
TL; DR
- 为了实现容器和微服务的高度可观察性,杂志和主要指标还不够。
- 为了更快地恢复并提高容错能力,应用程序必须应用高可观察性原理(HOP)。
- 在应用程序级别,NRA要求:适当的日志记录,仔细的监视,运行状况检查以及性能/过渡跟踪。
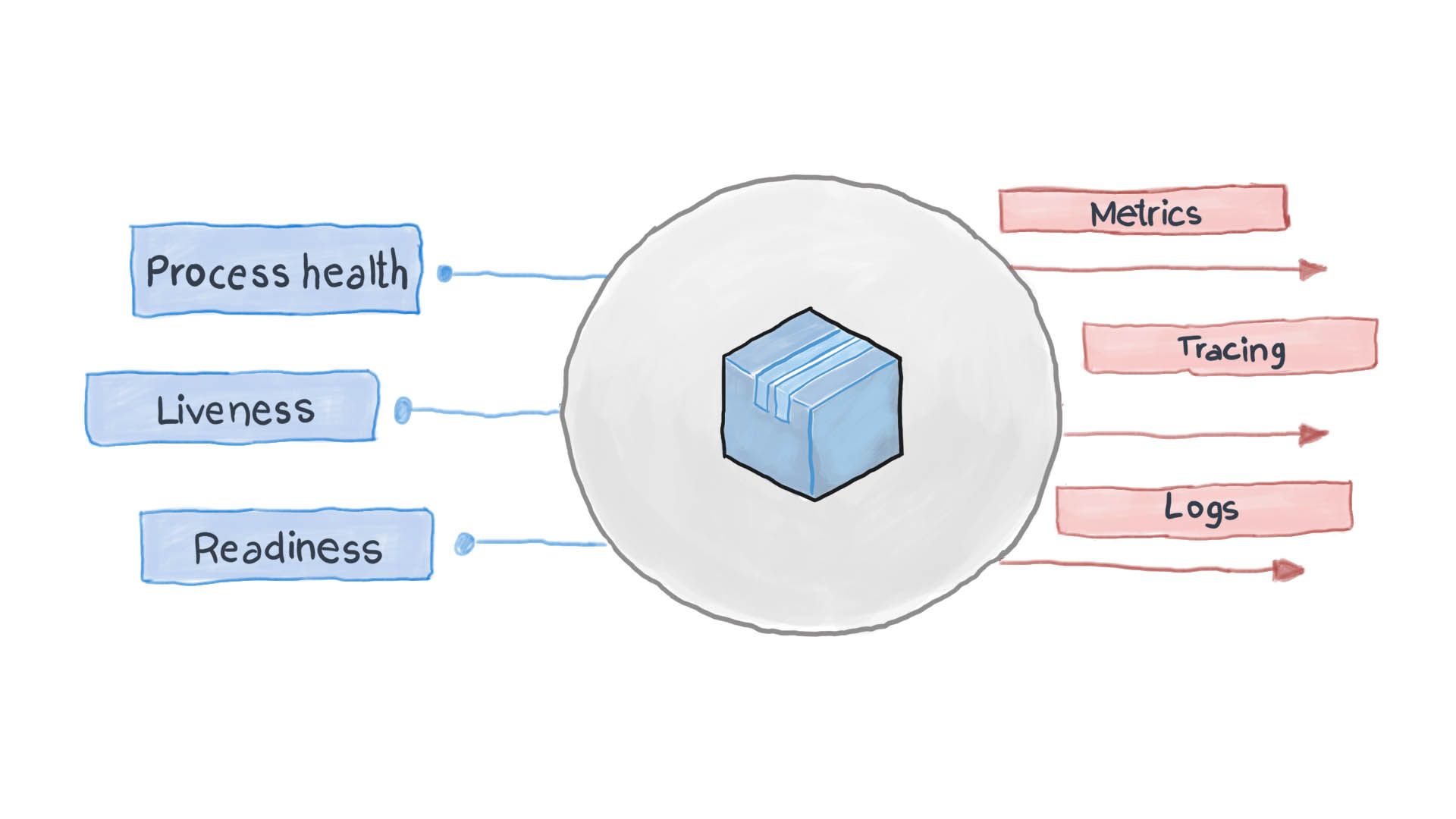
- 使用readinessProbe和livenessProbe Kubernetes检查作为 HOP元素。
什么是健康检查模板?
在设计关键任务和高度可用的应用程序时,考虑容错之类的东西非常重要。 如果应用程序在故障后可以快速恢复,则该应用程序被认为是容错的。 当每个组件放在单独的容器中时,典型的云应用程序将使用微服务架构。 并且为了确保k8s上的应用程序具有高度可访问性,在设计集群时,需要遵循某些模式。 其中包括健康检查模板。 它确定应用程序如何报告有关其性能的k8s。 这不仅是有关Pod是否工作的信息,而且还包括它如何接受请求和响应请求的信息。 Kubernetes对Pod的性能了解得越多,它对流量路由和负载平衡做出的决策就越明智。 因此,应用程序具有高度可观察性的原则可以及时响应查询。
高可观测性(NRA)原理
高可观察性原则是设计容器化应用程序的原则之一 。 在微服务体系结构中,服务不在乎如何处理它们的请求(正确地如此),但是重要的是如何从接收服务中获取答案。 例如,要验证用户身份,一个容器会发送另一个HTTP请求,并以特定格式等待响应-就这样。 PythonJS也可以处理请求,Python Flask可以响应。 彼此的容器就像带有隐藏内容的黑匣子。 但是,NRA的原理要求每个服务都公开几个API端点,以显示其效率以及可用性和容错状态。 Kubernetes要求这些指标考虑路由和负载平衡的下一步。
精心设计的云应用程序使用标准STDERR和STDOUT I / O流记录其关键事件。 随后是一个辅助服务,例如filebeat,logstash或fluentd,它将日志传送到集中式监视系统(例如Prometheus)和日志收集系统(ELK软件套件)。 下图显示了云应用程序如何根据运行状况检查模板和高可观察性原理工作。
如何在Kubernetes中应用运行状况检查模式?
开箱即用,k8s使用控制器之一( Deployments , ReplicaSets , DaemonSets , StatefulSets等)来监视容器的 状态 。 发现吊舱由于某种原因掉落后,控制器尝试重新启动吊舱或将其移动到另一个节点。 但是,pod可能会报告它已启动并正在运行,而它本身却无法运行。 这是一个示例:您的应用程序将Apache用作Web服务器,并且将该组件安装在集群的多个Pod上。 由于未正确配置库,因此对应用程序的所有请求均以代码500(内部服务器错误)响应。 在检查交货时,检查吊舱的状态会得出成功的结果,但是,客户会另外考虑。 我们将这种不良情况描述如下:
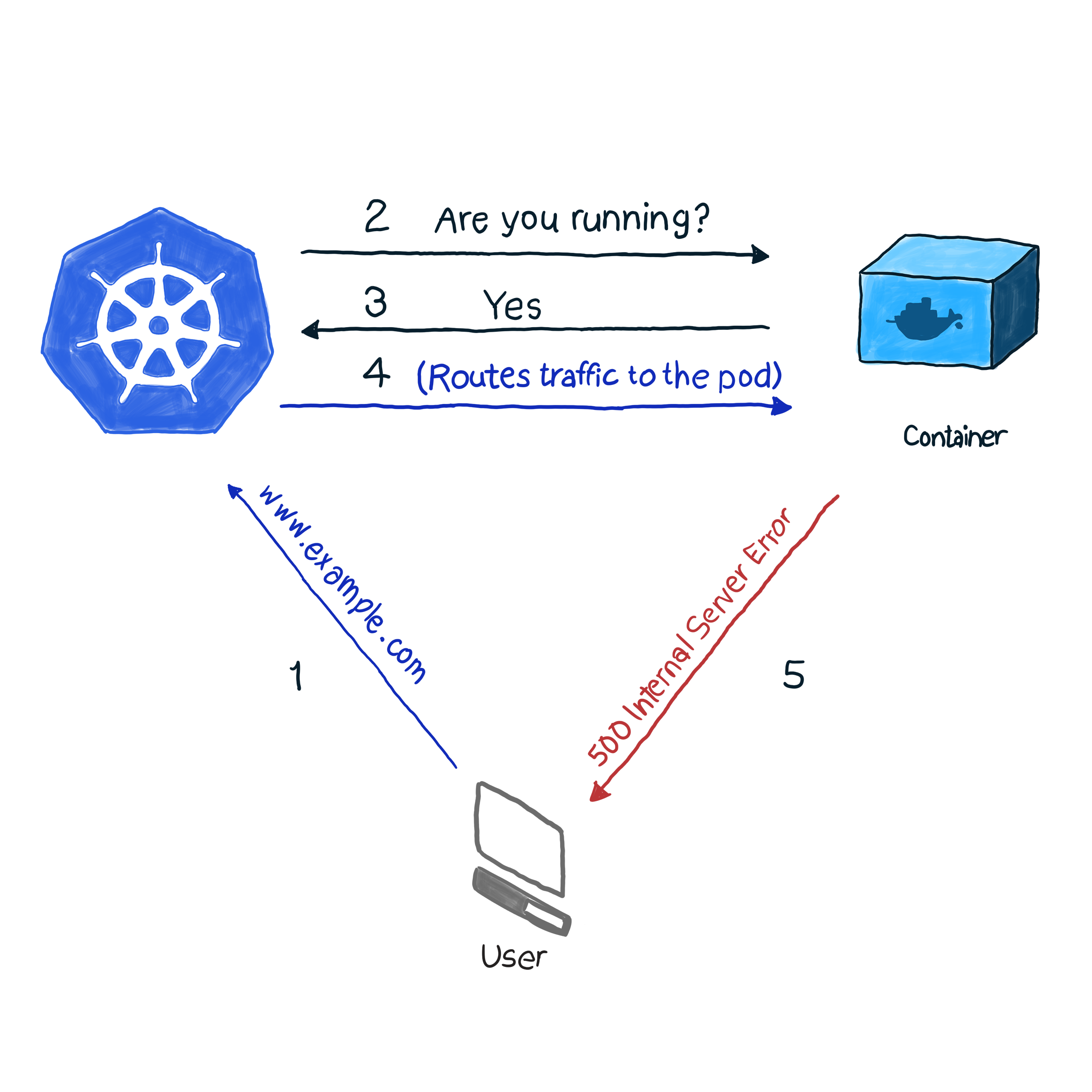
在我们的示例中,k8s执行运行状况检查 。 在这种类型的检查中,kubelet会不断检查容器中进程的状态。 一旦他知道该过程已经开始,他将重新启动它。 如果仅通过重新启动应用程序而消除了错误,并且该程序被设计为在出现任何错误时关闭,则按照NRA和运行状况检查模板进行流程运行状况检查就足够了。 遗憾的是,重启并不能消除所有错误。 对于这种情况,k8s提供了2种更深入的方法来对Pod进行故障排除: livenessProbe和readinessProbe 。
活力探针
在livenessProbe期间, kubelet会执行3种类型的检查:它不仅可以确定吊舱是否正常工作,还可以确定吊舱是否准备好接收并充分响应请求:
- 将HTTP请求设置为pod。 该响应应包含200到399之间的HTTP响应代码。因此,即使该进程正在运行,5xx和4xx代码也指示该pod有问题。
- 要检查具有非HTTP服务的Pod(例如Postfix邮件服务器),您需要建立一个TCP连接。
- 对Pod执行任意命令(内部)。 如果命令出口代码为0,则认为验证成功。
这是一个如何工作的示例。 以下Pod的定义包含一个NodeJS应用程序,该应用程序的HTTP请求错误为500,为确保容器在收到此类错误后重启,我们使用livenessProbe参数:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
这与其他任何.spec.containers.livenessProbe定义都没有什么不同,但是我们添加了一个.spec.containers.livenessProbe对象。 httpGet参数接受HTTP GET请求的发送路径(在我们的示例中为/ ,但在战斗情况下也可能类似于/api/v1/status )。 initialDelaySeconds仍然接受initialDelaySeconds参数,该参数指示验证操作等待指定的秒数。 之所以需要延迟,是因为容器需要一定时间才能启动,并且在重新启动容器后一段时间内将不可用。
要将此设置应用于群集,请使用:
kubectl apply -f pod.yaml
几秒钟后,您可以使用以下命令检查Pod的内容:
kubectl describe pods node500
在输出末尾找到以下内容。
如您所见,livenessProbe发起了HTTP GET请求,容器生成了错误500(已针对该错误进行编程),kubelet重新启动了它。
如果您对NideJS应用程序的编程方式感兴趣,请使用以下app.js和Dockerfile:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Docker文件
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
重要的是要注意这一点:livenessProbe仅在失败的情况下才会重新启动容器。 如果重新启动不能解决干扰容器操作的错误,则kubelet将无法采取措施消除故障。
准备就绪
除了故障排除操作外,readinessProbe的工作方式与livenessProbes(GET请求,TCP通信和命令执行)相似。 记录故障的容器不会重新启动,但会与传入流量隔离。 想象一下,其中一个容器会执行大量计算或处于高负载下,这会增加请求的响应时间。 对于livenessProbe,将触发响应可用性检查(通过timeoutSeconds检查参数),然后kubelet将重新启动容器。 启动后,容器开始执行资源密集型任务,然后再次重新启动。 这对于关心响应速度的应用程序至关重要。 例如,正在路上的一辆汽车正在等待服务器的响应,响应被延迟-从而导致汽车坠毁。
让我们编写一个readinessProbe定义,该定义将GET请求的响应时间设置为不超过两秒,并且应用程序将在5秒钟内响应GET请求。 pod.yaml文件应如下所示:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
使用kubectl扩展容器:
kubectl apply -f pod.yaml
等待几秒钟,然后查看readinessProbe的工作方式:
kubectl describe pods nodedelayed
在结论的结尾,您可以看到一些事件与此类似。
如您所见,当扫描时间超过2秒时,kubectl没有重新启动pod。 相反,他取消了该请求。 传入的连接将重定向到其他工作的吊舱。
注意:既然已经从Pod移除了额外的负载,kubectl再次向其发送请求:不再延迟对GET请求的响应。
为了进行比较:以下是修改后的app.js文件:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
在基于云的应用程序问世之前,日志是监视和检查应用程序状态的主要手段。 但是,无法采取任何故障排除步骤。 日志在今天非常有用,必须将其收集并发送到日志组合系统以进行紧急情况分析和决策。 [ 例如,所有这些都可以在没有使用monit的云应用程序的情况下完成,但是使用k8s变得更加容易:)-Ed。 ]
今天,几乎必须实时进行更正,因此应用程序不再应该是黑匣子。 不,它们应该显示允许监视系统请求和收集有关进程状态的有价值数据的端点,以便它们可以在必要时立即做出响应。 这就是所谓的健康检查设计模板,它遵循高可观察性原则(NRA)。
Kubernetes默认提供两种健康检查类型:readinessProbe和livenessProbe。 两者都使用相同类型的检查(HTTP GET请求,TCP通信和命令执行)。 他们在针对豆荚中的问题做出何种决定方面有所不同。 livenessProbe重新启动容器,以希望不会再次发生该错误,readinessProbe会将pod与传入的流量隔离,直到问题原因得以解决。
正确的应用程序设计应同时包括两种类型的验证,以及它们收集足够的数据,尤其是在创建异常时。 它还应显示必要的API端点,这些端点将重要的健康状态指标传输到监视系统(也称为Prometheus)。