我们为什么还要编写具有竞争力的代码? 因为处理器不再沿着低谷增长,而是开始沿着核心增长。 处理器内核的数量每年都在增加,我们希望有效地利用它们。 Go是为此创建的语言。 该文件是这样说的。
我们开始使用Go,开始编写具有竞争力的代码。 当然,我们希望我们可以轻松地限制处理器每个内核的功能。 是这样吗
我叫Artemy。 这篇文章是我与GopherCon Russia的谈话的免费笔录。 它似乎是为了激励那些想弄清楚如何编写出色的,具有竞争力的代码的人们。
GopherCon俄罗斯会议的视频
互动模型
为了了解Go是否真的使我们更轻松,让我们看一下两个交互模型: Shared Memory和Message Passing 。


Go的创始人之父Rob Pike说,您需要放弃使用Shared Memory的低级编程,而要使用Message Passing方法。 这种方法将帮助您更轻松,更有效地编写代码,并且最重要的是,更少的错误。 Go选择CSP方法。 相同的方法极大地影响了诸如Erlang这样的语言的发展。
问题:的确,如果我们使用Go,一切都会好起来吗?

我遇到了一项研究 ,发现了这款平板电脑。 数位板会显示与锁定相关的错误的原因以及数量。 第一列显示了纳入研究的产品。 这些是用Go语言编写的最受欢迎的产品。 “共享内存”列显示由于共享内存使用不当而引起的错误的数量,“消息传递”列分别显示由于“消息传递”而导致的错误的数量。
在该板上最重要的是总计行。 如果您查看它,将会发现使用Message Passing时比使用Shared Memory时有更多的错误。 我确信写Kubernetes,Docker或etcd的人都是经验丰富的开发人员,但是即使他们的Message Passing也不能避免出错,而且这些错误不少于共享内存。
因此,仅使用Go并开始编写无错误的代码将失败。
并发与并行
当我们开始谈论多线程开发时,我们需要引入诸如并发和并行的概念。 在Go的世界中,存在“并发不是并行性”的表达。 底线是并发与设计有关,即我们如何设计程序。 并行只是执行代码的一种方式。

如果我们有多个同时执行的指令线程,那么我们将并行执行代码。 并行需要竞争。 没有竞争性设计就不可能并行化程序,而竞争性就不需要并行性,因为实际上可以在多个内核上运行的程序可以在一个内核上运行。
Go是一种语言,可以帮助我们编写具有竞争力的程序,可以帮助我们构建设计。 它使您可以少思考低级的事情。
阿姆达尔定律
我们要利用处理器内核,为此我们编写了一些代码。 但是问题来了:随着内核数量的增加,生产率得到了什么样的提高。 因此,事实上,我们所能获得的加速度受到Amdal法则的限制 。
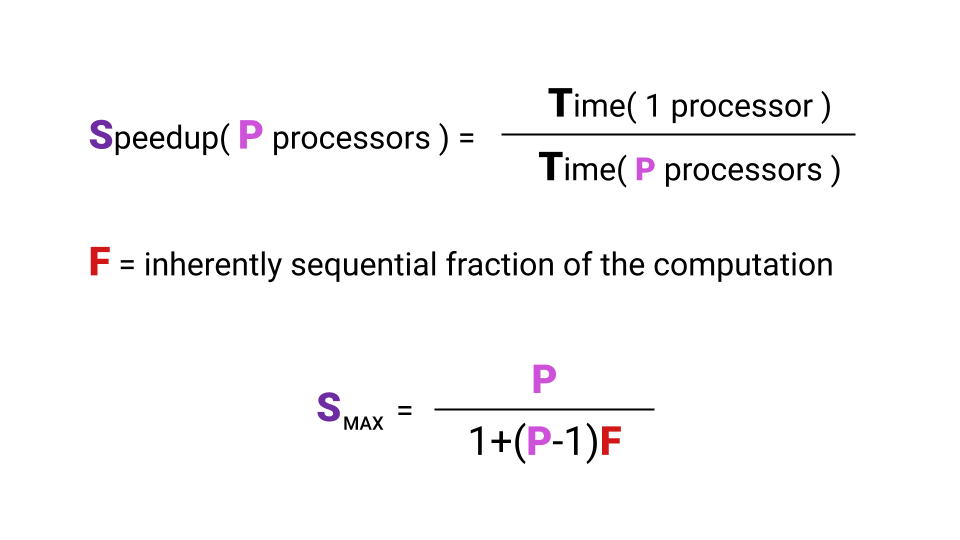
什么是加速度? 加速是程序在单个处理器上运行的时间除以程序在P处理器上运行的时间。 字母F ( 分数 )表示必须顺序执行的程序部分。 在这里甚至没有必要去研究公式,主要要注意的是,随着原子核数量的增加,我们获得的最大加速度强烈取决于F。 看一下图表以可视化这种关系。
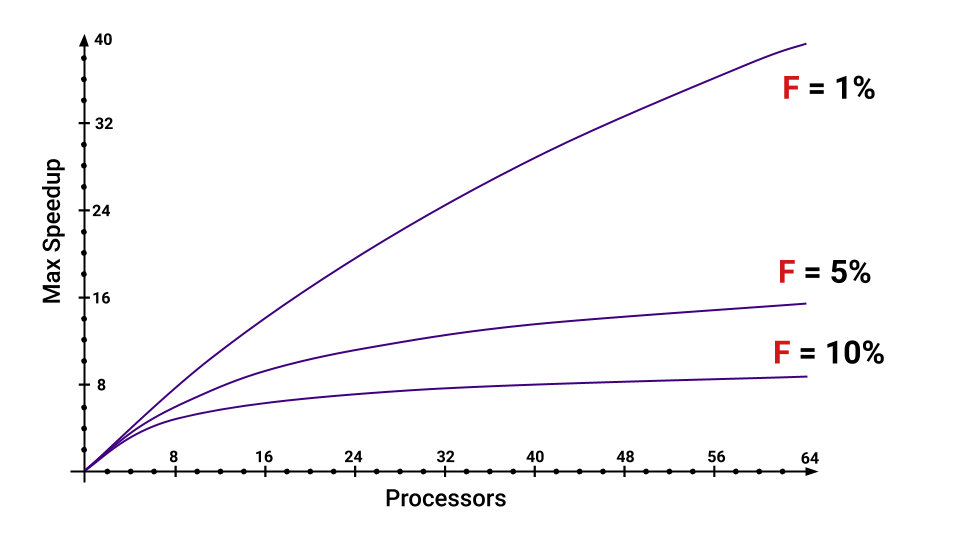
即使我们只有顺序执行的程序的5%,随着内核数量的增加,我们获得的最大加速度也会大大降低。 您可以估计增加F的部分。
CPU绑定与I / O绑定
使用多线程并不总是有意义。 首先,您需要查看负载的类型。 有两种类型的负载: CPU绑定和I / O绑定 。 不同之处在于,使用CPU绑定时,我们受到处理器性能的限制,而使用I / O绑定时,我们受限于I / O子系统的速度。 甚至没有速度,而是等待答案的时间。 联机-等待答案,进入磁盘-再次等待答案。 如果大多数时候我们在等待答案,那有什么区别,有多少个内核?
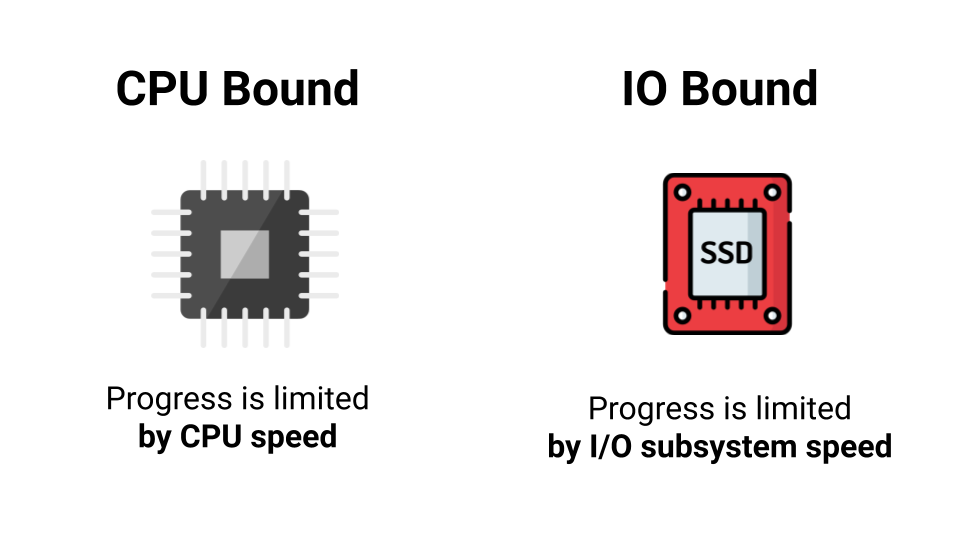
因此,一核或一千核,在I / O绑定负载下,性能不会得到提高。 但是,如果我们有CPU绑定负载,那么在并行化程序时就有机会获得加速。
尽管有时会出现明显的CPU绑定负载,但实际上它会退化为I / O绑定。 例如,如果我们要对一个大型数组的所有元素求和并求和,该怎么办? 我们将编写一个循环,一切正常。 然后我们认为:“因此,我们有很多核心。 让我们来看一下,将数组分成多个块,然后将整个事情并行化。” 结果如何?
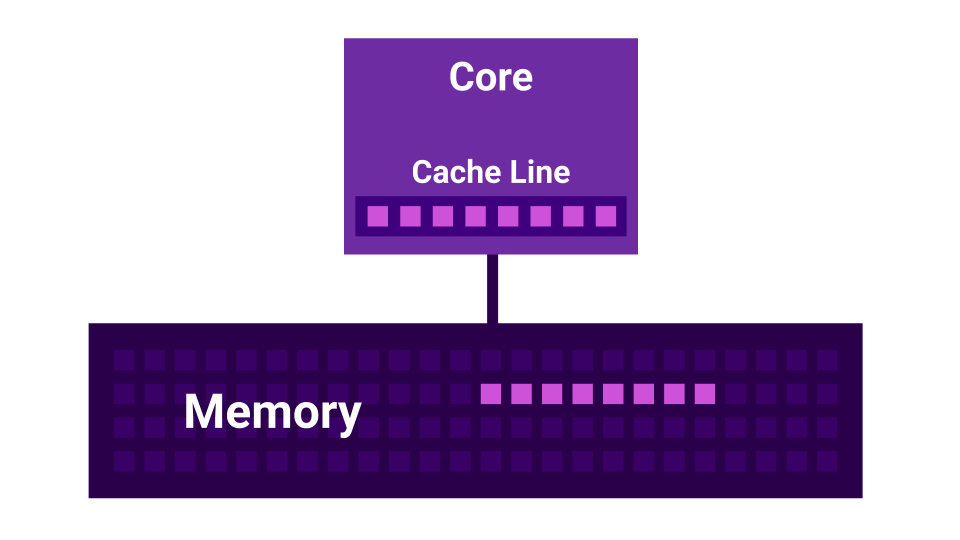
结果是我们的处理器处理数据的速度快于它们从内存获得的数据。 在这种情况下,大多数时候我们将等待内存中的数据,而看起来似乎是CPU绑定的负载实际上是I / O绑定。
虚假分享
此外,还有一个类似False Sharing的故事。 错误共享是指内核开始相互干扰的情况。 有第一个核心,有第二个核心,每个核心都有自己的L1 Cache 。 L1缓存分为64个字节的行( Cache Line )。 当我们从内存中获取一些数据时,我们总是得到不少于64个字节。 通过更改此数据,我们将禁用所有内核的缓存。

事实证明,如果两个内核更改彼此之间非常接近的数据( 距离小于64个字节 ),它们将开始相互干扰,从而使缓存无效。 在这种情况下,如果程序是按顺序编写的,则比使用几个相互干扰的内核时,它的运行速度更快。 内核越多,性能越低。
调度程序
我们将提升到计划者的下一个抽象层次。
当工作以具有竞争力的代码开始时,将显示调度程序。 Go有一个在goroutines上运行的所谓的用户空间调度程序 。 操作系统还具有自己的调度程序 ,该调度程序与操作系统的线程一起运行 。 甚至处理器也不是那么简单。 例如,现代处理器具有分支预测和其他方式来破坏我们对世界线性化的美好印象。
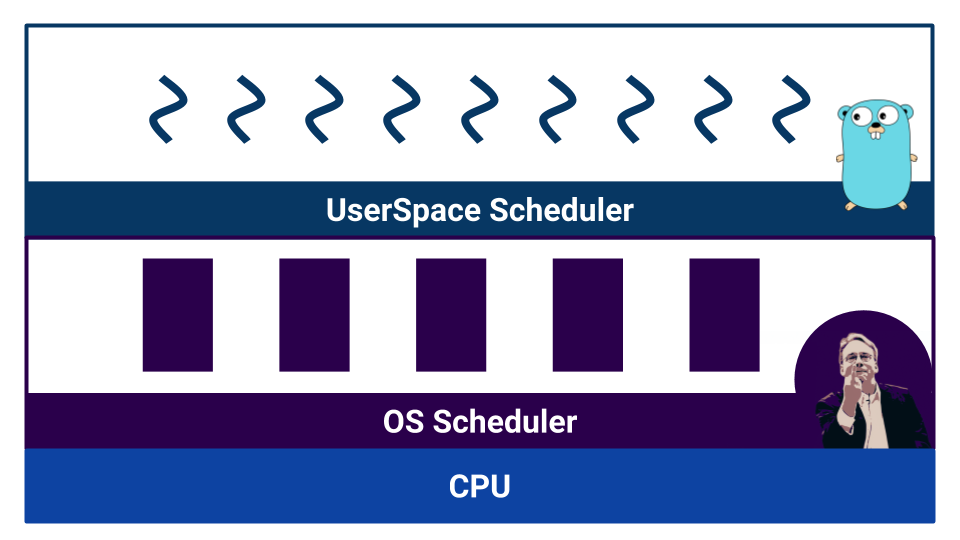
调度程序按多任务处理的类型划分。 有协作 式多任务 处理和抢占式多任务处理 。 在协作式多任务处理的情况下,执行进程本身决定何时需要将控制权转移到另一个进程,而在拥挤的多任务处理的情况下,存在一个外部组件 -调度程序,该程序控制向该进程分配多少资源。

协作多任务允许一个进程“垄断”整个CPU资源。 在抢先式多任务处理中,这不会发生,因为有一个控制主体。 但是,使用协作式多任务处理,上下文切换更为有效,因为该过程可以肯定地知道在什么时候将控制权交给另一个过程会更好。 在抢占式多任务处理中,调度程序可以随时停止该进程-这不是很有效。 同时,在抢占式多任务处理中,借助外部调度程序,我们可以为每个进程提供相同的资源。
操作系统使用基于抢占式多任务的调度程序,因为要求操作系统保证每个用户的条件相同。 那去呢?
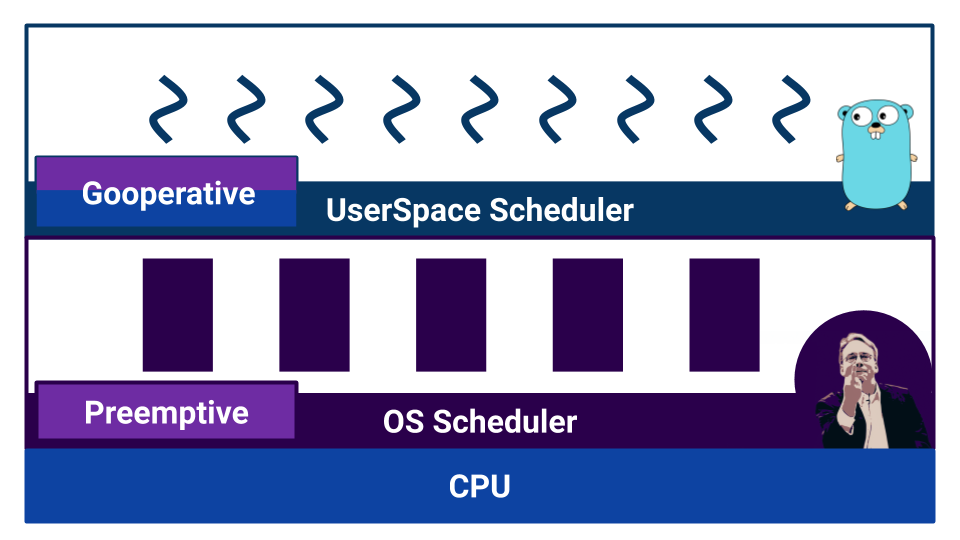
如果阅读文档,就会发现Go中的调度程序是抢占式的。 但是,当我们开始理解时,事实证明Go没有将调度程序作为外部组件。 在Go中,编译器设置上下文切换点。 而且,尽管我们作为开发人员不需要手动切换上下文,但是切换控制不会带到外部组件。 因此,Go在将一个goroutine切换到另一个goroutine方面非常有效。 但是,对这样的“计划者”的工作特征的误解会导致意想不到的行为。 例如,此代码将输出什么?

这样的代码将冻结。
怎么了 因为GOMAXPROCS ,我们使用GOMAXPROCS强制程序仅使用一个内核。 之后,将goroutine放入队列中,在其中应该进行无尽的循环。 然后我们等待500毫秒并打印x 。 在time.Sleep之后time.Sleep goroutine实际上会启动,但是不会退出无限循环,因为编译器不会放置上下文切换点。 程序冻结。
如果在循环内添加runtime.Gosched() ,那么一切都会好起来的,因为我们将明确表示要切换上下文。
这些功能也需要知道和记住。
我们讨论了上下文切换,但是Go通常在哪里插入切换点?

通常在调用函数时插入runtime.morestack()和runtime.newstack() 。 runtime.Goshed()我们可以自我提供。 当然,上下文切换是在锁定,网络中断和系统调用期间发生的。 您可以在Kirill Lashkevich的报告中查看这个主题。 很好,我建议。
让我们进一步接近代码。 我们将研究错误。
比赛条件
我们犯的最普遍的错误之一是Race Condition 。 底线是,例如,当我们执行增量操作时,实际上我们不执行一项操作,而是执行多项操作:处理器从存储器读取数据以进行寄存器注册,更新寄存器并将数据写入存储器。

这三个操作不是原子执行的。 因此,在任何这些操作上,调度程序都可以随时提取并排挤我们的流程。 事实证明,该操作尚未完成,因此我们发现了错误。
这是此类代码的示例( 增量立即分解为几个操作 )。

调度程序可以在执行第一行之后抢占第一个线程,并在检查条件之后抢占第二个线程。 在这种情况下,两个流都将落入关键部分,因此它是“关键的”-不能同时在此处输入两个流。
我们可以使用标准sync包中的sync.Mutex进行锁定。 访问阻止使我们能够明确指示代码一次应由一个线程执行。 有了这段代码,我们就能得到所需的东西。

锁是相当昂贵的操作。 因此,在处理器级别存在原子操作。 在这种情况下,可以通过用atomic软件包中的atomic.AddInt64操作替换该增量,使其成为atomic。
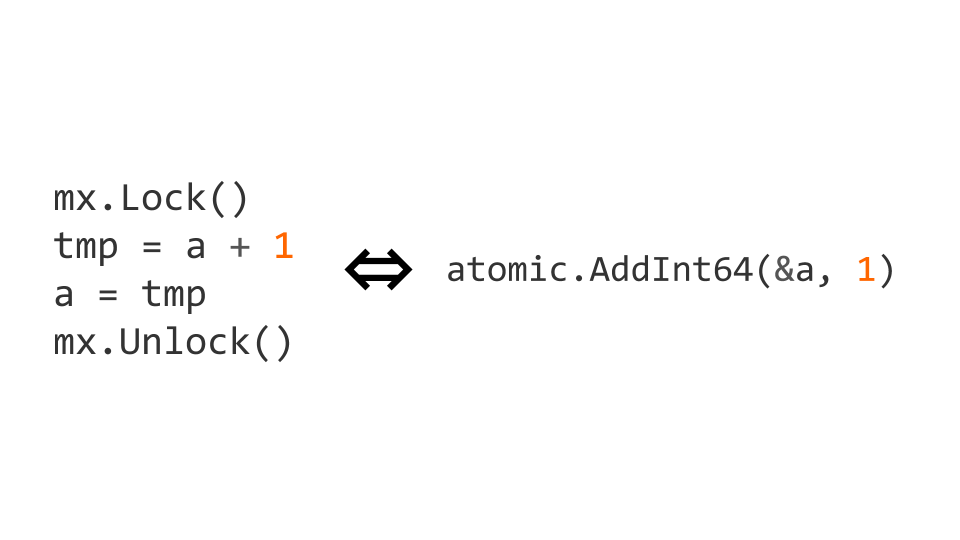
如果我们开始使用原子指令,那么我们不仅需要原子编写,还需要原子读取。 如果我们不这样做,那么可能会出现问题。
优化-可能出错的地方是什么?
锁很好,但价格昂贵。 原子足够便宜,不必担心性能。
因此,我们了解到同步原语会带来开销,并决定添加优化-我们将在不考虑多线程的情况下检查标志,然后使用同步原语进行双重检查。 一切看起来都很好,应该可以工作。

一切都很好,只是编译器正在尝试优化我们的代码。 他在做什么? 他交换了赋值指令,我们得到了无效的行为,因为在赋值变量“ done就变为true 。
不要尝试进行此类优化-因为它们,您会遇到很多问题。 我建议您阅读The Go Memory Model的规范以及Dmitry Vyukova( @dvyukov )的一篇文章良性数据竞赛:可能会出错吗? 以便更好地了解问题。
如果您确实依赖于锁的性能,请编写无锁代码,但不需要对内存进行非同步访问。
死锁
我们将面临的下一个问题是死锁。 似乎这里的一切都很琐碎。 有两种资源,例如,两个Mutex 。 在第一个线程中,我们首先捕获第一个Mutex ,在第二个线程中,我们首先捕获第二个Mutex 。 此外,我们将要在第一个线程中使用第二个Mutex ,但是我们将无法执行此操作,因为它已被阻塞。 在第二个线程中,我们将尝试分别使用第一个Mutex和also块。 他在那里,死锁。
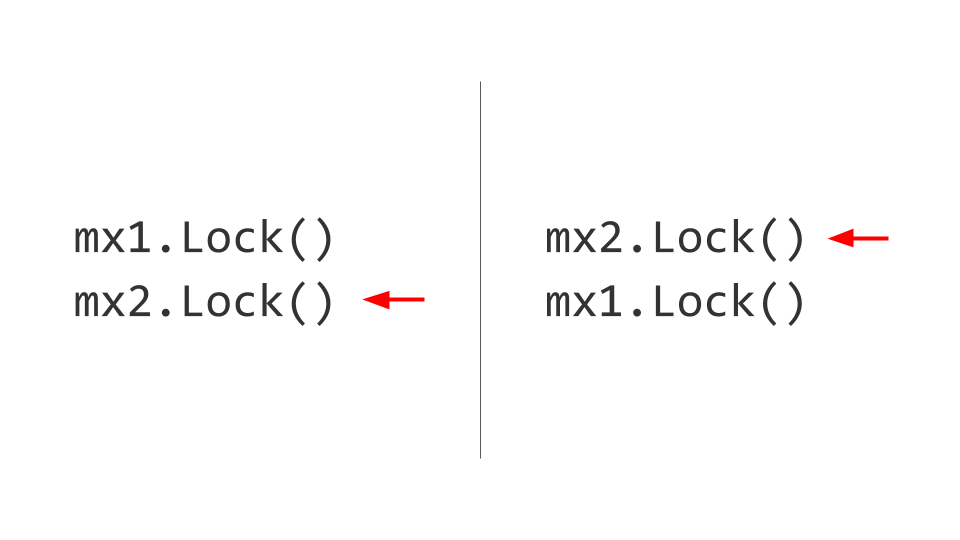
这两个线程都将无法继续前进,因为它们两个都将等待资源。 如何解决? 我们交换锁,然后不会出现任何问题。 当然,这很容易说,但是在产品的整个生命周期中保持这一规则并不容易。 如果可能的话,请按照相同的顺序进行操作并给予锁 。
看起来经验丰富的开发人员似乎没有遇到此类错误,但这是项目代码etcd陷入僵局的示例。

这里的主要问题是,写入无缓冲通道的操作受阻;另一方面,要写入,则需要一个读取器。 使用互斥锁,第一个线程等待读取器出现。 第二个线程无法再捕获互斥量。 死锁
我建议您尝试令人兴奋的游戏《僵局帝国》 。 在此游戏中,您充当必须切换上下文的调度程序,以防止代码正确执行。
有点问题
仍然存在哪些问题? 我们从种族条件开始。 接下来,我们研究了死锁 (仍然存在Livelock的变体,这是当我们无法捕获资源但没有显式锁的时候)。 这里是饥饿 ,这是我们去打印机打印一张纸时遇到的一个队列,我们无法访问资源。 我们通过False Sharing查看了程序的行为。 仍然存在一个问题- 锁争用 ,这是由于对资源的大量竞争而导致性能下降(例如,大量线程需要一个互斥锁)。

种族检测
开箱即用的工具箱使Go功能强大。 种族探测器就是这样一种工具。 使用它很简单:我们编写测试或在战斗负荷下运行它并捕获错误。
您可以在文档中阅读有关使用Race Detector的更多信息,但请记住,它有局限性。 让我们更详细地讨论它们。

首先,Race Detector不检查未执行的代码。 因此,测试覆盖率应该很高。 另外,Race Detector会记住内存中每个单词的调用历史记录,但是这种调用历史记录具有深度。 例如,在Go中,此深度为4-4个元素,4个访问权限。 如果“种族探测器”没有在此深度内参加比赛,则他认为不会有种族。 因此,尽管Race Detector永远不会出错,但它不会捕获所有错误。 您可以期望使用“种族探测器”,但是您需要记住它的局限性。 另外,您可以阅读work的算法 。
区块简介
阻止配置文件是另一个工具,它使我们能够查找和修复阻止问题。

它既可以在基准测试水平上使用,也可以在战斗负荷下观看。 因此,如果您正在寻找与数据访问同步相关的问题,请尝试从“ Race Detector”开始,然后继续使用“ Block Profile”。
程式范例
让我们看看我们可以偶然发现的真实代码。 我们将编写一个仅接收请求数组并尝试执行它们的函数:每个请求按顺序进行。 如果有任何请求返回错误,则函数终止执行。

如果使用Go语言编写,则必须使用该语言的全部功能。 我们尝试。 我们得到三倍的代码。

问题:代码中是否有任何错误?
当然可以! 让我们看看哪个。
在循环中,我们运行goroutines。 对于goroutine编排,我们使用sync.WaitGroup 。 但是,我们在做什么错呢? 已经在正在运行的goroutine中,我们调用wg.Add(1) ,即,我们再添加一个goroutine等待。 然后使用wg.Wait() ,等待所有goroutine完成。 但是可能会发生,在调用wg.Wait() ,不会启动任何goroutine。 在这种情况下, wg.Wait()认为一切wg.Wait()完成,我们将关闭通道并退出函数而不会出现错误,并认为一切都很好。

接下来会发生什么? 然后,goroutine将启动,代码将执行,并且可能其中一个请求将返回错误。 将错误写入关闭的通道,而写入关闭的通道则很恐慌。 我们的应用程序将崩溃。 这不太可能是我想要得到的,因此我们通过预先指示要启动多少个goroutine来更正它。

也许还有一些问题?
有一个错误与req对象如何出现在函数内部有关。 req变量充当循环的迭代器,我们不知道在goroutine启动时它将具有什么值。

实际上,在此代码中, req值很可能等于数组的最后一个元素。 因此,您只发送相同的请求N次。 修正:明确地将我们的请求作为参数传递给函数。

让我们仔细看看我们如何处理错误。 我们在一个插槽上声明一个缓冲通道。 发生错误时,我们将其发送到此通道。 一切似乎都很好:发生了错误-我们从函数中返回了此错误。

但是,如果所有请求均返回错误怎么办?
然后写入通道将仅获得第一个错误,其余将阻止goroutine的执行。 由于在函数退出时不再有来自通道的读数,所以我们会遇到goroutine泄漏。 也就是说,所有无法将错误写入通道的gorutin都只是挂在内存中。
我们对其进行了非常简单的修复:我们在插槽通道中选择请求数。 这解决了我们的内存效率不高的问题,因为如果我们有十亿个请求,就需要分配十亿个插槽。

我们解决了问题。 该代码现在具有竞争力。 但是麻烦在于可读性-与代码的同步版本相比,有很多东西。 这不是很酷,因为竞争性程序的开发已经很困难,为什么我们要用很多代码使其复杂化?

错误组
我建议提高代码的可读性。
我喜欢使用errgroup包而不是sync.WaitGroup 。 该程序包不需要指定期望的goroutine数量,并且允许您忽略错误集合。 这是使用errgroup时我们的函数的外观:

而且, errgroup允许errgroup使用context.Context方便地编排程序的组件。 我什么意思
假设我们有程序的几个组件,如果其中至少有一个失败,我们要仔细完成所有其他组件。 因此, errgroup在发生错误errgroup完成context ,因此,所有组件都会收到有关需要完成工作的通知。

这可用于构建行为可预测的复杂多组件程序。
结论
使其尽可能简单。 同步更好。 多线程程序的开发通常是一个复杂的过程,从而导致出现令人讨厌的错误。

不要使用隐式同步。 如果您真的休息了,请考虑如何摆脱锁,如何制作无锁算法。
Go是编写可以有效使用大量内核的程序的良好语言,但是它并不比其他所有语言都要好,而且错误总是会出现。 因此,即使拥有Go语言,也要尝试理解比您的工作要低的几个抽象层次。
