最近,我遇到
了一个Kaggle数据集,其中包含来自Full MovieLens数据集的4.5万部电影的数据。 数据不仅包含有关演员,电影摄制组,情节等的信息,还包含电影用户对电影的评分(来自27万用户的2600万评分)。
此类数据的标准任务是推荐系统。 但是由于某种原因,我
想到了根据电影发行前的可用信息来
预测电影的评级 。 我不是电影鉴赏家,因此通常只关注评论,选择从新闻中看到的内容。 但是评论者也有些偏见-他们观看的电影比普通观众观看的电影要多得多。 因此,预测这部电影将如何受到公众的欣赏似乎很有趣。
因此,数据集包含以下信息:
- 有关电影的信息:发行时间,预算,语言,公司和原籍国等。 以及平均评分(我们会进行预测)
- 有关剧情的关键字(标签)
- 演员和工作人员的名字
- 实际收视率(估算值)
本文(python)中使用的代码可在
github上找到 。
数据预过滤
完整的阵列包含超过4.5万部电影的数据,但是由于任务是预测收视率,因此您需要确保特定电影的收视率是客观的。 例如,事实上,很多人对此表示赞赏。
大多数电影的收视率很少:

顺便说一句,收视率最高的电影(14075)让我感到惊讶-这就是
“盗梦空间” 。 但是接下来的三个-“黑暗骑士”,“阿凡达”和“复仇者”看起来很合乎逻辑。
可以预期,评分的数量和电影的预算是相互关联的(较低的预算-较低的评分)。 因此,删除少量评级的电影会使偏向更昂贵的电影的模型:
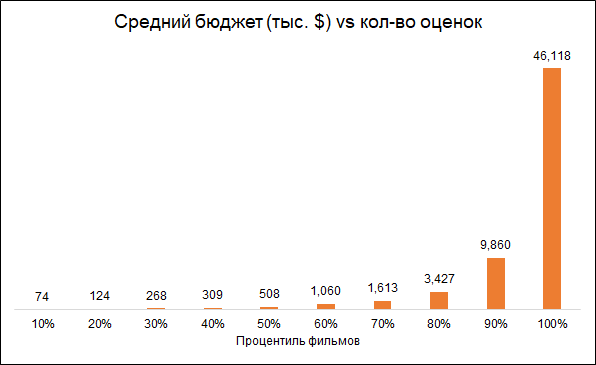
我们将前往评分超过50的分析电影。
此外,我们将删除分级服务开始之日(1996年)发行的电影。 这里的问题是,现代电影的平均评分要比老电影差,这仅仅是因为在老电影中他们观看和评价最好的电影,而在现代电影中就这样。
结果,最终的阵列包含约6000部电影。
二手功能
我们将使用几组功能:
- 电影元数据:电影是否属于“收藏品”(电影系列),发行国家,制造公司,电影语言,预算,类型,电影发行的年份和月份,电影的持续时间
- 关键字:每部电影都有一个描述其情节的标签列表。 由于单词很多,因此按以下方式进行处理:分为相似性组(例如,事故和车祸),根据这些组和单个单词,进行PCA分析,并从结果中选择最重要的组成部分。 这减小了特征空间的尺寸。
- 曾在电影中出演的演员的过往“功绩”。 对于每个演员,形成了一张电影清单,他在其中更早地出演过,并计算了这些电影的等级。 因此,对于每部电影,已经形成了一个指标,该指标汇总了演员较早出演的电影的成功情况。
- 奥斯卡奖 如果演员,导演,制片人,编剧或摄影师以前曾参加过这部电影的提名或最佳影片,导演或剧本的奥斯卡提名,则该模型已考虑在内。 此外,如果演员是奥斯卡最佳男配角或配角的提名或获奖者,则也要考虑到这一点。 来自维基百科的有关奥斯卡奖的信息。
一些有趣的统计数据
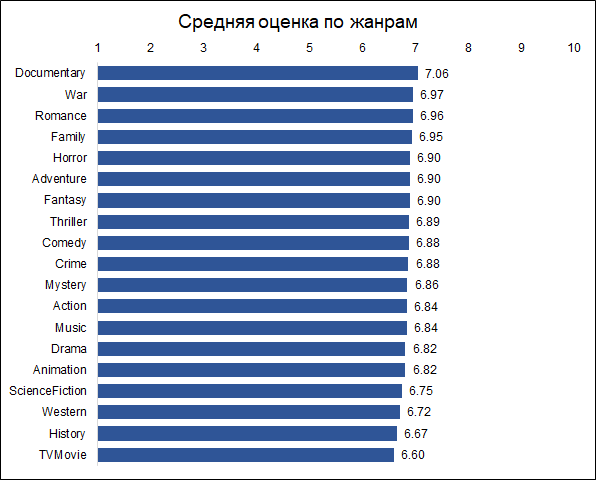
纪录片的收视率最高。 这是一个很好的理由,说明不同的电影是由不同的人来评估的,如果纪录片是由动作迷来评价的,那么结果可能会有所不同。 也就是说,由于公众的最初偏好,这些估计是有偏差的。 但是对于我们的任务来说,这并不重要,因为我们不想预测有条件的客观评估(就像每个观众都观看了所有电影一样),也就是观众将给电影的评估。
顺便说一句,有趣的是,历史电影的评级远低于纪录片。
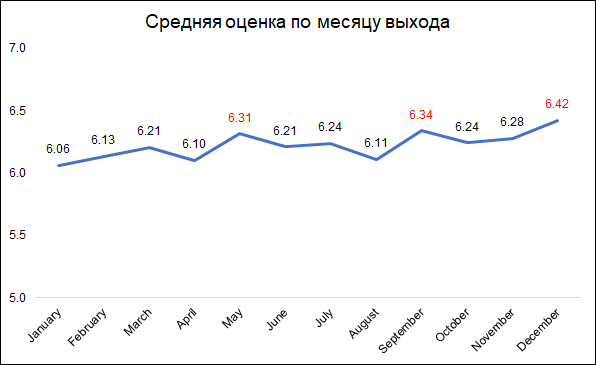
 在12月,9月和5月发行的电影获得最高评分。
在12月,9月和5月发行的电影获得最高评分。大概可以解释如下:
- 在12月,公司发行了最好的电影以在圣诞节假期收集票房
- 9月,将发行将参加奥斯卡斗争的电影
- 五月是夏季大片的发行时间。
 电影分级几乎不依赖预算
电影分级几乎不依赖预算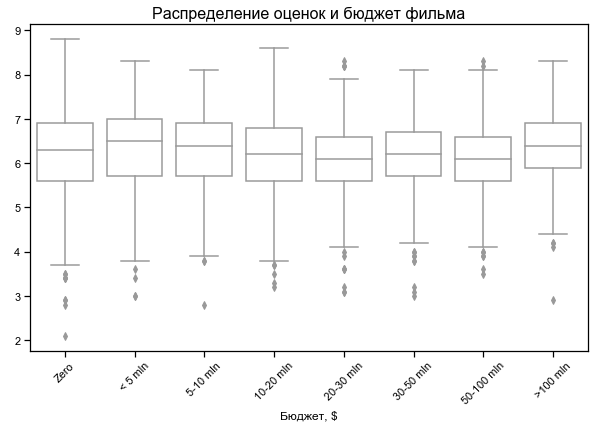
某些电影的预算为零-可能没有数据
最受好评的最短和最长的电影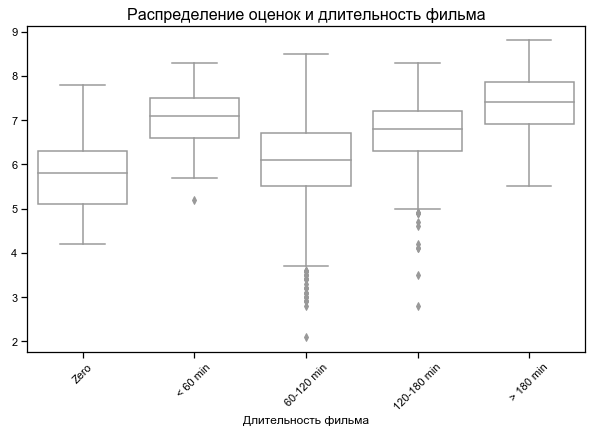
对于某些电影,持续时间为零-可能没有数据
不同功能集上的结果
我们的任务-评级预测是回归任务。 我们将测试三种模型-线性回归(如基线),SVM和XGB。 作为质量指标,我们选择RMSE。 下图显示了针对不同模型和不同功能集的验证集上的RMSE值(我想了解是否值得将关键字和奥斯卡弄乱)。 所有模型都使用基本超参数构建。
如您所见,XGB具有全套功能(电影元数据+关键字+奥斯卡),效果最好。
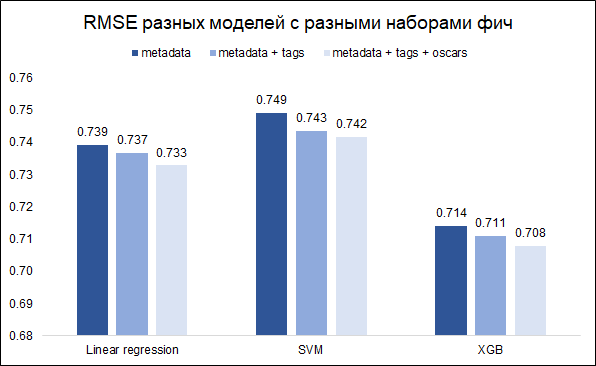
通过调整超参数,可以将RMSE从0.708降低到0.706
错误分析和最终意见
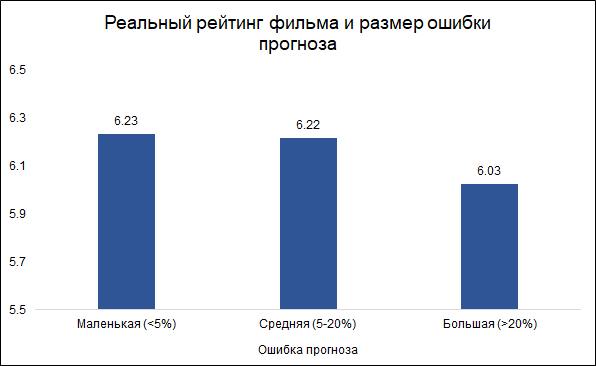
我们假设小于5%的误差很小(大约三分之一),大于20%的误差很大(大约10%)。 在其他情况下(超过一半),我们将考虑误差平均值。
有趣的是,错误的大小与影片的等级相关:
模型在好影片上犯错误的可能性较小,而在不好的影片上发生错误的可能性更大。 看起来合乎逻辑:好电影,就像任何其他作品一样,都是由经验丰富且专业的人制作的。 关于布拉德·皮特(Brad Pitt)参与的《塔伦蒂诺》电影,您可以提前说,它很有可能会变得很好。 同时,一部鲜为人知的演员的廉价电影可以是好事,也可以是坏事,如果不看就很难判断。
以下是模型最重要的功能(PCA变量指的是描述电影情节的经过处理的关键字):

这些特征中有两个属于奥斯卡奖,以前是由团队成员(导演,制片人,编剧,摄影师)提名的,或由演员担任主角的电影提名的。 如上所述,预测误差与电影的评估有关,因此从这个意义上讲,奥斯卡的先前提名可以很好地界定模型。 实际上,至少获得一项奥斯卡提名的电影(在演员或团队中)的平均预测误差为8.3%,而没有获得奥斯卡提名的电影的平均预测误差为9.8%。 在该模型中使用的前10个功能中,奥斯卡提名与错误的大小有着最佳的联系。
因此,提出了建立两个独立模型的想法:一个用于演员或团队获得奥斯卡提名的电影,另一个用于其他电影。 想法是,这可以减少总体错误。 但是,该实验失败了:通用模型的RMSE为0.706,两个单独的模型为0.715。
因此,我们将保留原始模型。 其准确性的结果如下:训练样本中的RMSE-0.688,验证样本中的RMSE-0.706,测试样本中的RMSE-0.732。
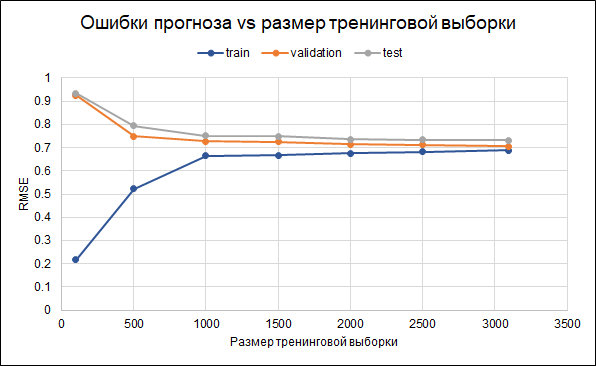
也就是说,有些过拟合。 正则化参数已在模型本身中设置。 减少过度拟合的另一种方法是收集更多数据。 为了理解这是否有帮助,我们将针对不同大小的训练样本(从100到最大可用样本数为3000)构建一个误差图,该图显示从训练集中的约2.5千点开始,训练,验证和测试集的错误发生了变化小,也就是说,样品的增加不会产生明显的影响。
 您还可以尝试其他什么来完善模型:
您还可以尝试其他什么来完善模型:- 最初,电影的选择是不同的(票数的不同限制,其他变量的额外限制)
- 并非所有评分都用于计算评分-可以选择更多活跃用户或删除仅给出不好评分的用户
- 尝试其他方式替换丢失的数据
有趣的是,1997年的《蝙蝠侠与罗宾》电影的预测误差最大(7个预测点,而不是4.2个真实点)。 由阿诺德·施瓦辛格(Arnold Schwarzenegger),乔治·克鲁尼(George Clooney)和乌玛·瑟曼
( Uma Thurman)共同执导的电影获得了
11项金树莓奖
提名(并获得了一次胜利) ,荣登《
帝国》新闻纪录片中有史以来最差的50部电影之
列,并导致
续集的
取消和整个系列的重启 。 好吧,这里的模型也许像一个人一样被误解了:)