哈Ha
本文是
2018年Best Habr文章排名的逻辑延续。 尽管这一年还没有结束,但是如您所知,夏季规则有所变化,因此,看看它是否受到影响变得很有趣。

除了统计数据本身之外,还将提供文章的最新评级,以及一些对它的工作方式感兴趣的人的源代码。
对于那些对发生的事情感兴趣的人,继续进行下去。 那些对网站的各个部分进行更详细分析的人员也可以看到
下一部分 。
源数据
该评级是非官方的,并且我没有任何内部数据。 很容易看到,在浏览器的地址栏中查看时,哈布雷的所有文章都有端到端编号。 接下来是一个技术问题,我们只是在一个周期中连续读取所有文章(在一个线程中并且有暂停,以便不加载服务器)。 这些值本身是通过Python中的简单解析器获得的(源代码在
此处 ),并存储在近似于此类型的csv文件中:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7处理中
为了进行解析,我们将使用Python,Pandas和Matplotlib。 那些对统计数据不感兴趣的人可以跳过此部分,然后立即阅读文章。
首先,您需要将数据集加载到内存中并选择所需年份的数据。
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
事实证明,在撰写本文时,今年(尽管尚未完成)发表了12715篇文章。 为了进行比较,对于整个2018年-15904年。通常来说-每天大约有43篇文章(而且只有积极的评价,有多少篇文章被否定或删除,您只能猜测或粗略地找出其中的遗漏标识符)。
从数据集中选择必要的字段。 作为指标,我们将使用视图,注释,评级值和添加的书签的数量。
def to_float(s):
现在,数据已添加到数据集中,我们可以使用它们了。 按天分组数据并取平均值。
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
现在,对于有趣的部分,我们可以看一下图表。
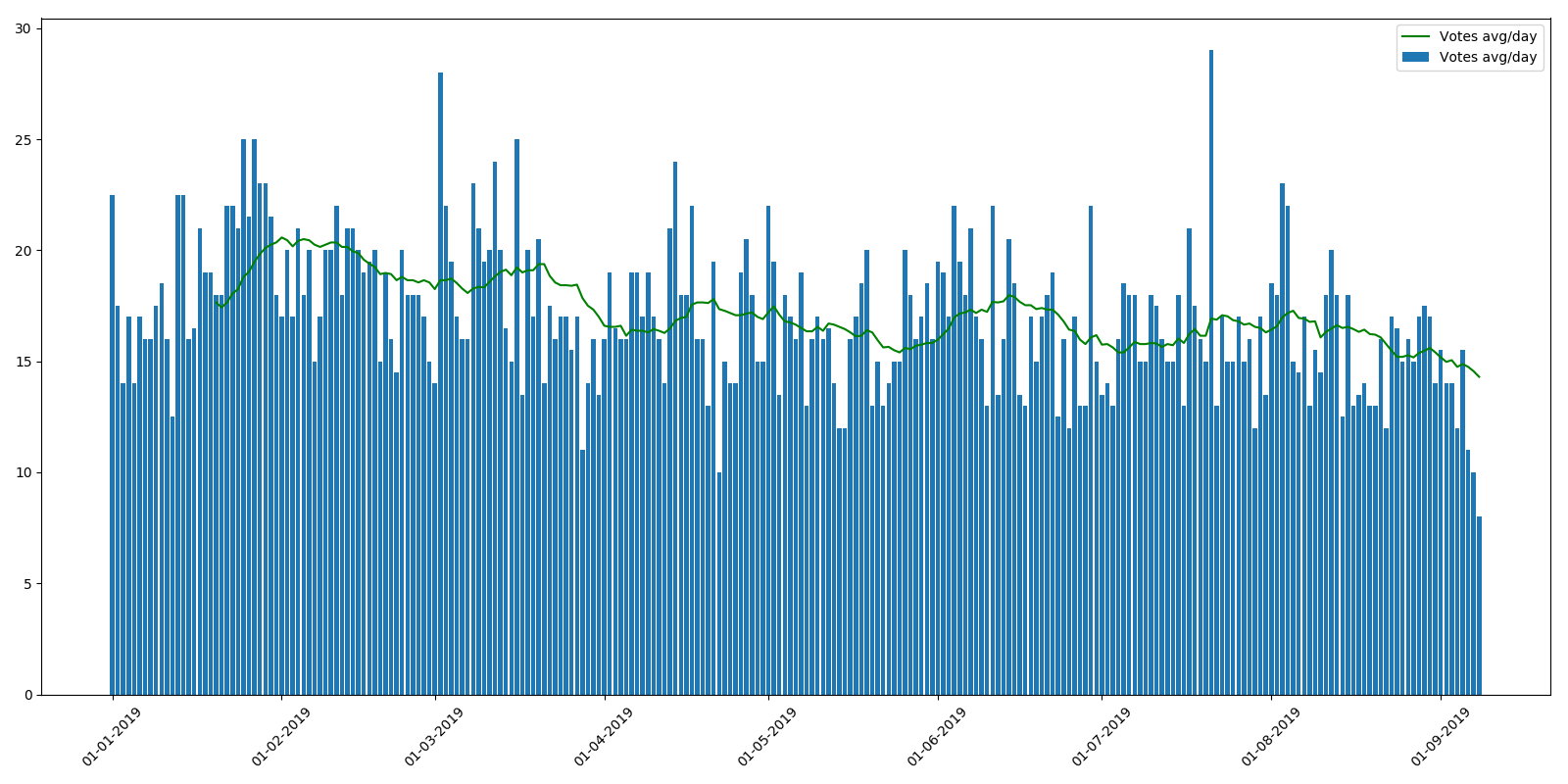
让我们看看2019年在Habré上的出版物数量。
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
结果很有趣。 如您所见,Habr在这一年中略有“香肠”状态。 我不知道原因

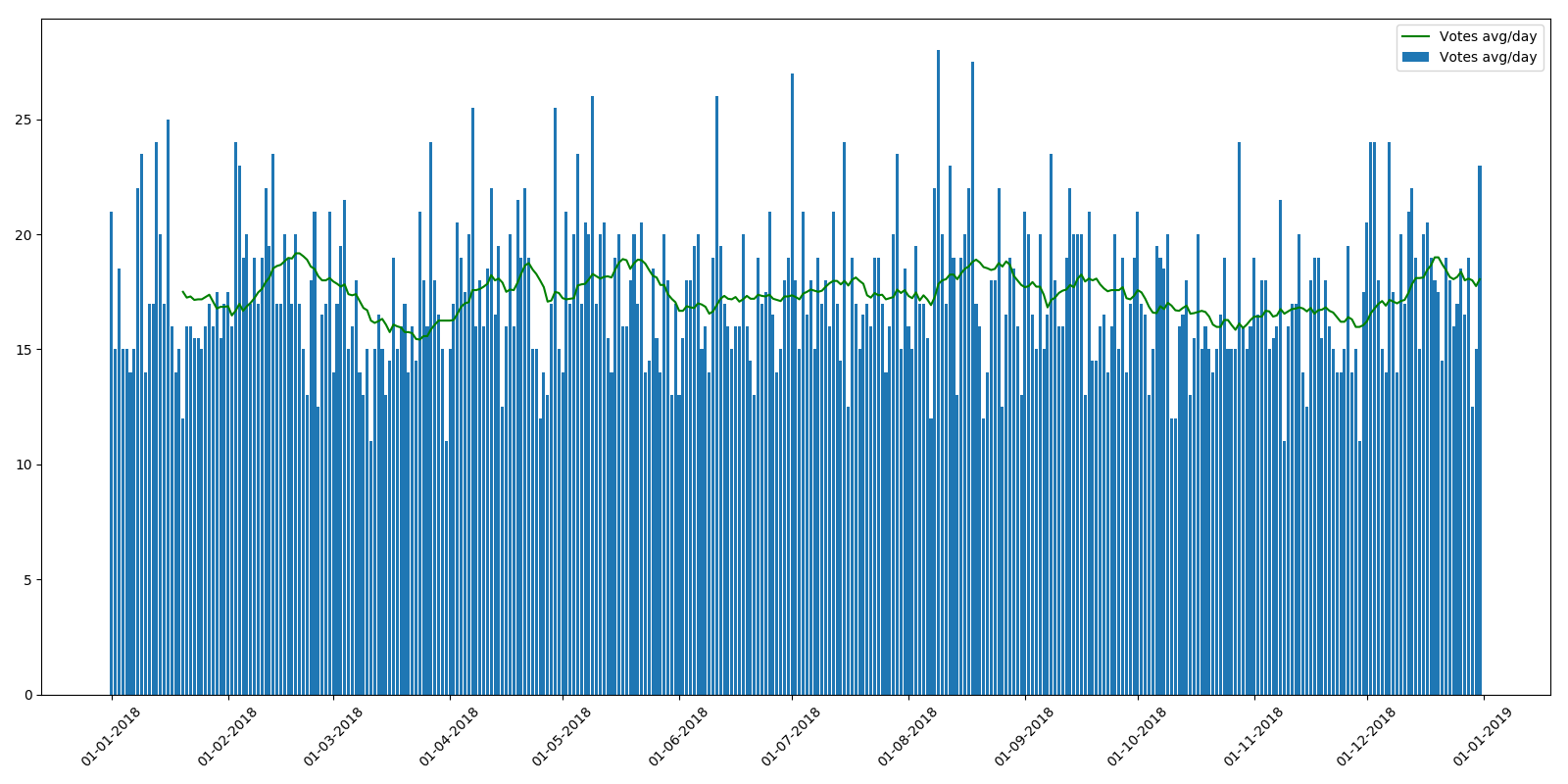
为了进行比较,2018年看起来有些“平滑”:

总的来说,我没有看到图表上2019年已发表文章的数量有任何大幅减少。 而且,相反,自夏天以来似乎甚至略有增长。
但是下面的两个图表使我更加沮丧。
每篇文章的平均观看次数:

每篇文章的平均评分:
如您所见,一年中的平均观看次数略有减少。 可以通过以下事实来解释:新文章尚未被搜索引擎索引,并且它们很少被发现。 但是,每篇文章的平均评分的下降是难以理解的。 感觉是读者要么根本没有时间浏览这么多文章,要么不关注评级。 从作者的奖励计划的角度来看,这种趋势非常令人不快。
顺便说一句,2018年不是这种情况,时间表差不多。
通常,资源所有者需要考虑一些事情。
但是,我们不要谈论悲伤的事情。 总的来说,我们可以说哈伯(Habr)在夏天成功幸免,并且网站上的文章数量没有减少。
等级
现在,实际上是评级。 祝贺那些打他的人。 我再次提醒您,该评分是非官方的,也许我错过了一些内容,如果一定有这篇文章,但不是,请撰写,我将手动添加。 作为评分,我使用计算的指标,在我看来,这很有趣。
热门文章- LED以前所未有的比例说谎 241,000次浏览,569条评论,评分+ 364.0 / -1.0
- ``口交文章'':科学家处理了109个小时的口交以开发出一种AI,吸引了 236,000次查看,361条评论,评分+ 240.0 / -68.0的AI
- 设计师吸烟的东西:不寻常的枪支 235,000次浏览,123条评论,评分+ 119.0 / -9.0
- 我如何在Sberbank呆了一年 233,000浏览次数,580条评论,评分+ 449.0 / -14.0
- 科学家发现了地球上最古老的脊椎动物 221000视图,211条评论,评分+ 82.0 / -14.0
- 扔进垃圾桶的智能灯泡是个人信息的宝贵来源,共有 219,000次查看,147条评论,评分+ 73.0 / -11.0
- 开发王 178,000浏览次数,668条评论,评分+ 315.0 / -60.0
- 欺诈者和EDS-一切都很糟糕 175,000次查看,778条评论,评分+ 356.0 / -0.0
- “切尔诺贝利”系列:观看和思考 172,000次观看,803条评论,评分+ 164.0 / -25.0
- 最差的UI音量控制 166,000次观看,176条评论,评分+ 292.0 / -30.0
- 程序员的诚实履历 165,000次浏览,283条评论,评分+ 410.0 / -40.0
- 我用代码审查破坏了开发人员的生活,对不起 164,000次浏览,12条评论,评分+ 33.0 / -3.0
- Megafon如何在移动订阅上睡觉 162,000次观看,676条评论,评分+ 624.0 / -2.0
- Picaba暴动。 用户去Reddit进行了整体浏览160,000次浏览,484条评论,评分+ 215.0 / -41.0
- 廉价和昂贵的AAA电池 159,000次查看,382条评论,评分+ 363.0 / -6.0
- 退休于 22,156,000观看次数,922条评论,评分+ 259.0 / -100.0
- 没有智能手机的人 152000视图,736评论,评分+ 173.0 / -25.0
- 需要永恒的LED? 发现烙铁和锉刀。 或自制的自制照明 149,000次浏览,262条评论,评分+ 94.0 / -6.0
- 如果手机被盗 144,000次查看,638条评论,评分+ 259.0 / -27.0,则无需执行任何操作
- 2019年2月1日,您的网站可能停止运行 143,000个视图,162个评论,评分+ 89.0 / -8.0
收视率与收视率之比的热门文章- 弱点,第2部分:出版物和其他更改的投票期限是 14000次观看,评分+ 238.0 / -3.0
- 在TeX-e中,欧几里得的幻想非常``开始''10, 800次浏览,评分+ 136.0 / -0.0
- 用户奖励Habr 26400次浏览的作者 ,评分+ 320.0 / -0.0
- 发送出版物中的印刷错误消息 18,900次查看,评分+ 179.0 / -2.0
- 世界,您好! 或Habr英文,v1.0 21,000观看次数,评分+ 178.0 / -2.0
- 粒子上的生命 34,000次观看,评分+ 267.0 / -2.0
- 温泉城文明,5 / 5 25800观看次数,评分+ 201.0 / -1.0
- 我们在机电屏幕上玩俄罗斯方块 16300次观看,评分+ 124.0 / -0.0
- 从CRT屏幕重新创建字体 13,400次浏览,评分+ 101.0 / -0.0
- 游戏的数学模型是Dobble 14600观看次数,评分+ 110.0 / -0.0
- 关于个人资料中邀请的重要信息是 18300次观看,评分+ 137.0 / -8.0
- 削弱哈勃规则中的坚果 48300次观看,评分+ 338.0 / -13.0
- 街头魔术编解码器比较。 我们揭示了 21700次观看的秘密 ,评分+ 144.0 / -0.0
- 智能解析器,用于以单词形式记录的数字 20,500次浏览,评分+ 136.0 / -1.0
- 泛型和元编程模型:Go,Rust,Swift,D和其他 17000次视图,评分+ 110.0 / -2.0
- 我建立了关于电池 22,200次浏览的全球知识库 ,评分+ 139.0 / -0.0
- 当我撰写并出版有关莫斯科国立大学的书时,或说12个严重错误, 21,600次查看,评分+ 134.0 / -0.0
- 关于kote,妻子,两个儿子,这个主意……而不仅仅是。 一个故事,连续 43,000次观看,评分+ 269.0 / -8.0
- 755兆像素的计算视频:昨天,今天和明天的全光 41,500次观看,评分+ 244.0 / -0.0
- 零售中的地块密度 27,500次浏览,评分+ 160.0 / -1.0
有关评论与视图比例的热门文章- Github开始阻止来自克里米亚,古巴,伊朗,朝鲜和叙利亚的用户存储库 44,500次查看,1,309条评论,评分+ 115.0 / -6.0
- 乌克兰课程 60400视图,1672评论,评分+ 285.0 / -41.0
- 削弱Habr规则中的螺母 48300意见,1285评论,评分+ 338.0 / -13.0
- 反对孤立的Runet的集会 50,900视图,923评论,评分+ 204.0 / -32.0
- 如何骑两个轮子工作 47100意见,781条评论,评分+ 113.0 / -10.0
- 谢列梅捷沃飞机失事:历史比喻 82,400意见,1211评论,评分+ 147.0 / -11.0
- 工程师挽救了迷失在森林中的人们,但森林尚未投降 28,900意见,423条评论,评分+ 132.0 / -1.0
- 反对孤立Runet的集会 63,300视图,820评论,评分+ 182.0 / -20.0
- 如何安排保护儿童免受信息侵害的方式-以及关于它最初来自何处的迷人故事,来自(18+) 65,400次查看,811条评论,评分+ 175.0 / -2.0
- 世界,您好! 或Habr英文,v1.0 21,000观看次数,249条评论,评分+ 178.0 / -2.0
- 如果您是色盲者 , 如何正确购买土豆 51,800意见,607评论,评分+ 135.0 / -3.0
- 成为一名免费软件维护者的感觉 22,900次查看,259条评论,评分+ 129.0 / -3.0
- 弱点,第2部分:出版物和其他更改的投票期 14000次查看,158条评论,评分+ 238.0 / -3.0
- 电子产品的试生产,最低价格为 34,200次查看,382条评论,评分+ 165.0 / -3.0
- 我们如何配备 Megaphone 39800观看次数,405条评论,评分+ 140.0 / -6.0
- 遥远的核战争? 83,400意见,843评论,评分+ 133.0 / -5.0
- 世界,您好! 或讲英语的Habr,v1.0 60,300观看次数,591条评论,评分+ 268.0 / -7.0
- 记忆模糊的空间 43200次观看,402条评论,评分+ 190.0 / -7.0
- 用户奖励Habr作者 26,400浏览次数,245评论,评分+ 320.0 / -0.0
- 自由市场的原则对美国的理解 56,300次观看,502条评论,评分+ 160.0 / -44.0
最有争议的文章- 国家和T杀手 752条评论,评分+ 83.0 / -80.0,15100视图
- 这些有毒的家伙:他们毒害了 120条评论,评分+ 67.0 / -51.0,50,300意见
- 您为什么教Go 70条评论,评分+ 76.0 / -57.0、23100观看次数
- 我阅读了80份简历,我有 635条问题 ,评分+ 135.0 / -94.0,90700视图
- 为什么实际上不可能成为素食主义者 940条评论,评分+ 76.0 / -52.0,51,600意见
- 功能编程:一种古怪的玩具,会降低劳动生产率。 第 1394 部分评论,评分+ 100.0 / -68.0,54000视图
- 我们编写了生命中最有用的代码,但将其扔进了垃圾箱。 与我们一起 259条评论,评分+ 101.0 / -63.0,62900视图
- 苹果公司上诉 96评论,评分+ 90.0 / -52.0,39,300意见
- 为什么Windows在2019年或CHYDNT中无法转向? 881条评论,评分+ 123.0 / -70.0,75,000视图
- 我不是真正的 246条评论,评分+ 105.0 / -59.0,63900视图
- 现代发展的五个令人恐惧的趋势 262条评论,评级+ 95.0 / -52.0,77400视图
- 忘记OOP的速度越快,对您和您的程序越有好处1271条注释,评分+ 131.0 / -63.0、128000视图
- 电动汽车行驶一年后 1098条评论,评分+ 131.0 / -58.0,71800视图
- 我将停止踢好179条评论,评分+ 147.0 / -62.0,34,400次观看
- 如果可以的话,请赶上我 215条评论,评分+ 141.0 / -58.0、65,400视图
- 退休 22,922条评论,评分+ 259.0 / -100.0,156,000视图
- 精神科医生对文章“病态与健康”的回应 272条评论,评分+ 154.0 / -55.0,43,400视图
- 新的编程语言无意识地杀死了我们与现实的联系 764条评论,评分+ 164.0 / -52.0、106,000视图
- 最后阶段酗酒 597条评论,评分+ 208.0 / -60.0,123,000观看次数
- ``口交文章'':科学家处理了109个小时的口交以开发出吸引成员的AI 361条评论,评分+ 240.0 / -68.0,236,000观看次数
最受好评的文章- Megafon如何在移动订阅上睡觉 ,676条评论,评分+ 624.0 / -2.0,162,000观看次数
- 免费提供“移动内容”,无需短信和注册。 扩音器欺诈细节 ,474条评论,评分+ 488.0 / -8.0,112,000观看次数
- 俄语创新 ,612条评论,评分+ 480.0 / -33.0,127,000视图
- 我如何在Sberbank呆了一年 ,580条评论,评级+ 449.0 / -14.0,233,000观看次数
- Protonmail如何在俄罗斯被阻止 ,398条评论,评分+ 418.0 / -7.0,102,000观看次数
- 诊断为精神分裂症的IT工作10年,生存技巧 ,281条评论,评分+ 403.0 / -8.0,122,000观看次数
- 程序员的诚实简历 ,283条评论,评分+ 410.0 / -40.0,165,000视图
- 当“ a”不等于“ a”时。 受到一次黑客攻击后 ,有64条评论,评分+ 374.0 / -5.0、74,600视图
- 增加它! 现代分辨率提升 ,214条评论,评分+ 366.0 / -1.0,104000观看次数
- LED所占比例空前 ,569条评论,评分+ 364.0 / -1.0,241,000观看次数
- 廉价和昂贵的AAA电池 ,382条评论,评分+ 363.0 / -6.0,159,000视图
- 欺诈者和 EDS- 一切都非常糟糕 ,778条评论,评分+ 356.0 / -0.0,175000视图
- 日本:一个常识性的国家,在某些地方对我们来说是不合理的 ,483条评论,评分+ 365.0 / -12.0,138,000次观看
- 削弱Habr规则中的螺母 ,1285条评论,评分+ 338.0 / -13.0,48300视图
- 用户奖励Habr的作者 ,245条评论,评分+ 320.0 / -0.0,26,400视图
- 我如何抓到黑客 ,273条评论,评分+ 305.0 / -6.0,110,000观看次数
- 现代流行物理学的神话 ,556条评论,评级+ 304.0 / -6.0,99,600意见
- 现在好的开发者是根据观看次数和订阅者来衡量的-这很糟糕 ,486条评论,评分+ 324.0 / -26.0,74800视图
- 在正面碰撞中生存,以及为什么失忆症不是您所想的 ,165条评论,评分+ 297.0 / -4.0,61800观看次数
- Rostelecom个人帐户中的端口扫描程序 ,194条评论,评分+ 300.0 / -8.0,111,000观看次数
热门书签文章- 42位Google高级搜索操作员(完整列表) 47,100次浏览,917个书签
- 如何在1.5年内成为一名Java开发人员 88,500次查看,894个书签
- 采样器。 控制台实用程序,用于可视化任何外壳命令的结果 58,400视图,801个书签
- HBO,谢谢您的提醒。...白俄罗斯药剂师的“切尔诺贝利急救箱” 88,500次浏览,797个书签
- 实用技巧,示例和隧道SSH 40,000次浏览,787个书签
- 256行裸机C ++:在几个小时内从头开始编写光线跟踪器 60,000次浏览,745个书签
- 异步编程(完整课程) 36,700次查看,690个书签
- “疲倦”的员工:有没有出路? 116,000浏览次数,688个书签
- Python采访的广泛概述。 提示和技巧 28,400次浏览,687个书签
- 15台面向初学者的机器学习书籍 18,700次浏览,670个书签
- 在KPI 52500视图中的JavaScript和Node.js讲座课程 ,656个书签
- 我如何在Vim 58100视图中的LaTeX上写数学笔记 ,652个书签
- 我从痛苦的经验(超过30年的软件开发经验)中学到了 100,000次浏览,651个书签
- 茱莉亚·埃文斯(Julia Evans)精选的有用幻灯片 41,000次浏览,587个书签
- 负责任的开发人员的HTTP标头 33,600个视图,566个书签
- N + 7本有用的书 42,700次浏览,563个书签
- 入侵CAN总线汽车。 虚拟仪表板 60,700次浏览,562个书签
- 带着妻子和抵押贷款小心地搬到荷兰。 第1部分:求职 76200次浏览,555个书签
- TCP与UDP或网络协议的未来 50,300个视图,538个书签
- 适用于旧计算机的最佳Linux发行版 66,000次浏览,523个书签
按查看书签比例排序- 面向初学者的15部机器学习书籍 670个书签,18,700次浏览
- 专为您的项目设计的音乐:12个主题资源,其中的曲目已通过知识共享(Creative Commons)许可 477书签,18,100次浏览
- Python采访的广泛概述。 技巧和窍门 687个书签,28,400视图
- 机器学习的数据集的选择 455个书签,19,000个视图
- 基于图 304书签的节点 ,12,700个视图的地牢生成器
- 路径搜索算法和A * 316书签,13,500个视图的简单说明
- Web工具,还是从哪里开始? 421个书签,18800次浏览
- 学习Docker,第2部分:术语和概念 341个书签,15,600个视图
- 探索Docker,第3部分:Dockerfile文件 297个书签,13,800个视图
- .NET应用程序分析和调试工具 244个书签,11600个视图
- 如何在Linux 322书签,15,900视图中调试环境变量
- 如何迈出机器人技术的第一步? 224个书签,11,200次浏览
- 迷宫:分类,生成,搜索解决方案 318个书签,16,000次浏览
- 实用技巧,示例和隧道SSH 787书签,40,000次浏览
- 讲座课程“数字信号处理基础知识” 418个书签,21,400个视图
- 42位Google高级搜索操作员(完整列表) 917个书签,47,100次浏览
- 面向初学者的3D游戏着色器 239个书签,12,400个视图
- 使用WireGuard和DNSCrypt 302书签通过OpenWrt在路由器上进行点旁路PKH锁定,具有 15,700个视图
- 开发在Python 192个书签,10,000个视图中使用分组和数据可视化的技能
- 另一个Github 2:机器学习,数据集和Jupyter Notebooks 265个书签,13900个视图
热门评论文章- 乌克兰语课 1672评论,60,400意见
- 火箭9M729。 关于INF条约 1371年“违反者”的几点评论,共83,000次观看
- Github开始阻止来自克里米亚,古巴,伊朗,朝鲜和叙利亚的用户存储库 1,309条评论,44,500次浏览
- 哈伯规则中的薄弱环节 1285评论,48300观看次数
- 忘记OOP的速度越快,对您和您的程序越有好处1271条注释,128000次查看
- 谢列梅捷沃飞机失事:历史类比 1211评论,82,400意见
- Y世代如何变成倦怠的世代? 1122评论,81,500意见
- 电动车不适合我 1116条评论,50,700意见
- 1098 , 71800
- 1021 , 27500
- 999 , 62100
- 997 , 7700
- 940 , 51600
- , 933 , 120000
- 923 , 50900
- 22 922 , 156000
- 为IT专家选择汽车,或从茶壶中选择茶壶的技巧 914条评论,43,400次查看
- 为什么高级开发人员无法获得工作 901条评论,119,000次查看
- 该计划恢复了经济 892条评论,27,800意见
- 个人城市传送器 889条评论,40,800意见
最后,最后一次反停止的次数- 退休时 22,922条评论,评分+ 259.0 / -100.0
- 我阅读了80份简历,我有问题,635条评论,评分+ 135.0 / -94.0
- 亲爱的,我们杀死了互联网,933条评论,评分+ 392.0 / -83.0
- 国家和T杀手,752条评论,评分+ 83.0 / -80.0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- 现代发展的五种可怕趋势,262条评论,评分+ 95.0 / -52.0
ff 我有一些更有趣的示例,但不会让读者感到厌烦。结论
在建立评级时,我提请注意似乎有趣的两点。首先,毕竟,最热门的60%是极客时代类型的文章。明年是否会有更少的人,以及没有啤酒,太空,药物等的文章,哈勃尔的面貌如何-我不知道。读者肯定会失去一些东西。让我们看看。
其次,书签顶部竟然是高质量的。从心理上讲这是可以理解的,读者可能不会关注该评分,并且如果需要某篇文章,他们会将其添加到书签中。这只是有用和严肃文章的最大集中。我认为,如果网站所有者希望增加Habré上此特定类别的文章,则应该以某种方式考虑书签数量与奖励计划之间的关系。这样的东西。
我希望它能提供信息。文章列表很长,但可能是最好的。祝大家阅读愉快。