我一直对如何更好地在电子图书馆中分发书籍感兴趣。 结果,我通过自动计算页面数和其他东西来到了这个选项。 请问所有有兴趣的猫。
第1部分。Dropbox
我所有的书都在保管箱中。 我将所有内容分为4个类别:教科书,参考资料,艺术作品,非艺术作品。 但是我没有在平板电脑上添加参考书。
大部分书籍是.epub,其余书籍是.pdf。 也就是说,最终解决方案应该以某种方式涵盖这两个选项。
书籍的路径如下所示:
///// / .epub
如果该书是小说,则类别(即上述情况下的“设计”)将被删除。
我决定不理会Dropbox API,幸运的是,我拥有其同步文件夹的应用程序。 也就是说,计划是这样的:从文件夹中取出书籍,通过字计数器运行每本书,然后将其添加到Notion。
第2部分。添加一行
该表本身应如下所示。 注意:列名最好用拉丁字母完成。
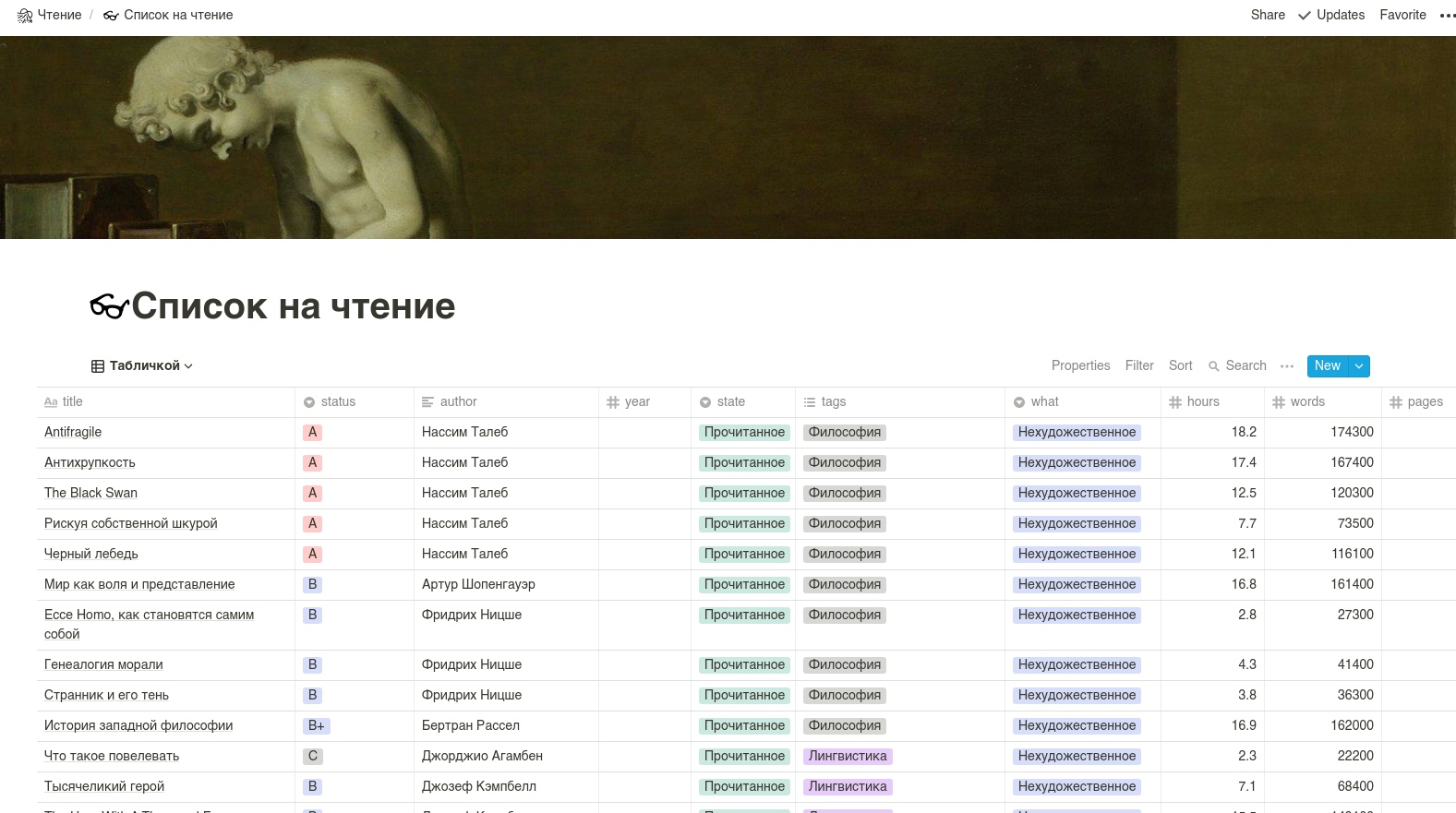
我们将使用非官方的Notion API,因为尚未提供正式的API。

转到概念,按Ctrl + Shift + J,转到应用程序-> Cookies,复制token_v2并将其命名为TOKEN。 然后,转到带有图书馆标牌的页面,然后复制链接。 致电NOTION。
然后,我们编写代码以连接到Notion。
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
接下来,让我们编写一个向标签添加一行的函数。
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
这是怎么回事。 我们在第一行的表中添加一个新行。 接下来,我们用“ /”分隔路径并获取标签。 标签-在“艺术”,“设计”,作者等方面。 然后,我们设置板的所有必填字段。
第3部分。计数单词,手表和其他乐趣
这是一个更复杂的任务。 我们记得,我们有两种格式:epab和pdf。 如果用epab一切都清楚了-那里可能有单词,那么pdf并不是那么简单:它可以仅由胶合图像组成。
因此,pdf中的单词计数功能将如下所示:我们将页面数乘以某个常数(每页平均单词数)。
这是:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
这是A3页面的WORDS_PER_PAGE,大约为300。
现在,让我们编写一个计算页数的函数。 我们将使用PyPDF2 。
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
接下来,我们将为epaba中的页面计数编写一些内容。 我们使用epub_converter 。 在这里,我们拿一本书,将其转换为行,并为每一行计数单词。
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
现在让我们开始计时。 我们会选择最喜欢的单词数,然后除以您的阅读速度。
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
第4部分。连接所有零件
我们需要遍历书籍文件夹中的所有可能路径。 检查概念中是否已经有一本书:如果已经存在,我们不再需要创建一行。
然后,我们需要确定文件的类型,并据此计算字数。 在最后添加一本书。
这是我们得到的代码:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
检查该书是否被添加的功能如下:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
结论
感谢阅读本文的所有人。 我希望她能帮助您阅读更多:)