在移动应用程序中,搜索功能非常流行。 而且,如果它在小型产品中可以忽略不计,那么在提供访问大量信息的应用程序中,您将无法进行搜索。 今天,我将告诉您如何在Android程序中正确实现此功能。

在移动应用程序中实现搜索的方法
- 搜索作为数据过滤器
通常,它看起来像某个列表上方的搜索栏。 也就是说,我们只过滤完成的数据。 - 服务器搜索
在这种情况下,我们将整个实现交给服务器,而应用程序则充当瘦客户端,只需要将其以正确的形式显示数据即可。 - 综合搜索
- 该应用程序包含大量各种类型的数据;
- 该应用程序可以离线工作;
- 需要将搜索作为对应用程序的部分/内容的单个访问点。
在后一种情况下,SQLite内置的全文本搜索可以解决。 使用它,您可以非常快速地找到大量信息中的匹配项,这使我们能够在不牺牲性能的情况下对不同的表进行多次查询。
考虑使用特定示例实现这种搜索。
资料准备
假设我们需要实现一个显示
themoviedb.org中的电影列表的应用程序。 为了简化(以免上线),请拍摄电影列表并从中形成JSON文件,将其放入资产中并在本地填充我们的数据库。
JSON文件结构示例:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
数据库填充
SQLite使用虚拟表来实现全文搜索。 从表面上看,它们看起来像常规的SQLite表,但是对它们的任何访问都会做一些后台工作。
虚拟表使我们可以加快搜索速度。 但是,除了优点之外,它们还具有缺点:
- 您不能在虚拟表上创建触发器;
- 您不能对虚拟表执行ALTER TABLE和ADD COLUMN命令;
- 虚拟表中的每个列都已建立索引,这意味着资源可能浪费在索引列上,而这些列不应该包含在搜索中。
要解决后一个问题,您可以使用包含部分信息的其他表,并在虚拟表中存储指向常规表的元素的链接。
创建表与标准表略有不同,我们使用关键字
VIRTUAL和
fts4 :
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
评论fts5版本它已经被添加到SQLite中。 此版本效率更高,更准确,并且包含许多新功能。 但是由于Android的碎片化,我们不能在所有设备上都使用fts5(API24提供)。 您可以为不同版本的操作系统编写不同的逻辑,但是这将使进一步的开发和支持严重复杂化。 我们决定采用更简单的方法,并使用大多数设备支持的fts4。
填充与平常没有什么不同:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
基本版本
执行查询时,使用
MATCH关键字代替
LIKE :
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
为了在界面中实现文本输入处理,我们将使用
RxJava :
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
结果是一个基本的搜索选项。 在第一个元素中,在说明中找到了所需的单词,在标题和描述中找到了第二个元素。 显然,以这种形式还不清楚我们发现了什么。 让我们修复它。
添加重音
为了提高搜索的明显性,我们将使用辅助功能
SNIPPET 。 它用于显示在其中找到匹配项的格式化文本片段。
snippet(movies, '<b>', '</b>', '...', 1, 15)
- 电影-表格名称;
- <b&gt和</ b>-这些参数用于突出显示已搜索的文本部分;
- ...-对于文本的设计,如果结果是不完整的值;
- 1-从中分配文本的表格的列号;
- 15是包含在返回的文本值中的大约单词数。
该代码与第一个相同,不包括请求:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
我们再试一次:
结果比以前的版本更清楚。 但这还不是终点。 让我们的搜索更加“完整”。 我们将使用词法分析并突出显示搜索查询的重要部分。
完成改善
SQLite具有内置标记,可让您执行词法分析并转换原始搜索查询。 如果在创建表时我们未指定特定的标记生成器,则将选择“简单”。 实际上,它只是将我们的数据转换为小写并丢弃不可读的字符。 它不太适合我们。
为了在搜索上进行质量改进,我们需要使用
词干 -查找给定源词的
词库的过程。
SQLite具有使用Porter Stemmer算法的附加内置标记器。 该算法顺序应用许多特定规则,通过截断结尾和后缀来突出显示单词的重要部分。 例如,当搜索“键”时,我们可以获得包含单词“ key”,“ keys”和“ key”的搜索。 我将在最后留下指向该算法的详细描述的链接。
不幸的是,SQLite内置的令牌生成器仅适用于英语,因此对于俄语,您需要编写自己的实现或使用现成的开发。 我们将从
algorithmist.ru网站获取完成的实现。
我们将搜索查询转换为必要的形式:
- 删除多余的字符。
- 将短语分解成单词。
- 跳过词干分析器。
- 收集搜索查询。
波特算法 object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
将短语分解为单词的算法 val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
转换后,短语“庭院和幽灵”看起来像“庭院
*或幽灵
* ”。
符号“
* ”表示将通过出现给定单词来进行搜索。 “
或 ”运算符表示将显示结果,其中包含至少一个来自搜索短语的单词。 我们看:
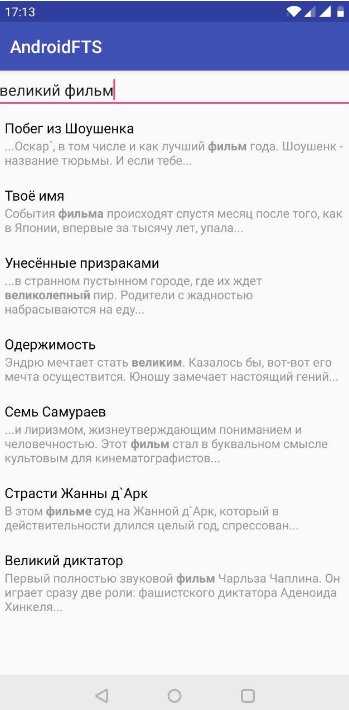
总结
全文搜索并不像乍看起来那样复杂。 我们分析了一个特定的示例,您可以在项目中快速轻松地实现该示例。 如果您需要更复杂的内容,则应查阅文档,因为其中有一个文档,而且编写得很好。
参考文献: