该材料是我们今天发布的翻译的第一部分,致力于解决gitlab.com中出现的一个大规模问题。 在这里,我们将讨论他们如何找到她,如何与她打架以及最终如何解决她。 另外,面对这个问题,gitlab.com团队发现了手表的暴政。

→
第二部分 。
问题
我们开始收到来自客户端的消息,这些消息是在使用gitlab.com时,它们在执行拉取请求时会定期遇到错误。 错误通常在执行CI任务时或在其他类似的自动化系统运行期间发生。 错误消息看起来像这样:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
错误消息不规则地出现,并且看起来似乎是不可预测的,这使情况变得更加复杂。 我们无法随意复制它们,无法识别出图表或日志中正在发生的任何明显迹象。 错误消息本身也没有带来太多好处。 SSH客户端被告知连接中断,但是原因可能是:客户端故障或虚拟机不稳定,我们无法控制的防火墙,异常的提供程序操作或我们的应用程序出现问题。
我们正在研究通过SSH进行GIT的方案,正在处理大量连接-每天约2600万。 这是平均每秒300个连接。 因此,尝试从现有数据流中选择少量失败的连接将是一项艰巨的任务。 这种情况的好处是我们喜欢解决复杂的问题。
第一条线索
我们联系了一位客户(感谢Atalanda的Hubert Holtz),他们一天几次遇到问题。 这给了我们立足点。 Hubert能够为我们提供合适的公共IP地址。 这意味着我们可以在HAProxy前端节点上捕获数据包,以便通过依赖小于所谓的“所有SSH流量”的数据集来尝试隔离问题。 更好的是,该公司使用了
Alternate-ssh端口 。 这意味着我们只需要分析两个HAProxy服务器上的事务状态,而不必分析16个。
但是,对软件包的分析并不是特别有趣。 尽管有大约6.5小时的限制,但仍收集了大约500 MB的数据包。 我们发现了寿命短的化合物。 TCP连接已建立,客户端发送了标识符,然后我们的HAProxy服务器立即使用正确的TCP FIN序列断开连接。 结果,我们掌握了第一个出色的线索。 她让我们断定,连接绝对是在gitlab.com的主动下关闭的,而不是因为我们和客户之间的某种关系。 这意味着我们面临着可以调查和纠正的问题。
第1课 Wireshark工具的“统计”菜单中有很多有用的工具,在这种情况下,我还没有特别注意。
特别是,我们谈论的是“
Conversations菜单项,它可以演示有关TCP连接的捕获数据的基本信息。 有关于时间,数据包,字节的信息。 可以对在相应窗口中显示的数据进行排序。 我应该从一开始就使用此工具,而不要手动将捕获的数据弄乱。 然后我意识到我需要寻找带有少量数据包的连接。 “
Conversations窗口使您可以立即注意它们。 之后,我能够找到其他类似的化合物,并确保第一个此类连接不是异常现象。
日志沉浸
是什么导致HAProxy与客户端断开连接? 服务器当然不会以任意方式执行此操作;正在发生的事情应该有更深层的原因; 如果您喜欢-“另一级别的
海龟” 。 有人认为,下一个研究对象应该是HAProxy日志。 我们的日志存储在GCP BigQuery中。 这很方便,因为我们有很多日志,我们需要对其进行全面分析。 但是首先,我们能够识别出其中一个事件的日志条目,该条目在捕获的数据包中找到。 我们依靠时间和TCP端口,这是我们研究的主要成就。 找到的记录中最有趣的细节是
t_state (终结状态)属性,其值为
SD 。 这是HAProxy文档的摘录:
S: , . D: DATA.
D的含义非常简单地解释。 TCP连接已正确建立,数据已发送。 这与从捕获的数据包获得的证据相吻合。 值
S表示HAProxy从后端接收到RST或ICMP故障消息。 但是,我们无法立即找到发生这种情况的线索。 原因可能是任何原因-从不稳定的网络(例如,故障或拥塞)到应用程序级别的问题。 通过使用BigQuery在Git后端上聚合数据,我们发现问题不在于任何特定的虚拟机。 我们需要更多信息。
我想指出的是,带有
SD值的日志条目并不是什么特别的东西,仅是我们的问题的特征。 在Alternate-ssh端口上,我们收到了许多有关扫描HTTPS的请求。 这导致以下事实:当SSH服务器希望收到SSH问候时看到
TLS ClientHello消息时,
SD值就会落入日志。 这短暂地导致了我们的绕行调查。
在捕获了HAProxy和Git服务器之间的一些流量之后,再次使用Wireshark工具,我们很快发现,在三向TCP握手之后,Git服务器上的SSHD立即与FIN-ACK TCP断开连接。 HAProxy仍然没有发送第一个数据包,但正要发送它。 当他发送数据包时,Git服务器用TCP RST回答了他。 结果-现在我们发现了HAProxy用
SD值写入有关连接失败的日志的原因。 SSH关闭了连接,有意且正确地进行了连接,而RST只是SSH服务器在FIN-ACK之后接收到数据包这一事实的产物。 仅此而已。
雄辩的时间表
在BigQuery中查看并分析具有
SD值的日志后,我们意识到错误与时间有着明显的关系。 即,我们在每分钟的前10秒内发现了失败连接数的峰值。 观察它们5-6秒。
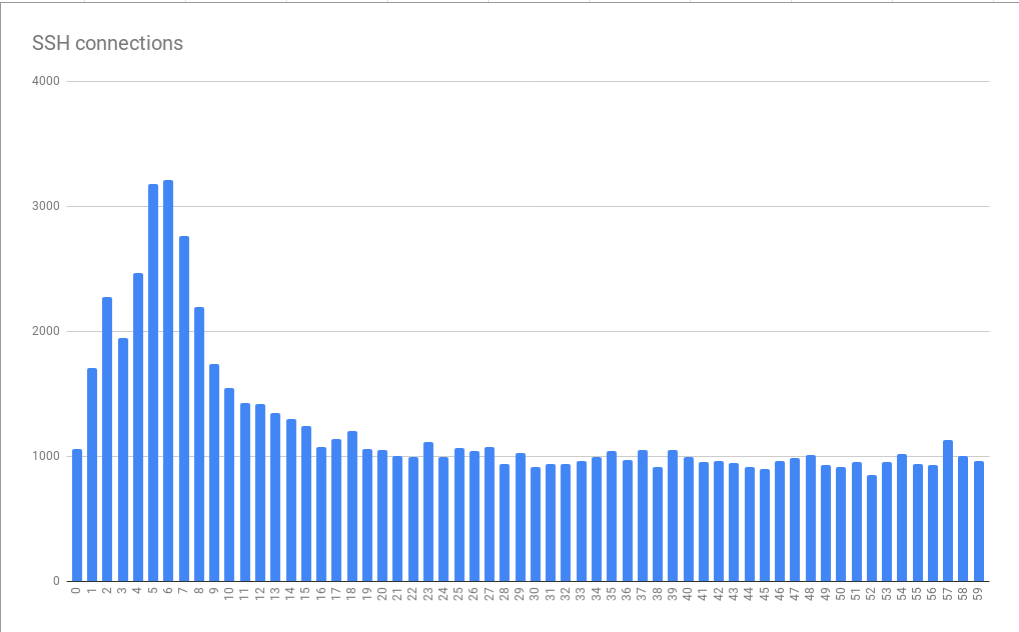 连接错误可在几分钟到几秒内归类
连接错误可在几分钟到几秒内归类该图表基于多个小时内收集的数据。 所检测到的错误分布模式被证明是稳定的事实表明,错误原因在几分钟和几小时内稳定地显现出来,甚至更糟的是,它在一天中的不同时间稳定出现。 有趣的是,平均峰大小约为基本负载的3倍。 这意味着我们面临着一个规模不小的问题。 结果,简单地以附加虚拟机的形式连接“更多资源”(旨在帮助我们应对峰值负载)在理论上可能是无法接受的昂贵。 这也表明我们正在达到某种严格的限制。 结果,我们收到了有关导致错误的基本系统问题的第一个线索。 我称它为小时的专制。
Cron或类似的调度系统通常在将任务执行定制到最接近的秒的能力上并没有不同。 如果这样的系统具有这样的功能,则由于人们倾向于考虑用美丽的整数表示的时间(分为时间间隔),因此很少使用它们。 结果,任务开始于一分钟或一小时的开始,或其他类似的时刻。 如果任务需要几秒钟的时间来准备
git fetch命令以从gitlab.com下载材料,这可以解释我们发现的模式,即系统上的负载每分钟急剧增加几秒钟。 在这样的时刻,错误的数量增加。
第2课 显然,很多人都使用正确配置的时间同步(通过NTP或使用其他机制)。
如果没有人同步的时间,那么我们的问题就不会如此清楚地表现出来。 下午好,NTP!
但是是什么导致SSH断开连接?
更接近问题的核心
通过研究SSHD文档,我们发现了
MaxStartups参数。 它控制未认证连接的最大数量。 一分钟开始时,系统受到来自Internet上大量计划任务的调用而造成的负载,似乎连接限制已用尽。
MaxStartups参数由三个数字组成。 第一个是下限(达到连接时断开的连接数)。 第二个是超出需要随机破坏的化合物下限的化合物百分比。 第三个值是绝对最大连接数,之后将拒绝所有新连接。 MaxStartups的默认值看起来像10:30:100,然后我们的设置看起来像100:30:200。 这表明过去我们增加了标准连接限制。 也许-是时候再次增加它们了。
事实证明,由于在我们的服务器上安装了OpenSSH 7.2,所以
MaxStartups中设置的限制的唯一方法是切换到
Debug调试级别。 通过这种方法,大量数据落入日志中。 因此,我们简要地在其中一台服务器上打开了此模式。 幸运的是,在几分钟后,很明显,连接数超过了
MaxStartups设置的限制,从而导致了早期断开连接。
事实证明,OpenSSH 7.6(此版本随Ubuntu 18.04一起提供)组织了一种更方便的方法来记录与
MaxStartups相关的
MaxStartups 。 在这里,您只需要切换到
Verbose日志记录模式。 尽管不理想,但它仍然比切换到“
Debug级别更好。
课程编号3。 在标准日志记录级别上将有趣的信息写入日志是一种很好的形式,而由于任何原因而有意断开的信息对于系统管理员而言无疑是有趣的。
现在,我们已经找到了问题的根源,出现了如何解决它的问题。 我们可以增加
MaxStartups参数中的值,但是要花多少钱呢? 当然,这将需要一些额外的内存,但是会在处理请求的系统部分中导致任何不利后果吗? 我们只能考虑一下,因此我们决定采用并尝试新的
MaxStartups设置。 即,我们将它们交换为以下内容:150:30:300。 以前,它们看起来像100:30:200,即-我们将连接数增加了50%。 这对系统产生了强大的积极影响。 同时,未观察到某些负面影响,例如增加了处理器的负载。
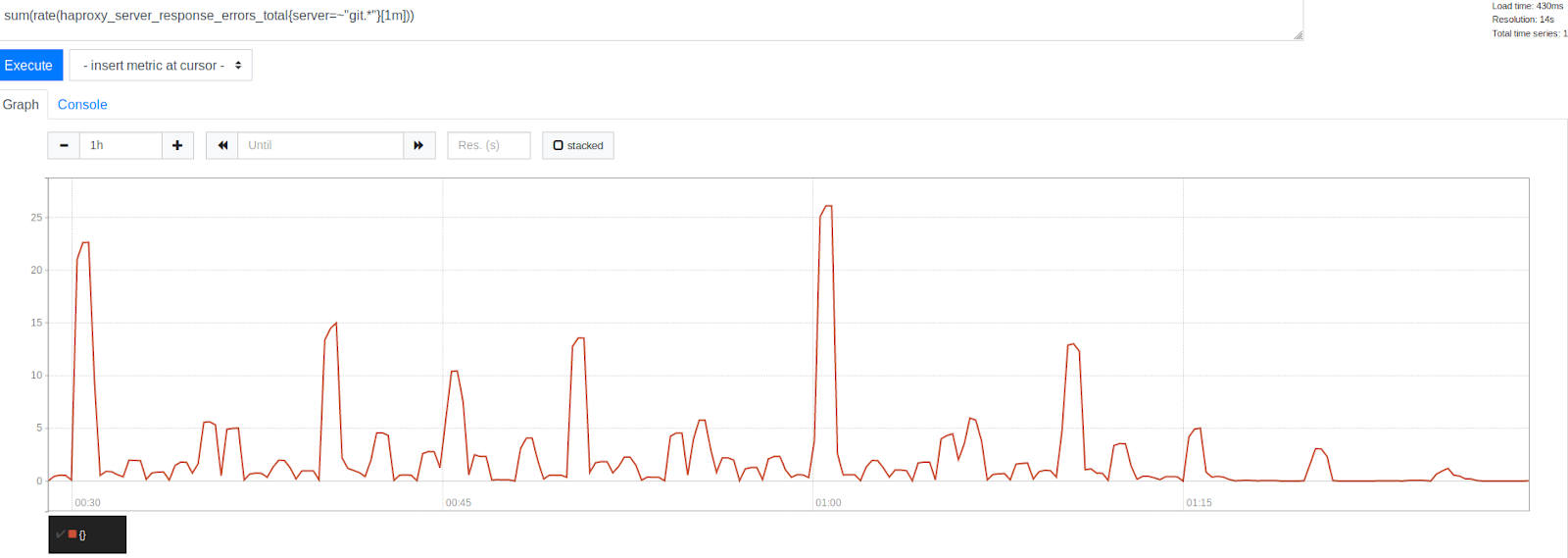 将MaxStartups增加50%之前和之后的错误数量
将MaxStartups增加50%之前和之后的错误数量请注意,在1:15时间戳记之后,错误的显着减少。 这显然表明我们能够消除很大一部分错误,尽管其中有些仍然存在。 有趣的是,错误以美丽的整数表示的时间戳分组。 这是每小时的开始,每30、15和10分钟一班。 毫无疑问,手表的暴政仍在继续。 在每个小时的开始,观察到最高的错误峰值。 鉴于我们已经弄清了这一点,这看起来是可以理解的。 许多人只是计划在每小时开始的0分钟后每小时运行一次任务。 这一事实证实了我们的理论,即错误峰值是由计划任务的启动引起的。 这表明我们在通过调整系统限制来解决问题的正确道路上。
令我们高兴的是,更改
MaxStartups限制不会导致明显的负面影响。 SSH服务器上的CPU使用率与以前大致相同,我们系统上的负载也没有增加。 考虑到我们现在接受了更多的连接,这非常好,而那些连接本来就已经中断了。 此外,当我们在系统负载很重的时候执行此操作并没有使情况恶化。 一切看起来都充满希望。
待续...
亲爱的读者们! 您使用什么工具来分析流量和日志?
