
有很多标题相似的文章,因此,我将尽量避免常见的话题。 我希望即使是经验丰富的开发人员也可以在这里找到有用的东西。 本文将只考虑简单的优化机制和方法,这些方法和方法将使它们以最小的努力来应用。 这些更改不会增加代码的熵。 本文不会关注优化的内容和时间,本文更多地是关于编写代码的方法。
1. ToArray与ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
同意,这是工业项目的非常典型的代码。 但是他怎么了? IEnumerable接口返回一个您可以“遍历”的集合;该接口并不意味着我们可以添加/删除元素。 因此,不需要通过强制转换为列表(ToList)来结束LINQ表达式。 在这种情况下,最好转换为Array(ToArray)。 由于List是Array的包装器,并且此包装器提供了所有其他功能,因此我们切断了接口。 阵列消耗较少的内存,并且访问其值的速度更快。 因此,为什么要多付钱。 一方面,这种优化并不重要,因为他们说“对比赛进行优化”,但这并非完全正确。 事实是,在服务返回表示层模型的典型应用程序中,可能会有无数这样的ToList调用。 在上述示例中,仅出于说明目的引入了IEnumerable接口。 当您需要返回一个以后不会更改的集合时,此方法与所有情况有关。
我预见到这样的评论:在对集合进行多线程访问的情况下,数组和列表将无法等效地工作。 真的是 但是,如果您(作为开发人员)正在考虑对此类集合进行多线程访问并可能对其进行更改的可能性,那么很有可能Array和List都不适合您。
2.“文件路径”参数并非始终是您方法的最佳选择
开发API时,请避免将文件路径作为输入接收的方法签名(以供您的方法稍后处理)。 取而代之的是,提供将字节数组传递给输入的功能,或者
作为最后的流。 事实是,随着时间的流逝,您的方法不仅可以应用于磁盘上的文件,还可以应用于通过网络传输的文件,归档文件中的文件,数据库中的文件以及内容在内存中动态生成的文件等。 e。通过提供一种带有“文件路径”输入参数的方法,您有义务让API的用户在再次读取数据之前将数据保存到磁盘。 这种无意义的操作会严重影响性能。 驱动器是非常慢的事情。 为方便起见,您可以提供一个带有输入参数“文件路径”的方法,但在内部始终使用公共重载方法,该方法在输入处带有字节数组或流。 有一个“标记”可以帮助您找到更多的磁盘写/读操作;请尝试在项目中使用标准方法:
Path.GetTempPath()和
Path.GetRandomFileName() (来自System.IO)。 您很有可能会遇到上述问题或类似问题的解决方法。
细心且经验丰富的读者会注意到,在某些情况下,例如,如果我们正在处理非常大的文件,则写入磁盘可以提高性能。 的确如此,必须加以考虑,但是我认为这是非常罕见的情况,需要特定的实现。
3.避免将线程用作参数以及方法的返回结果
这是什么问题……当我们从某个“黑匣子”中获取信息流时,我们必须牢记其状态。 即 流是开放的吗? 读/写标记在哪里? 不管我们的代码如何,其状态都可以更改吗? 如果将流声明为Stream的基类,则我们甚至都没有关于该流的可用操作的信息。 所有这些都可以通过额外的检查来解决,这是额外的代码和成本。 另外,我反复遇到一种情况,当开发人员从某种“晦涩”的方法接收Stream时,开发人员更喜欢安全地播放它,并将数据“传输”到完全受控的新本地MemoryStream。 虽然,源流可能非常安全。 也许甚至已经为读取MemoryStream做好了准备。 有时它可以达到荒谬的程度-在方法内部,将字节数组放入MemoryStream中,然后将此MemoryStream作为声明为基本Stream的方法的结果返回。 在外部,此Stream变成一个新的MemoryStream,然后ToArray()返回一个字节数组,这是我们最初拥有的。 更确切地说,它将是它的下一个副本。 具有讽刺意味的是,在我们方法的内部和外部,代码是完全正确的。 在我看来,这个例子并非超出我的脑海,而是在商业代码中的某个地方找到的。
因此,如果您有能力发送/接收“干净”数据,请不要为此使用流-不要为将要使用它的用户创建陷阱。 如果您的应用程序已经具有传输/返回流,请根据上述内容分析其使用。
4.枚举的继承
这种优化是司空见惯的,每个人甚至学生都知道。 但是根据我的经验,它很少使用。 因此,默认情况下,enum继承自int。 但是,它可以从保存256个值(或8个“可标记”值)的字节继承。 它几乎总是涵盖“中间”枚举的功能。 代码中的最小更改和枚举的所有值将永远占用更少的内存。 下面是使用从int和byte继承的枚举值填充集合的基准的说明。
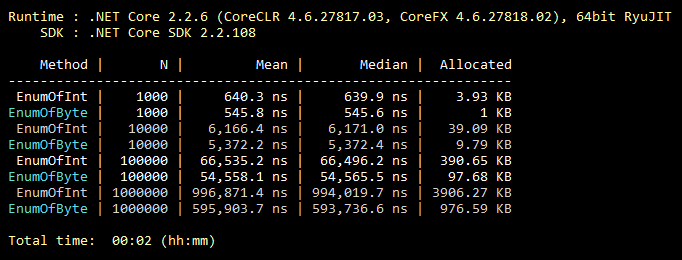
基准代码 public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5.关于Array和List类的更多信息
按照逻辑,在数组上进行迭代总是比在“工作表”上进行迭代更有效,因为“工作表”是对数组进行包装。 同样,遵循逻辑,“ for”总是比“ foreach”快,因为“ foreach”执行了IEnumerable接口实现所需的许多操作。 这里的一切都是合乎逻辑的,但是错了! 让我们看一下基准测试结果:

基准代码 public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random rnd = new Random(); _list = Enumerable.Repeat(0, N).Select(i => rnd.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
事实是,为了遍历数组,“ foreach”不使用IEnumerable实现。 在这种特殊情况下,执行最优化的索引迭代,而不检查数组的越界,因为“ foreach”构造不适用于索引,因此开发人员没有机会在代码中“搞乱”。 这是规则的例外。 因此,如果为了优化起见,在代码的某些关键部分中将“ foreach”的使用替换为“ for”,则您会陷入困境。 请注意,这
仅与array有关。 在StackOverflow上有几个分支讨论了此功能。
6.搜索哈希表是否总是合理的?
每个人都知道哈希表对于搜索非常有效。 但是他们经常忘记快速搜索的价格是对哈希表的缓慢添加。 随之而来的是什么? 为了证明哈希表的使用是合理的,哈希表元素的数量必须至少为8(大约)。 并且搜索操作的数量至少比加法操作的数量大一个数量级。 否则,请使用更简单的集合。 哈希函数的质量将对效率进行自己的调整,但是其含义不会改变。 在我的实践中,有时候加载的代码中的最大瓶颈是调用Dictionary.Add()方法。 密钥是短长度的常规字符串。 记住这一点,并成为编写本段的触发器。 为了说明,一个非常糟糕的代码示例:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
也许您的项目中发生了类似的事情?
7.嵌入方法
出于两个原因,通常将代码分为多种方法。 当一个任务分为多个子任务时,请确保代码重用和分解。 对一个人来说更容易。 内联是分解的逆过程,即 方法代码嵌入在应调用该方法的位置;因此,我们将其保存在调用堆栈和传递参数中。 我绝不建议将所有内容都推入一种方法。 但是,我们可以在理论上“内联”的那些方法可以标记为相应的属性:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
此属性将告诉系统可以嵌入此方法。 这并不意味着标记有该属性的方法将必然是内置的。 例如,不可能嵌入递归或虚拟方法。 还值得注意的是,嵌入机制非常“精致”。 系统会拒绝嵌入您的方法还有许多其他原因。 但是,使用.NET Core的Microsoft团队正在积极使用此属性。 .NET Core的源代码有许多使用示例。
8.估计容量
我(并且我也希望大多数开发人员也能)已经有了一个反思:我初始化了集合-我考虑是否可以为其设置Capacity。 但是,并非总是事先知道收集元素的确切数量。 但这不是忽略此参数的原因。 例如,如果说到您的集合中有多少个元素,而您假设一个模糊的“成千上万个”,这是将Capacity设置为1000的机会。例如,对于默认情况下List的Capacity = 16,有一点理论,因此仅达到1000,系统将额外增加1008(16 + 32 + 64 + 128 + 256 + 512)个元素副本,并创建7个临时数组,以备不时之需。 即 所有这些工作将被浪费。 另外,作为容量,没有人禁止使用该公式。 如果您估计集合的大小是其他集合的三分之一,则可以将Capacity设置为otherCollection.Count /3。设置Capacity时,最好了解集合的可能大小的范围以及其值的分布程度。 总会有伤害的机会,但是如果使用得当,估计的承载能力将为您带来良好的胜利。
9.始终指定您的代码。
积极使用(乍一看,可选)C#关键字,例如:static,const,readonly,sealed,abstract等。 自然,它们在哪里有意义。 这是表演吗? 事实是,您向编译器描述的系统越详细,生成的代码就越优化。 细心且经验丰富的读者可能会注意到,例如,密封关键字对性能没有影响。 现在确实如此,但是在将来的版本中,一切都可能改变。 给编译器和虚拟机一个机会! 获得奖励,在编译阶段发现许多错误使用代码的错误。 一般规则:系统描述得越清晰,结果越理想。 显然,人们也是如此。
真实的故事证实了这一规则,但是如果您阅读懒惰,则可以跳过有一天晚上,在从事
业余项目时 ,他为自己设定了将一段代码的性能提高到一定水平以上的任务。 但是这个网站很短,几乎没有选择该网站的方法。 我在文档中发现,从版本C#7.2开始,“ readonly”关键字可用于结构。 在我的案例中,使用了不可变的结构,通过添加一个单词“只读”,我得到了我想要的,即使有一点空白! 该系统知道我的结构不打算更改,因此能够为我的案例生成更好的代码。
10.如果可能,请对所有解决方案项目使用一种.NET版本
您应努力确保应用程序中的所有程序集都属于同一版本的.NET。 这适用于NuGet软件包(在packages.config / json中编辑)和您自己的程序集(在Project属性中编辑)。 这将节省RAM并加快“冷”启动,因为在应用程序的内存中,不会存在用于.NET不同版本的相同库的副本。 值得注意的是,并非在所有情况下,.NET的不同版本都会在内存中生成副本。 但是,假设在相同版本的.NET上构建的应用程序总是更好。 而且,这消除了本文范围之外的许多潜在问题。 合并您使用的所有NuGet软件包的版本也将有助于提高应用程序的性能。
一些有用的工具
ILSpy是一个免费工具,可让您查看已还原的程序集源代码。 如果我对哪种.NET机制更有效存在疑问,请首先打开ILSpy(而不是Google或StackOverflow),并且已经在这里看到了它是如何实现的。 例如,要找出在性能方面最适合通过HTTP,HttpWebRequest或WebClient类使用的数据,只需查看它们通过ILSpy的实现即可。 在这种情况下,WebClient分别是HttpWebRequest的包装,答案是显而易见的。 .NET源代码由相同的普通程序员编写,因此不必担心。
BenchmarkDotNet是一个免费的基准测试库。 有一个简单直观的秒表(来自System.Diagnostics)。 但是有时候这还不够。 由于以一种很好的方式,有必要考虑的不是单个结果,而是多个比较的平均值,因此最好比较它们的中间值,以最大程度地减少操作系统的影响。 另外,您需要考虑“冷启动”和分配的内存量。 对于此类复杂的测试,创建了BenchmarkDotNet。 .NET Core开发人员在正式测试中使用的正是该库。 该库易于使用,但是如果其作者突然阅读了这篇文章,请提供一个更方便的机会来影响结果表的结构。
U2U Consult Performance Analyzers是Visual Studio的免费插件,它提供了有关在性能方面改进代码的技巧。 100%依靠此分析仪的建议是不值得的。 由于遇到一种建议,这让我有些惊讶,但经过详细分析,结果确实是错误的。 不幸的是,这个例子不见了,所以请多言。 但是,如果您周到地使用它,它将是非常有用的工具。 例如,他将建议使用
myStr.Replace('*', '-')代替
myStr.Replace("*", "-")更有效。 LINQ中的两个Where表达式可以更好地组合为一个。 这些都是“匹配的优化”,但它们易于应用,不会导致代码/复杂性的增加。
总结
如果每10位阅读本文的人将上述方法应用于他的当前项目(或其中的关键部分),并且在将来仍坚持使用这些方法,那么我们可以一起拯救整个森林! 森林??? 即 通过燃烧木材获得的电能形式的计算机系统节省的资源将保持未使用状态。 在这种情况下,“森林”只是某种等效物。 可能得出了一个奇怪的结论,但我希望您对这种想法有所启发。
PS更新基于帖子评论
ToArray优于ToList的优势与.NET Core有关。 但是,如果使用旧的.NET Framework,则ToList对您而言可能更可取。 问题在于,在.NET Framework中,ToArray调用本身比ToList调用慢得多。 而且,更快地访问元素和减少阵列存储可能无法弥补这些损失。 通常,此问题变得更加复杂,因为实现IEnumerable的不同类可能具有不同的效率级别的ToArray和ToList实现。
如果从byte继承的枚举用作类(结构)的成员,而不是单独使用,则可能不会节省任何内存。 由于对齐了该类(结构)所有成员的占用内存。 本文中缺少这一点。 尽管如此,潜在的增益要比没有增益好,因为除了占用的内存之外,还使用了枚举。 因此,第4款仍然有意义,但有这一重要保留。
感谢
KvanTTT和
epetrukhin对这些问题的建设性评论。
而且,正如
Taritsyn所指出的那样,在JIT编译阶段对“密封”关键字的优化仍然存在。 但是,这仅证实了第9段的所有论点。
似乎已考虑到所有建设性意见。 我对这些评论感到非常满意。 由于我自己作为作者收到了反馈,因此我也为自己学习了一些新知识。