你好 从标题开始,您已经了解了我要谈论的内容。 会有很多硬核:
我们将讨论Java,C,C ++,汇编器,一些Linux,一些操作系统的内核。 我们还将分析一个实际案例,因此本文将分为三大部分(非常多)。
首先,我们将尝试从现有的探查器中挤出所有内容。
在第二部分中,我们将创建自己的小型探查器,而在第三部分中,我们将介绍如何对不常用的内容进行探查,因为现有工具不太适合。 如果您准备好采用这种方式-我正在等待您的到来:)
目录内容
时间和理解方式-探查器
从日常角度来看,1秒很小。 但是我们知道1秒是整整十亿纳秒。 让它在1纳秒内花费大约4个处理器周期,在1秒钟内,计算机中完成了许多事情,这些事情可以改善或恶化我们的生活。
假设我们正在开发一个本身对加速至关重要的应用程序,对于某些代码片段,这通常是至关重要的。 例如,这些片段的执行速度为数百微秒-足够快,但是它们[
代码段 ]直接影响我们应用程序的成功以及所赚取或损失的金额。 举个例子
当发送订单以完成交换交易时,延迟100微秒可能会使交换交易每笔交易损失100万卢布或更多,这是由一个,而不是两个,甚至不是一百个完成的。
并且为我设定了
任务 :一方面,您需要同时发送所有订单,另一方面,发送它们,以使第一个和最后一个之间的差异最小。 也就是说,有必要分析将订单发送到交易所的功能。 除了一个细微差别外,一项典型任务是:该功能的特征执行时间
明显少于100μs 。
让我们考虑一下如何对这100μs进行分析,以了解内部发生了什么。
选择此工具时应考虑什么?
- 我们感兴趣的那部分代码很少执行,即每秒执行一次100微秒。 这是在测试台上,而在生产中则更少。
- 这段代码将很难隔离成一个微基准,因为它影响了项目的很大一部分,甚至影响了通过网络的输入/输出。
- 最后,最重要的是,我希望生成的概要文件与生产服务器上的行为相对应。
我们如何考虑所有这些细微差别并正确描述感兴趣的方法?
从概念上讲,所有探查器都可以分为两组探查
器或
采样器 。 让我们分别考虑每个组。
工具分析器会占用大量开销,因为它们会修改我们的字节码并在其中插入时序记录。 因此,此类探查器的主要缺点是:它们可能会严重影响可执行代码。 结果,很难说出结果配置文件与生产服务器上的行为相匹配的程度:某些优化可能会有所不同,有些会发生,有些则不会。 也许,在其他时间范围(秒,分钟,小时)上,我们将获得代表性数据。 但是,在100μs的范围内,触发或失败的优化可能导致配置文件完全不具有代表性。 因此,让我们仔细看看另一组探查器。
采样探查器会产生最小或中等的开销。 这些工具不会直接影响可执行代码,它们的使用需要您多加注意。 因此,我们将详细介绍采样分析器。 让我们看看我们将从它们那里接收什么数据以及以什么形式。
采样分析器如何工作?
要了解采样探查器的工作原理,请考虑以下示例
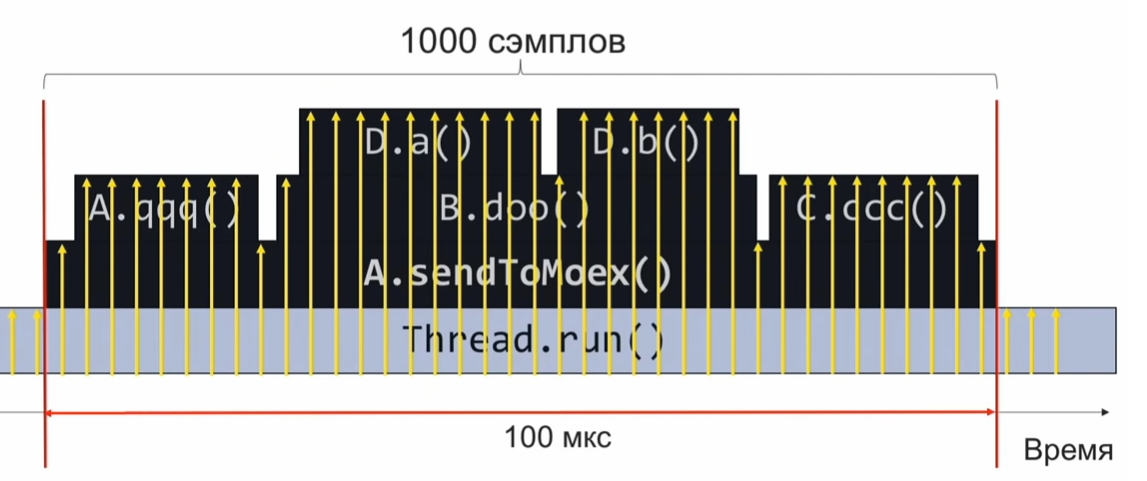
-sendToMoex方法调用其他几个方法。 我们看:
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
如果我们在执行程序的此部分时监视调用堆栈的状态并定期进行记录,我们将以大约以下形式获取信息:

这是一组调用堆栈。 假设样本均匀分布,则相同堆栈的数量表示位于堆栈顶部的方法的相对执行时间。
在此示例中,Da方法的执行量与C.ccc方法一样多,是Db方法的2倍之多。但是,假设样本分布均匀甚至是不完全正确的假设,则执行时间的估计将是不正确的。
我们需要多久采样一次?
假设我们想在100微秒内进行1000个采样,以了解内部播放的内容。 接下来,我们以简单的比例进行计算,如果我们需要在100μs内完成1000个采样,那么在1秒内就是1000万个采样或10,000,000个采样/秒。
如果我们以这种速度采样,那么在代码的一次执行中,我们将收集1000个采样,进行汇总并了解快速或缓慢的工作方式。 之后,我们将分析性能并调整代码。
但是,每秒1000万个样本的频率很高。 如果我们从一开始就无法实现这种分析速度? 假设我们仅在10μs内收集了10个样本,而不是1000个。在这种情况下,我们需要等待下一次执行配置代码,这将在1秒后发生(毕竟,配置代码每秒执行一次)。 因此,我们将再收集10个样本。 由于它们与我们平均分配,因此可以将它们组合成一个公共集合。 只需等到概要代码执行1000/10 = 100次,就足够了,我们将收集所需的1000个样本(每100次中有10个样本)。
选择一个探查器
有了这些理论知识,让我们继续练习。
以
异步分析器。 一个很棒的工具(使用AsyncGetCallTrace虚拟机调用)可以收集调用堆栈,直到Java虚拟机的字节码指令为止。 本地异步配置程序采样率是
每秒1000个样本 。
我们将解决一个简单的比例:10,000,000个样本/秒-1秒,1000个样本/秒-X秒。
我们以async-profiler的标准采样频率得到的结果是,分析大约需要3个小时。 这是很长时间了。 理想情况下,我想以超光速最快地组装轮廓。
让我们尝试超频
Async-profiler 。 为此,在自述文件中,我们找到了
-i标志,该标志设置了采样间隔。 让我们尝试设置
-i1标志(1纳秒)或通常设置为
-i1 ,以便探查器不停止采样。 我每秒获得约2.5千个样本的频率。 在这种情况下,分析的总持续时间将约为1小时。 当然不是3个小时,而且也不是很快。 为了达到所需的配置速度,您似乎需要做一些本质上不同的事情,以达到新的水平。
为了获得更高的频率,您将不得不放弃AsyncGetCallTrace调用,而使用
perf ,这是每个Linux发行版中都提供的全时Linux分析器。 但是,perf对Java一无所知,我们还没有训练过perf来使用Java。 同时,让我们尝试以这种可怕的方式运行perf:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
有关符号的更多信息- 性能记录意味着我们要记录一个配置文件。
-F标志和参数10,000是采样率。-p标志指示我们只想分析Java进程的特定PID。-g标志负责收集调用堆栈。- 最后,对于睡眠1,我们将配置文件条目限制为1秒。
为什么我们需要收集调用堆栈? 我们连续分析所有内容,然后从收集的数据中提取出我们感兴趣的部分(负责形成和发送订单的方法)。 收集的样本属于我们感兴趣的数据的标记是
sendToMoex方法
调用的堆栈框架的存在。
学习perf来构建Java应用程序概要文件。
我们执行perf record ...命令,等待1秒钟,然后运行perf脚本以查看已分析的内容? 我们会看到一些不太清楚的东西:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
它似乎是地址,但是没有Java方法的名称。 因此,您需要教perf将这些地址与方法的名称进行匹配。
在C和C ++的世界中,所谓的调试信息用于匹配地址和函数名称。 对应关系存储在可执行文件的特殊部分:一种方法位于此类地址,另一种方法位于其他地址。 Perf提取此信息并进行映射。
显然,虚拟机JIT编译器不会以这种格式生成调试信息。 我们还有另一种方法-在特殊的perf-map文件中将有关地址和方法名称的对应关系写入数据,该perf将被视为读取的调试信息的补充。 此性能映射文件必须位于tmp文件夹中,并具有以下数据结构:
第一列是方法代码开头的地址,第二列是它的长度,第三列是方法的名称。
因此,我们需要生成一个类似的文件。 显然,这不能手动完成(我们如何知道JIT编译器将代码放置在哪个地址),因此我们将使用来自perf-map-agent项目的create-java-perf-map.sh脚本,并向其传递Java进程的PID 。 该文件已准备就绪,检查其内容,然后再次运行perf-script。
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
瞧! 我们看到了Java方法的名称! 刚刚发生的事情:我们教了一点不懂Java的性能分析器来分析常规Java应用程序,并查看了该应用程序的热门Java方法!
但是,要分析我们要查询的程序的性能,我们没有足够的调用堆栈来从所有收集的样本中过滤出感兴趣的数据。
如何获得通话堆栈?现在,您需要对perf或虚拟机执行其他操作以获取调用堆栈。 要了解需要做什么,让我们退后一步,看看堆栈通常是如何工作的。 想象一下,我们有三个函数f1,f2,f3。 此外,f1调用f2,f2调用f3。
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
在执行函数
f3 ,让我们看看堆栈处于什么状态。 我们看到
rsp寄存器,它指向堆栈的顶部。 我们也知道堆栈具有先前堆栈帧的地址。 我如何获得调用堆栈?
如果我们能够以某种方式获得该区域的地址,那么我们可以将堆栈想象成一个简单的连接列表,并了解将我们带到当前执行点的调用顺序。
为此我们需要什么? 我们需要一个额外的rbp寄存器,该寄存器将指向黄色区域。 事实证明,rbp寄存器允许perf获取调用堆栈,以了解将我们带到当前点的顺序。 我建议在
System V应用程序二进制接口中阅读这些详细信息。 它描述了如何在Linux中调用方法。

我们了解了我们的问题所在。 我们需要强制虚拟机将rbp寄存器用于其原始用途-作为指向堆栈帧开始的指针。 这就是JIT编译器应使用rbp寄存器的方式。 在虚拟机中为此有一个标志PreserveFramePointer。 当我们将此标志传递给虚拟机时,虚拟机将开始使用rbp寄存器实现其传统用途。 然后Perf可以旋转堆栈。 而且我们在配置文件中获得了一个真正的调用堆栈。 该标志是由臭名昭著的Brendan Gregg在JDK8u60中贡献的。
我们用一个新的标志启动虚拟机。 运行
create-java-perf-map ,然后运行
perf record和
perf script 。 现在,我们可以使用调用堆栈构建准确的配置文件:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
我们讲授了大多数Linux发行版中随附的perf profiler,以与Java应用程序一起使用。 因此,现在我们不仅可以看到代码的热门部分,还可以看到导致当前热点的调用顺序。 鉴于perf分析器对Java一无所知,这是一个了不起的成就。 我们刚刚教了perf这一切!
提高性能采样率
让我们尝试将性能超频到每秒1000万个样本。 现在,我们的频率大大降低了。
要使我们刚刚完成的所有任务自动化,您可以使用perf-map-agent项目中的
perf-java-record-stack脚本。 他有一支很棒的笔-环境变量
perf_record-freq ,您可以使用它设置采样频率。 首先,让我们每秒设置10万个样本并尝试运行。 控制台中出现一条可怕的消息,表明我们已经超过了允许的最大采样频率:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
在我的情况下,限制为每秒3万个样本。 Perf立即指出需要修复哪个内核参数,我们可以使用echo sudo tee到所需文件,也可以直接通过
sysctl 。 因此:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
左右:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
现在我们告诉内核,频率上限现在是每秒一百万个样本。 我们再次启动探查器,并指出每秒20万次采样的频率。 探查器将工作15秒,并为我们提供100万个样本。 一切似乎都很好。 至少没有可怕的错误消息。 但是,我们实际上得到了多少频率? 事实证明,每秒只有7万个样本。 怎么了?
让我们看一下
dmesg的输出:
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
这是Linux内核的输出。 它意识到我们采样太频繁了,并且花费了太多时间,因此内核降低了频率。 事实证明,我们需要拧
kernel.perf_cpu_time_max_percent内核中的另一个句柄-称为
kernel.perf_cpu_time_max_percent并控制内核可以花费在perf中断上的时间。
我们将订购每秒20万个样本的采样频率。 15秒后,我们将获得300万个样本-每秒20万个样本。
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
现在让我们看一下个人资料。 运行性能
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
我们看到了奇怪的功能和vmlinux可执行模块-Linux内核。 这绝对不是我们的代码。 怎么了 结果频率如此之高,以至于内核代码开始落入样本中。 也就是说,我们提高频率的频率越高,与我们的代码无关但与Linux内核无关的样本就越多。
死胡同。
我们使用(明确地)硬件PMU / PEBS事件
然后,我决定尝试使用PMU / PEBS硬件技术-性能监控单元,基于精确事件的采样。 它使您可以接收事件已发生给定次数的通知。 这称为“期间”。 例如,我们可能会收到有关处理器执行每20条指令的通知。 让我们来看一个例子。 现在执行xor指令,PMU计数器的值为18; 然后是mov指令-计数器为19; 然后下一条指令,
添加%r14,%r13 ,PMU将显示为“ hot”。
然后一个新的循环开始:
inc被执行-PMU重置为1。循环又进行了几次迭代。 最后,我们在
mov指令处停止,PMU捕捉19。下一个add语句,然后再次将其标记为hot。 查看清单:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
没注意到古怪吗? 五个指令的循环,但是每次我们将同一指令标记为热指令。 显然,事实并非如此:所有指令都是“热门”的。 他们也花时间,我们只标记一个。 事实是,在周期与迭代次数的计数器之间,我们有一个共同的因数4。事实证明,每四次迭代,我们会将同一条指令标记为“热”。 为避免这种情况,您需要选择一个数字作为周期,以使循环中的迭代次数与计数器本身之间的因数相等的可能性最小。 理想情况下,该时期应该是黄金时期,即 仅在您自己和本机上共享。 对于上面的示例:您应该选择一个等于23的时间段。然后,我们将本周期中的所有指令平均标记为“热”。
至少从2009年开始,就以现代形式支持PMU / PEBS技术,也就是说,几乎所有计算机都可以使用它。 为了明确地应用它,让我们修改
perf-java-record-stack脚本。 用
-e替换
-F标志,该标志显式指定使用PMU / PEBS。
... sudo perf record -F $PERF_RECORD_FREQ ... ...
转换脚本:
... sudo perf record -e cycles –c 10007 ... ...
您已经知道期间应具有的属性-我们需要一个质数。 对于我们的情况,它将是周期10007。
他们启动了修改后的perf-java-record-stack脚本,并在15秒内获得了450万个样本-每秒近30万个样本,每3微秒一个样本。 也就是说,对于我们的配置文件代码的一次执行,在100μs内,我们将收集33个样本。 在此频率下,概要文件收集的总时间仅为30秒。 甚至不要喝一杯咖啡! 实际上,一切都有些复杂。 如果我们的代码不是每秒执行一次,而是每5秒执行一次,会发生什么? 然后,分析的时间将增长到2.5分钟,这也是相当不错的结果。
因此,您可以在30秒内获得一个完全满足我们所有研究需求的配置文件。 胜利的
但是,一些肮脏的把戏的感觉并没有离开我。 让我们回到每5秒执行一次代码的情况。 然后,分析将需要150秒,在此期间,我们将收集大约4,500万个样本。 其中,我们仅需要1000个,即所收集数据的0.002%。 其他所有内容都是垃圾,这会减慢其他工具的工作并增加开销。 是的,问题已经解决,但额头,肮脏,钝的力量已解决。
那天晚上,当我第一次在perf的帮助下获得如此详尽的简介时,我做了一个梦。 我要下班回家并思考,但是如果熨斗能够组装轮廓本身,甚至达到组装微结构和微秒的精度,那也很好,我们只能分析结果。 我的梦想会成真吗? 你觉得呢
简短摘要:
- 要使用perf构建Java应用程序的配置文件,您需要使用perf-map-agent项目中的脚本生成一个文件,其中包含有关符号的信息
- 为了不仅收集有关代码的热门部分的信息,而且还收集有关堆栈的信息,您需要使用-XX:+ PreserveFramePointer标志运行虚拟机。
- 如果要增加采样频率,则应注意sysctl'i和kernel.perf_cpu_time_max_percent和kernel.perf_event_max_sample_rate。
- 如果来自内核的与应用程序无关的样本开始进入配置文件,则应考虑明确指定PMU / PEBS周期。
本文(及其后续部分)是报告的抄本,以文本形式改编。 如果您不仅想阅读而且还希望了解概要分析,那么可以
参考该演示文稿。