
当前,越来越多的公司将其基础架构从铁服务器和自己的虚拟机迁移到云中。 这样的解决方案很容易解释:无需维护硬件,可以轻松地以多种不同方式配置集群...最重要的是,可用技术(如Kubernetes)使根据负载轻松扩展计算能力变得容易。
财务方面始终很重要。 该工具将在本文中进行讨论,旨在帮助减少在Kubernetes中使用云基础架构时的预算。
引言
Kubecost是一家来自Google移民的加利福尼亚州创业公司,创建了一种解决方案,用于计算云服务(在Kubernetes集群内+共享资源内)的基础架构成本,查找集群设置中的瓶颈并将适当的通知发送给Slack。
通常,在Kubecost支持的所有平台上,我们在熟悉的AWS和GCP云以及稀有的Azure Linux社区中都有Kubernetes的客户。 对于其中一些服务,我们自己考虑群集内服务的成本(使用类似于Kubecost的技术),并监控基础架构成本并尝试对其进行优化。 因此,合乎逻辑的是,我们对自动执行此类任务的能力感兴趣。
Kubecost主模块的源代码在“开放源代码许可”(Apache许可2.0)下打开。 它可以免费使用,并且可用的功能应足以满足小型项目的需要。 但是,企业就是企业:产品的其余部分是封闭的,可以用于
付费订阅 ,这也意味着商业支持。 此外,作者还为小型集群(1个具有
10个节点的集群-在撰写本文时,此限制已扩展到20个节点)提供了免费许可证,或具有全部功能的试用期为1个月。
运作方式
因此,大部分Kubecost是用Go编写的
成本模型应用程序。 描述整个系统的头盔图称为
成本分析器 ,本质上是具有Prometheus,Grafana和几个仪表板的成本模型组件。
一般而言,成本模型具有自己的Web界面,以表格形式显示成本的图表和详细统计信息,当然还有优化成本的技巧。 Grafana中显示的仪表板是Kubecost开发的早期阶段,包含与成本模型几乎相同的数据,并通过有关集群及其组件中CPU /内存/网络/磁盘空间消耗的常规统计信息对其进行补充。
Kubecost如何工作?
- 通过云提供商API的成本模型可以接收服务价格。
- 此外,根据节点的铁类型和区域,考虑节点的成本。
- 根据节点的工作成本,每个最后的Pod会收到每小时使用处理器的成本,花费1 GB的内存以及1 GB的数据存储一个小时的成本-取决于其工作的节点或存储类别。
- 根据各个吊舱的工作成本,考虑为命名空间,服务,部署,StatefulSets付费。
- 为了计算统计信息,使用了kube-state-metrics和node-exporter提供的度量。
请务必注意,
默认情况下 ,Kubecost
仅考虑Kubernetes中可用的资源 。 外部数据库,GitLab服务器,S3存储和不在群集中的其他服务(尽管在同一云中)对它不可见。 尽管对于GCP和AWS,您可以添加服务帐户的密钥并一起计算所有内容。
安装方式
为了使Kubecost起作用,您需要:
- Kubernetes 1.8及更高版本;
- 库伯状态量度;
- 普罗米修斯
- 节点导出器。
碰巧在我们的集群中,所有这些条件都得到了预先满足,因此事实证明,仅指定访问Prometheus的正确端点就足够了。 但是,正式的kubecost Helm-chart包含在裸机集群上启动所需的一切。
有几种安装Kubecost的方法:
- 开发者网站上的说明中描述的标准安装方法,您需要将成本分析器存储库添加到Helm,然后安装图表 。 仅保留转发端口并将设置手动设置为所需状态(通过kubectl)和/或使用成本模型Web界面。
我们甚至没有尝试过这种方法,因为我们没有使用第三方现成的配置,但是它看起来是一个不错的选择,“只为自己尝试一下”。 如果您已经安装了系统的某些组件,或者想要进行更多的微调,则最好考虑第二种方法。
- 使用基本上相同的图表 ,但可以通过任何方便的方式独立配置和安装它 。
如前所述,除了kubecost本身之外,该图表还包含Grafana和Prometheus图表,也可以根据需要进行自定义。
成本分析仪上的values.yaml图表可用于配置:
- 待部署的成本分析器组件清单;
- 您的Prometheus端点(如果已经拥有);
- 成本模型和Grafana的域和其他入口设置;
- 吊舱注释;
- 永久存储的需求及其大小。
文档中提供了可用配置选项的完整列表以及说明。
由于基本版本中的kubecost无法限制访问,因此您需要立即为Web面板配置basic-auth。
- 仅安装系统的核心 -成本模型。 为此,必须在集群中安装Prometheus,并在Helm的
prometheusEndpoint变量中指定其地址的相应值。 之后,在群集中应用YAML配置集。
同样,您必须使用basic-auth手动添加Ingress。 最后,您需要添加一个部分以在Prometheus配置的extraScrapeConfigs中收集成本模型指标:
- job_name: kubecost honor_labels: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http dns_sd_configs: - names: - < kubecost> type: 'A' port: 9003
我们得到什么?
完整安装后,我们将为您提供Web面板kubecost和Grafana以及一组仪表板。
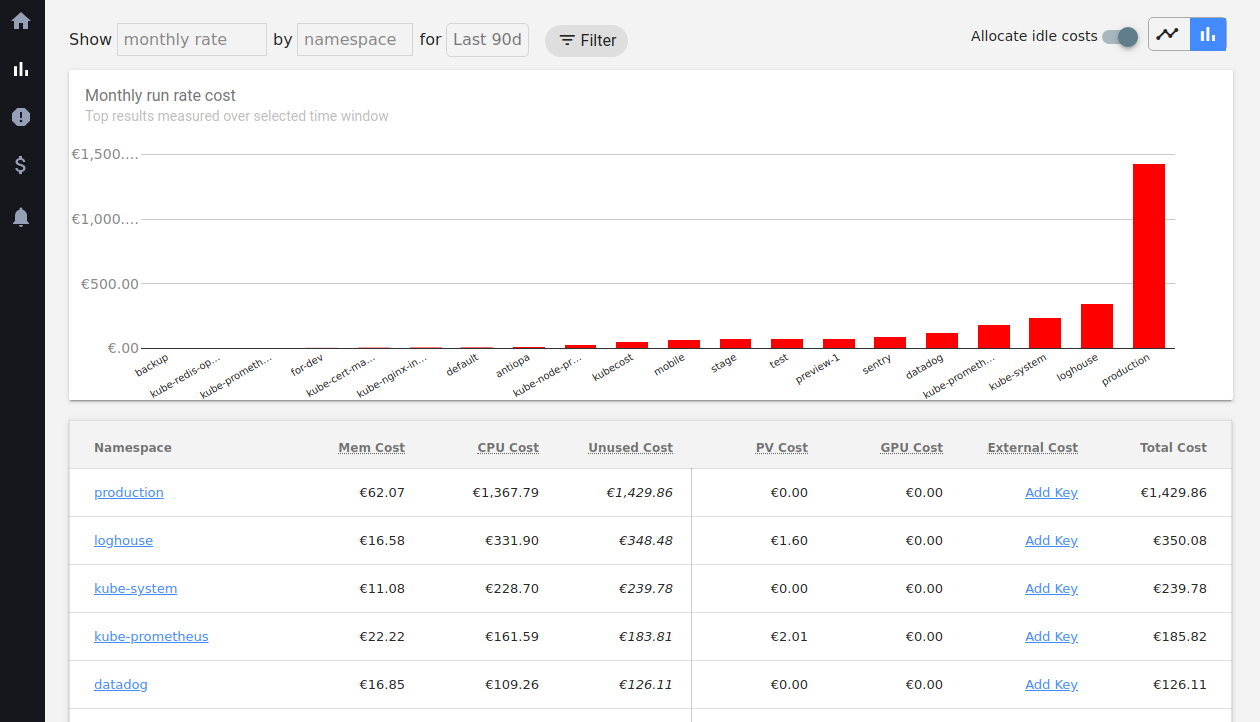
主屏幕上显示
的总成本实际上显示了当月的资源估计成本。 这是
预测价格,显示在当前资源消耗水平下使用群集的成本(每月)。
该指标更多地用于成本分析和优化。 在kubecost中观看抽象7月的总费用并不是很方便:您必须
为此付费 。 但您可以看到按名称空间,标签,广告连播划分的1/2/7/30/90天的费用,这些费用永远不会向您显示。
说起
标签 。 您应该立即进入设置并设置标签名称,这些标签将用作分组成本的其他类别:
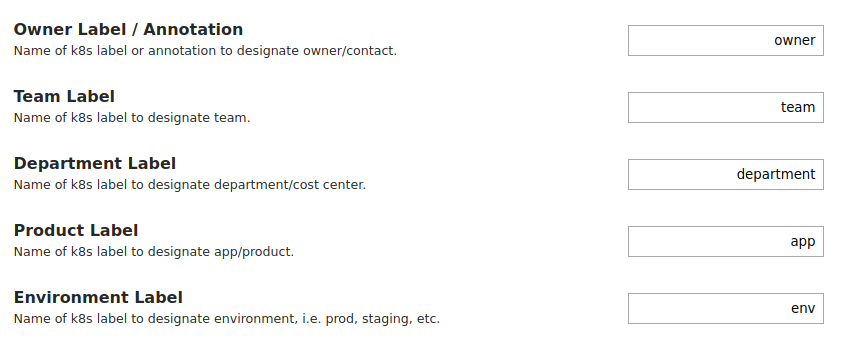
您可以在标签上悬挂任何标签-如果您已经拥有自己的标签系统,这将非常方便。
您还可以在此处更改成本模型所连接的终结点API地址,在GCP中配置折扣大小,并为资源和货币设置自己的价格以衡量它们(由于某些原因,该功能不会影响总成本)。
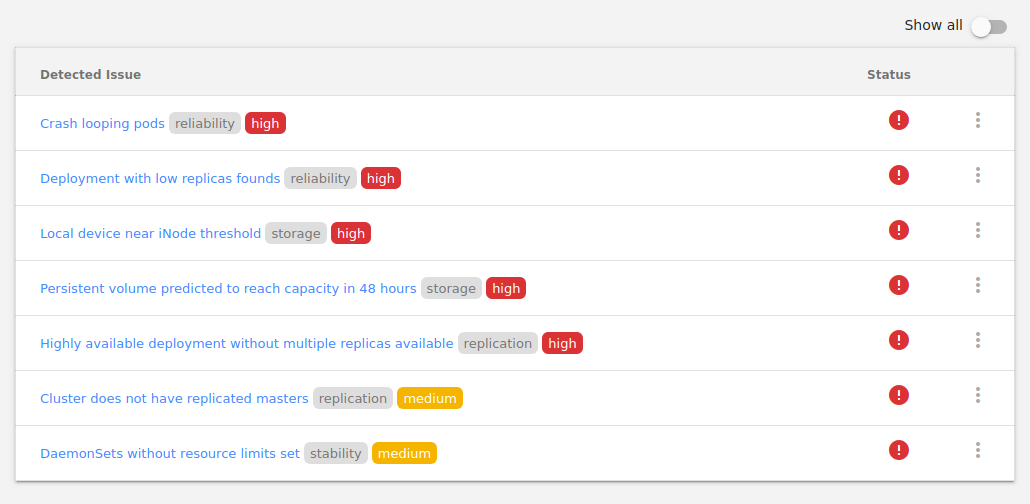
Kubecost可以
在集群中显示各种
问题 (甚至在发生危险时发出警报)。 不幸的是,该选项不可配置,因此-如果您具有开发人员环境并且使用了它们,则可以不断观察到以下内容:
一个重要的工具是
集群节省 。 它测量了pod的活动(资源消耗,包括网络),还考虑了多少钱和可以节省多少。
优化提示似乎很明显,但是经验表明仍然有一些需要注意的地方。 特别是,监视Pod的网络活动(Kubecost提供对非活动状态的注意),比较请求的内存和实际的内存以及CPU的使用情况,以及集群节点使用的CPU(将多个节点折叠成一个),磁盘负载和几十个参数。
与任何优化问题一样,必须
谨慎对待基于Kubecost数据的资源优化。 例如,Cluster Savings建议删除节点,声称它是安全的,但并未考虑节点选择器和部署在其上的Pod上的污点(其他节点上不存在)的存在。 无论如何,即使是产品的作者在
最近的文章中 (顺便说一句,对于那些对项目主题感兴趣的人也可能非常有用)建议不要急着进行成本优化,而要认真解决这个问题。
总结
在几个项目上使用kubecost一个月后,我们可以得出结论,这是一个有趣的(甚至易于学习和安装)的工具,用于分析和优化用于Kubernetes集群的云提供商的成本。 计算非常准确:在我们的实验中,它们与提供者的实际要求相符。
并非没有缺点:存在一些非关键错误,某些地方的功能无法满足某些项目的特定要求。 但是,如果您需要快速了解资金的去向和可以“削减”的内容以将云服务的账单稳步降低5-30%(在我们的案例中是这种情况),那么这是一个不错的选择。
聚苯乙烯
另请参阅我们的博客: