式相矛盾,但这是一个示例)。 商店中的平均
RTO分别为20万和50万,而两组的方差为10,000,根据所有观察,则为35,000
试点之后,平均值分为300和600组,方差分别为10,000和22,500,整个组为40,000。

一个简单而优雅的举动是线性化数据,即 从每个期间值中减去上一个期间的平均值。

在输出处,样本为:100、0、200,-50、100、250。试点期间的色散减少了3倍,达到13000。
这意味着我们可以看到比原始绝对值更微妙的效果。
这不是处理异质性的唯一方法。 我们将在下一篇文章中讨论其他内容。
A / B测试的一般方法
大型飞行员的准备工作和他们的评估通过了我们的团队,并经过了全面的测试。
我们的协议:
- 从客户那里接收有关度量标准和预期效果的信息;
- 确定小组的规模和飞行员的持续时间;
- 开发一种按组分配商店的算法;
- 在组之间进行A / A测试并验证该算法;
- 等待飞行员完成并计算效果。
这些阶段都不是没有困难地通过的;每个阶段都有其特点。 我们在本文中介绍了如何处理其中的一些。 接下来,我们将讨论...。
团队
最后,我想提一下所有演员:
- 瓦列里(Valery Babushkin)
- 亚历山大·萨赫诺夫(Alexander Sakhnov)
- 丹尼斯·伊万诺夫(Denis Ivanov)
- 谢尔盖·登琴科(Sergey Demchenko)
- 尼古拉·纳扎罗夫(Nikolay Nazarov)
- 谢尔盖·卡巴诺夫(Sergey Kabanov)
- 尤里·加里米林
- 海伦·特凡扬(Helen Tevanyan)
- 弗拉迪斯拉夫·拉登科夫
- 谢尔盖·扎哈罗夫(Sergey Zakharov)
- 瓦西里的故事
- 亚历山大·别利亚耶夫(Alexander Belyaev)
- 基斯马特·马戈梅多夫(Kismat Magomedov)
- 埃戈尔·克拉申尼科夫(Egor Krashennikov)
- 艾格(Egor Karnaukh)
- Svyatoslav Oreshin
- 尤里·特鲁比森(Yuri Trubitsyn)