有一天,一位数字化专家来到工厂。 他走到这里,走到那里,额头皱了皱眉,说道:“我知道您可以在这里优化一些东西。 您将专门保存! 噢,让我访问这些生产数据。” 作为回应,植物耸了耸肩。 “这里有一位销售分析师。 关于涡轮机,还有一些要说的东西-非常聪明的西门子涡轮机。 对于其余的设备,什么也没有产生。”
您阅读了有关两个世界(行业和分析)冲突的缩影。 我们来自最后一个人,这就是它的寻找方式:一方面,数据交换协议的名称中包含大量数字,这些数字是为设备管理而创建的,普通人无法访问。 另一方面-分析系统,精美的报告,方便的仪表板和其他便利设施。
 并非每种产品都达到了很高的技术水平。 但是每个人都需要帮助。 在照片中,电影“植物”的框架。
并非每种产品都达到了很高的技术水平。 但是每个人都需要帮助。 在照片中,电影“植物”的框架。在本文中,我们将告诉您如何尝试塑造人脸(以简单数据科学家的标准)-使业务分析师能够处理工业数据并使用精美的BI报告。
我们现在有什么
最近,我们正在访问一家气体处理公司。 公司规模较大,拥有多家工厂。 我们走进控制室。 那里的所有设备都非常齐全:每个调度员都有6到8台显示器,墙上有巨大的血浆。 这只是这些等离子体的内容……还有很多不足之处。 Windows窗口上方的窗口上有一张奇怪的地图,愚蠢的箭头,它在可怕的酷刑中幸存下来并显示了一些数字。
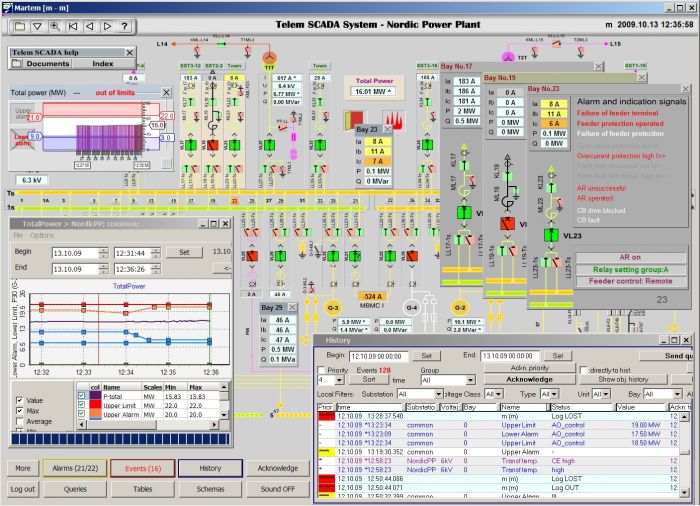
“为什么这么恼火?” -我们问。 我们回应说:“这是我们可以从工业系统中挤出的最佳选择。” 调度员对事件的响应时间通常不应超过30秒,但是使用这样的界面很难满足。 这里没有BI,也没有气味。
另一个非界面的故事。 数据科学家来到工厂说:“将有关安装的数据提供给我们,我们可以以95%的准确性预测其中的问题。” 好吧,至少他们答应了。 他们向该工厂点头,而对于数据科学家而言,该脚本始于卡夫卡的最佳传统。 现场数据收集。 根据一百个系统。 对于每个,您需要编写五个语句。 将个人传记和血统书附在第五膝上。 通过所有分析,将其附加到有关免费主题的文章中,并抓住老板的好心情。 只有这样,我们才能指望成功。 更确切地说,希望。
工厂分析
要解决上述问题,您需要通过分析结识行业朋友。 为此,我们正在构建具有
集成体系结构的单个系统。 这样的系统可以处理完全不同类型的数据,并根据它们解决分析问题。 我们正在构建一个
具有集成体系结构的
系统 ,而不是通用的
体系结构 ,因为通用系统同样严重地解决了所有问题。 在复杂的体系结构中,我们结合了不同类型数据的分析工具。 可能是这样的:
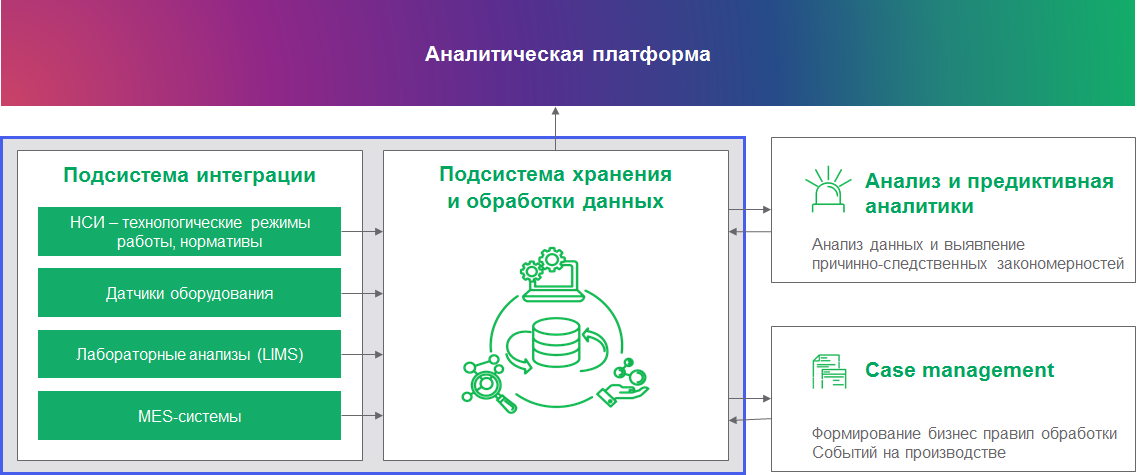
生产中有许多类型的数据。 有来自业务系统和会计系统的经典关系数据。 来自设备传感器的数据-时间序列。 视频分析产生了一些事件-将它们放到dataleyk中,并对其进行集成监视(现在这是一个受欢迎的话题)。 业务系统中有一些日志需要进行索引以进行进一步处理(我们使用Apache Solr),以便在考虑监控摄像头的情况下获得生产中真实情况的真实图像,并评估操作员如何响应某些事件。 不仅如此,每个产品都有自己的需求组合。 最后,所有使用数据的工作都应在单个生态系统中连接,这将允许使用灵活的访问设置和通用分析工具在集中式存储中收集数据。
最近,我们有一个项目:组织对工厂技术模式以及原材料质量的监控。 监控系统必须实时监控所有重要指标,并使用非常原始的公式将它们与标准进行比较。 我们从一个数据库中进行原材料的实验室分析,并从另一个数据库中进行设备性能指标的分析。
结果,操作员可以全面了解安装过程中发生的情况:您需要注意的是,是否值得停止工作以及它有多严重。 对于每次偏离规范工作的情况,操作员都必须确定故障原因。 因此,有关事件的知识有所增长。
同时,所有分析都通过美观,便捷的BI系统显示。 它不仅使您可以构建简单的报告,还可以创建易于理解和直观的信息面板(仪表板)。 这是另一个争论,为什么使工业数据与分析系统成为朋友非常重要。 出于NDA的原因,我们无法显示该项目的仪表板,但为了进行对比,我们提供了一些公开的示例,以可视化BI系统和工业系统。
BI报表可能如下所示:
这是SCADA界面:
作为平台开发的一部分,我们正在考虑连接预测分析,以揭示因果关系模式。 不同的原因导致不同的情况。 例如,原材料质量差或计划维护后设备调整不当会导致最终产品质量下降或设备故障。
分析系统的关键要求之一是信息的接收速度。 这是从传感器收集遥测数据并以近实时模式计算指标(车间的汇总指标的计划/事实)。 这使您可以调整生产的运营管理。
这样的事情在一个勇敢的新世界中起作用。 但实际上有细微差别。
工业数据分析,或生产中的商业智能问题
如何以便于数据分析的形式减少来自工业系统(没人真正收集)的数据? OPC DA / HDA是工业数据的标准协议之一。 它似乎是开放的,但只有联盟成员才能访问其规范。 联盟中的成员资格非常昂贵,并且不存在该协议的稳定的开放实现。
为了
将此协议和其他工业协议与现代分析系统连接起来 ,我们为每个协议创建网关。 这是由一个独立的工业解决方案团队完成的。 协议名称中的大量数字启发了他们。 该团队具有编写工业连接器的经验(例如,使用OPC DA / HDA协议,使用PI SDK等)。
但是,
为了将工业协议与大数据世界联系起来,我们使用Apache NiFi(一种来自Hadoop生态系统的工具),该工具可让您以流处理模式实现集成。
通过在行业和分析之间架起最重要的桥梁,我们能够在熟悉的Hadoop堆栈上解决问题。 在工业项目中,我们最经常使用我们国内合作伙伴Arenadata的发行版。 对于Apache Phoenix,我们使用SQL选择JDBC数据。 在最新版本中,Phoenix已针对在工业项目中经常出现的时间序列进行了优化。
我们能够用一个供应商的产品来关闭复杂的分析系统,这对于企业解决方案而言非常重要。 Apache Spark用于计算设置(设备操作模式中的偏差),计算出的指标和其他KPI(用于在Hadoop生态系统中以近实时模式执行分布式计算的组件)。
细微差别
industrial,工业协议很复杂。 第一次计划与PI集成时,我们希望我们采用其标准的JDBC接口,并能获得简单而快速的满足。 当他们开始使用该接口时,事实证明,其带宽甚至不足以加载当前数据。 更不用说下载故事了。 但是连接器具有自己的内部SDK API,可以快速处理数据。 因此,我们为此API编写了一个特殊的网关,并解决了该问题。
我们以一种最终解决方案的方式来解决问题,最终以展示柜的形式展示了偏差周期。 为此,有必要计算指标超出标准的次数和时间。 如果您分析整个故事以寻找偏差,则将需要大量资源。 因此,我们只是研究了一系列值,比较了每个后续值和上一个值。 如果两者都正常/不正常-没有偏差/继续。 如果两者之一不正常-我们分别计算偏差的开始或结束。 因此,当我们为分析师和技术人员创建带有统计数据的展示柜时,我们能够节省计算能力。
前景展望
这些工业项目的目的不仅是使所有事物变得美丽和清晰,而且还为生产准备了一个分析平台,并转移到了一个数字企业,在那里可以在一个地方收集和分析所有事件。
至于所描述的平台,它一次对多个部门有用。 我们已经解决了生产管理人员的问题。 如果以前的操作员无法对设备操作中的细微偏差做出回应,那么现在他们必须就每次不遵守规范的情况向管理层报告。 此刻提供了价值。 我们为数字化仪和R&D服务提供了有关生产的便捷信息源,这使我们能够分析任何时间段内的任何事件-这将在将来提供价值。
现在,我们正在积极从事此类技术平台的开发,并尝试实施。 总的来说,我们努力将工业从人工控制转移到自动化生产控制,就像Ilon Mask的工厂一样。
我们将很高兴与所有人交谈-与大数据的开发人员和架构师(我们可以邀请我们加入我们的团队),以及与数字化人员,生产经理交流,向他们介绍我们的经验并提供合作的选择。 对于每个人,我们都举行大数据会议,在此我们很高兴讨论所有问题和建议。
我的邮件是EOsipov@croc.ru