在Internet上,验证码仍然保持相关性,作为一种选择,通过单击相应的按钮,可以从图像中收听文本。 如果有人熟悉下面的图片和/或对如何使用离线声音识别系统解决问题感兴趣,建议您阅读它。
我们不会折磨语音识别领域的专家的好奇心,立即指出,尚未开发出用于指定目的的专有语音识别系统。 本文使用了良好的旧Pocketsphinx,但具有一定程度的自定义。
准备工作
“您进入在计算机上具有语音控制功能的竞争对手的办公室,大喊“ Sudo Era减去Eref Home”,然后逃跑。” 从评论。
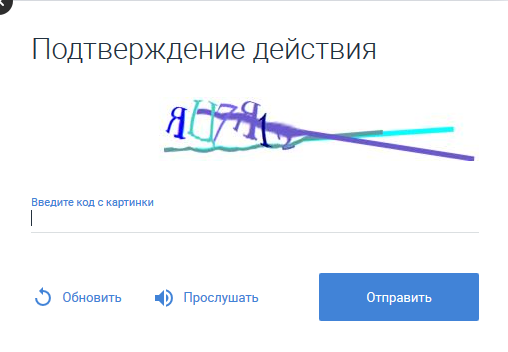
因此,验证码可以通过单击相应的按钮来聆听自己的声音。 如果保存生成的声音文件,则可以找到.mp3中的一小段音频。 同时,事实证明,验证码以女性或男性的声音提供。 男人和女人发出的相同声音的“绘画”是不同的:
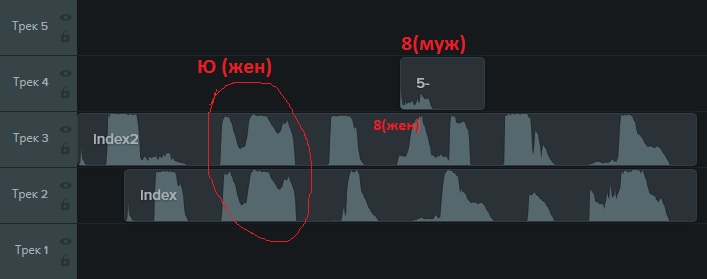
他们听起来既字母(又俄语)和数字。
乍一看,一切都令人难过。 但是有一个积极的一点是,相同字母的声音是一致的。
到目前为止,这些知识没有太大帮助。 如何将所有这些内容推送到Sphinx的包装中?
安装Pocketsphinx,俄罗斯的声音模型
*在哈布雷(Habré)上有
一篇文章 ,其中通过重定向声音输出将声音在线输入到Google翻译。 如果所有这些都适用于本案例,那么这可以结束这篇文章。
在Windows(以及Linux)上安装Pocketsphinx本身并不是很复杂-
下载 ,安装。
由于默认情况下,pocketsphinx随附英语,声学模型,字典,因此俄语也需要全部相同。
下载俄语版本的
链接 。
在文件结构中解压俄语模型后,可以尝试使用以下python代码测试.wav文件解码器-text.wav:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
音频文件的内容应显示在以下行:“ Ilya Ilf Evgeny Petrov Golden Calf”。
如果没有输出(如我的情况),则需要将解码器test.wav转换为另一种音频格式。
您将为此需要ffmpeg。
ffmpeg
下载ffmpeg实用程序后,将解码器-test.wav放在C:\ python3 \ ffmpeg \ bin中。
接下来,转换命令行:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
接下来,用python代码修复到源音频文件的链接:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
现在,在编写代码之后:

没错,您必须等到第二次出现后,代码才能非常缓慢地运行-大约20秒。
我们按照相同的原理将音频验证码从mp3转换为wav,然后从验证码中输入音频。 看一下代码:

某种无知,但有结果。 如果什么也没有提出来,那将更加糟糕。 就像女性的声音一样:

让我们看看如何改善结果并同时加速结果。
词汇量
您将需要自己的字典。 在这种情况下,它将由俄语字母的所有字母(b,s,b除外)和数字组成。
所有字符必须放在纯文本文件中,每行以UTF-8编码。
现在您需要转换字典。
您将需要安装perl(转换器需要它才能工作)。
接下来,下载用于转换
ru4sphinx的项目。
并转换先前创建的字典:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
输出是工作字典:

字典扩展名必须从.txt重命名为.dic格式,并且文件本身应放在可访问的位置。
在python代码中,我们将通过注释掉旧字典来指示字典的位置:
运行该程序并查看结果:

更好,但同样慢,而且并非所有字母都正确识别。
创建自己的模型
这将显着提高工作速度,并降低结果准确性。
让我们从
说明中走一小段路。
通过该
链接将以前以.txt格式(不是.dic!)创建的字典上载到网站:
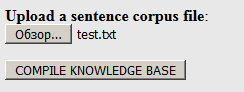
单击“编译...”。 在输出中,您可以将结果包下载到.tgz归档文件中(其中包含所有必要的文件):
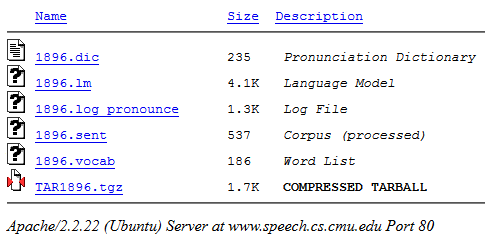
接下来,我们从存档中获取扩展名为.lm(我们的模型)的文件。
让我们通过用新制作的模型替换模型来修复python识别脚本:
我们尝试:

它的工作速度更快-不到一秒钟,此外,所有字母均已定义。
但是这里需要一点说明。
并非所有字符都可以正确识别,并且如果显示的字符不是正确的字母,而不是正确的字母,则可以通过匹配字母的对应关系来手动更正先前创建的.dic词典。
例如,代替字母a,显示e。 有必要从字典e中提取一行:
ry并
转移 (删除旧的),更改字母:
ry但是由于字母“ a”已经在字典中,因此您需要在字母中添加“(2)”(或3,4),通常是一个序列号,具体取决于字典中已有多少声音:
a(2) ry无需重新转换字典。 用这种简单的方法,您几乎可以“拾取”所有字母的音素。
Cherchez la femme
模型和词汇工作,但不带有女性声音。 如果验证码的声音是女性的,那么输出中什么也没有。 这同时是好是坏。 首先讲好。
如果您在启动程序时一无所获,则说明我们正在处理女性声音,因此您可以过滤“女性”验证码。
但是如何处理他们呢?
在这里,您需要进行转换。
例如,使用“男性”验证码时,频率为16000,而对于“女性”验证码则为24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

定义了所有声音(在每一行中都是声音),但是它们的对应关系是la脚的。
最好为女性模型创建一个单独的词典,然后对其进行编辑。
但是,这是自学的。
有用的链接:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2.https://itnan.ru/post.php?C = 1&p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femme档案:
1.
程序 。
2.
模型 。
3.
俄罗斯模式 。
4.
字典 。
5.
测试验证码 。
6.
ffmpeg 。
7.
一包验证码 。