在本系列的
第一篇文章中 ,我积极地提出了Redd的代码开发是次要的,而主要项目是主要的想法。 Redd是辅助工具,因此花很多时间在上面是错误的。 也就是说,它的开发应该很快进行。 但这并不意味着最终的程序不应该是最佳的。 实际上,如果根本没有对它们进行优化,那么仅设备的功率将不足以实现所需的测试系统。 因此,正如我所说,该过程应该快速简便,但是开发人员应始终牢记一些优化原则。
关于优化的厚书已经出版。 这些书中有些是有用的,有些已经过时了,因为其中描述的原理早已在构建代码时迁移到了自动优化的阶段。但是在为普通处理器开发普通程序时有些东西没有任何价值,因此典型的书通常不会描述。 我们现在开始考虑它们。
引言
到目前为止,我一直以“一个问题-一篇文章”为原则写作。 这些文章是以讲座的形式获得的,并且由于一个常见问题而同时影响多个主题。 但是一些读者说,这样的文章不能一口气阅读。 因此,现在我们将尝试在一篇文章中仅讨论一个主题。 这样写对我来说也更容易。 让我们看看,它突然会给大家带来更多便利。
此外,还可以使神秘的Minuser感到高兴。 如果文章是在早晨发布的,那么它的第一个负号是在一段时间后到达的,在此期间不可能阅读全文。 有人纯粹是从原则上做到这一点,只保留有关UDB和俄式三弦琴的主题。 如果出版物不是在早晨,而是在下午,那么他会拖延减号。 第二个减号在一天中到达(顺便说一句,那个朋友还保留了有关UDB和巴拉莱卡的主题)。 新的格式将会有更多的文章,这意味着这对夫妇会有更多的欢乐时光(尽管以我个人的身份,作为作者,这让他们的行为感到悲伤和侮辱)。
该系列中的先前文章:
- 为Redd中安装的FPGA开发最简单的“固件”,并以内存测试为例进行调试。
- 为Redd中安装的FPGA开发最简单的“固件”。 第2部分。程序代码。
- 开发自己的内核以嵌入基于FPGA的处理器系统。
- 以访问FPGA为例,为中央处理器Redd开发程序。
- 在Redd Complex的FPGA中CPU和处理器的连接示例中,首先使用流协议进行实验。
- Merry Quartusel或处理器如何成为这样的生活。
典型系统的神秘行为
让我们通过包括时钟,Nios II / f处理器,SDRAM控制器和输出端口来做最简单的处理器系统。 这就是Spartan这个系统在Platform Designer中的外观
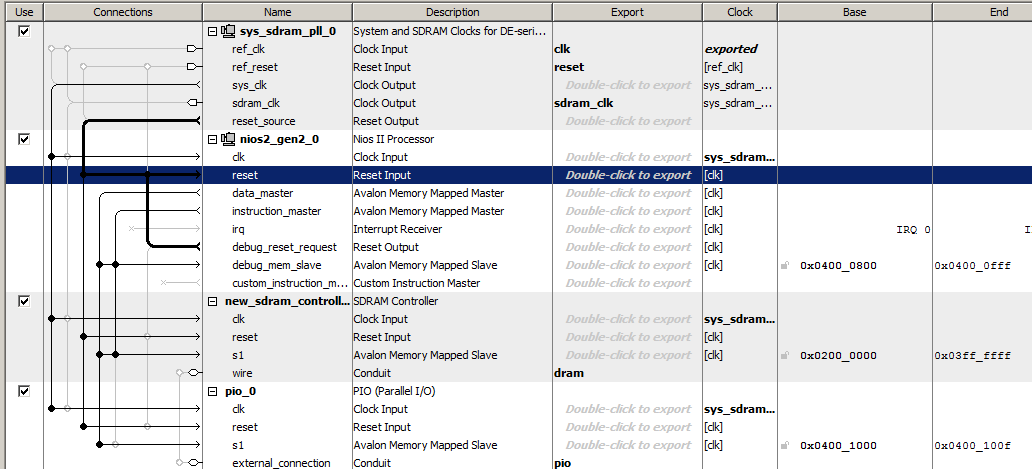
它的程序代码将仅包含一个函数,由于包含许多重复行,因此其主体看起来有些奇怪,但这对我们很有用。
该代码被隐藏,因为它太紧。extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
在最后一行放置一个断点:
IOWR (PIO_0_BASE,0,0);
在
MagicFunction中运行该程序。 我们在港口出口处得到了什么? 衣衫im的冲动:
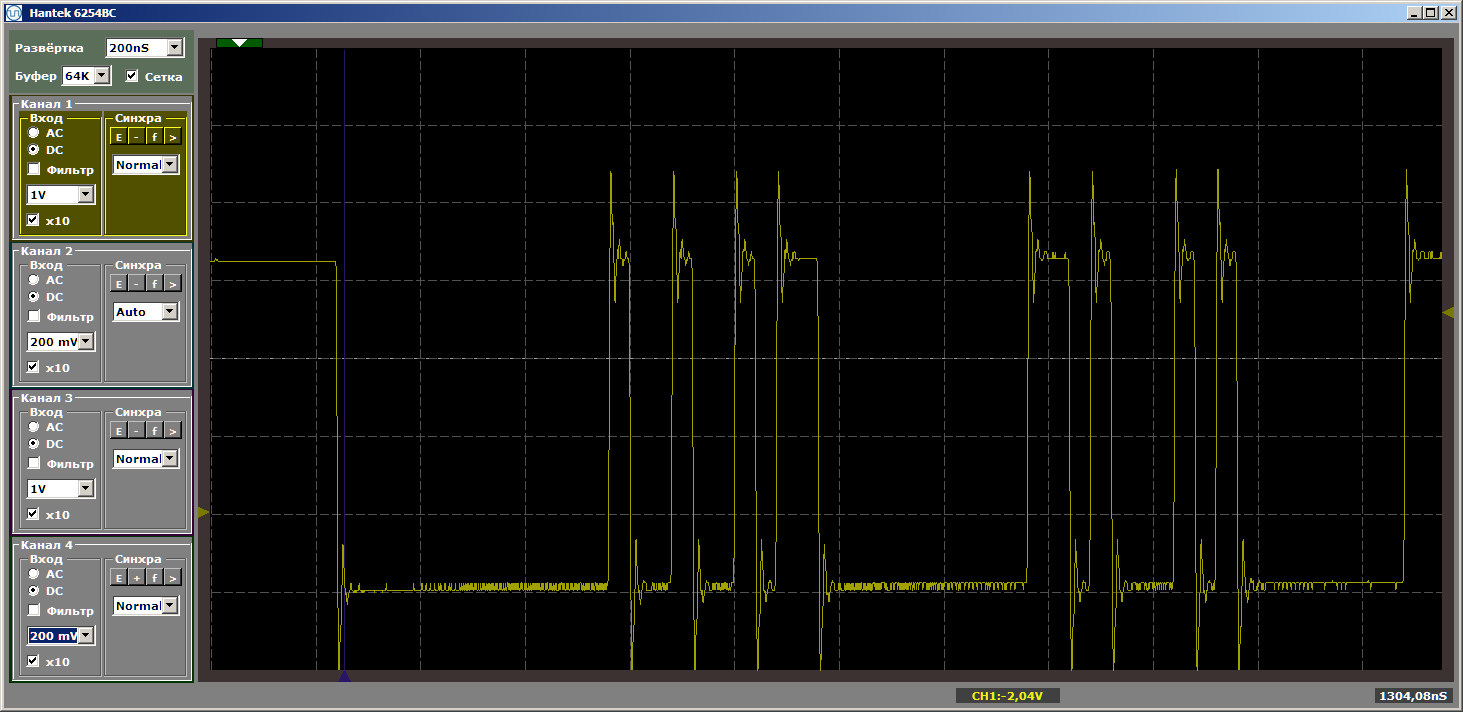
恐怖 好吧,是的。 但是,再次单击“启动”以完成循环的另一个迭代。 现在在出口处,我们看到了一条美丽而光滑的弯道:
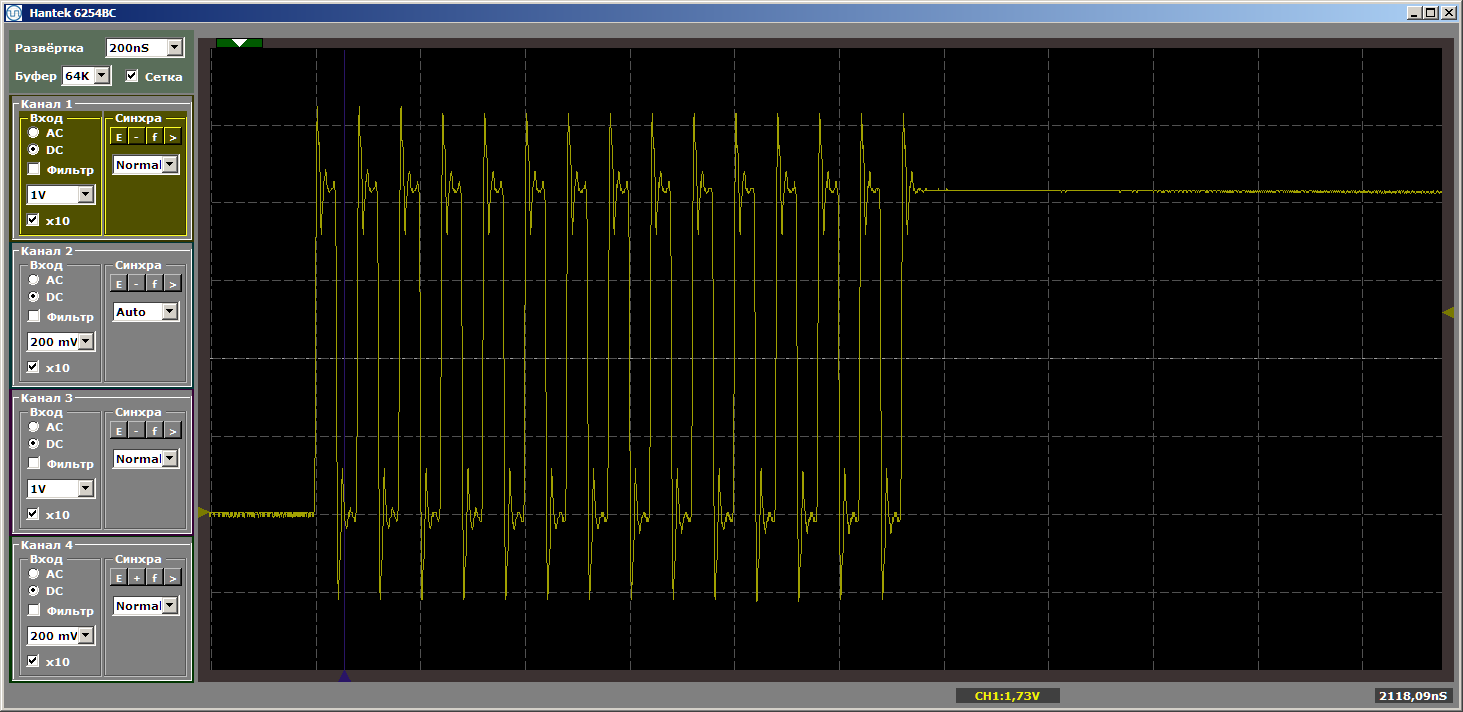
另一个迭代。 还有一个...稳定的曲折。 我们删除断点并动态观察工作-不再有此类中断。 脉冲无止境。
为什么我们在第一次通过时就撕毁了冲动? 出事了吗 不行 我们停止调试,然后重新启动。 再一次,我们得到了残缺的冲动。 程序入口总是出现空白。
线索在于缓存
实际上,解决此问题的方法在于缓存。 我们的程序存储在SDRAM中。 从SDRAM获取代码的速度并不快。 必须发出读取命令,必须给出地址,该地址由两部分组成。 你要等一下 只有这样,微电路才会给出数据。 为了避免每次这样的延迟,微电路不能发出一个字,而是发出几个连续的字。 今天我们不会考虑时间表,我们将在以下文章中将其推迟。
好吧,在处理器核心方面,默认情况下会创建一个缓存。 这是它的设置:
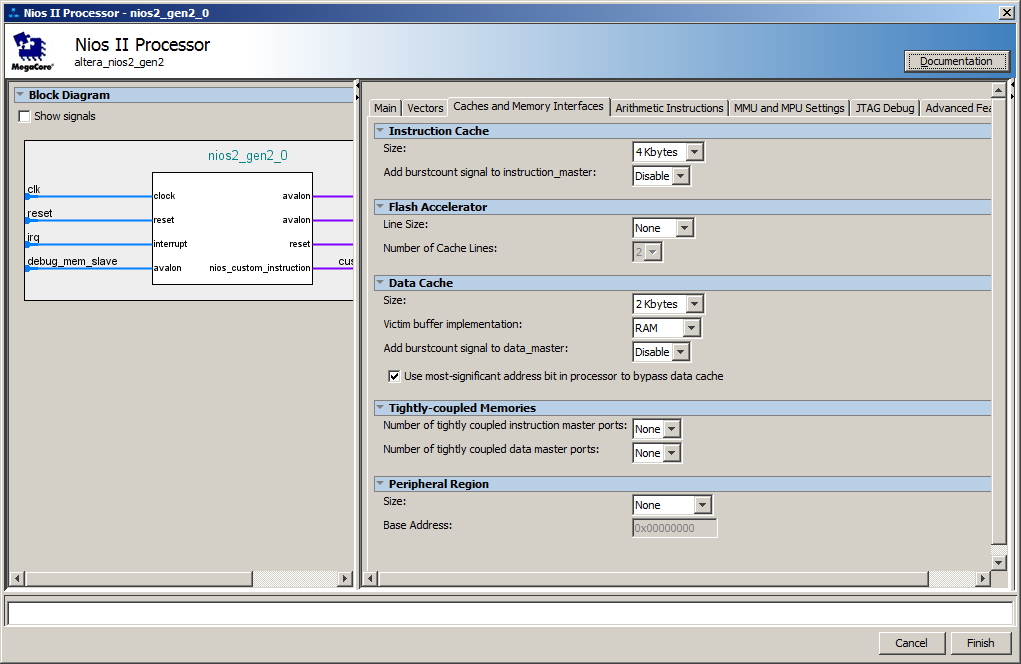
实际上,在将指令从SDRAM批量加载到缓存时,会发生延迟。 在下一次迭代中,代码已经在缓存中,因此不再需要加载。
波形图显示每个加载操作平均每个端口8个条目(一个单元写入4次,零写入4次)。 一条记录-一条汇编程序命令,可以通过选择菜单项窗口->显示视图->其他来找到:
然后Debug-> Disassembly:
这是我们的字符串和相应的汇编代码:
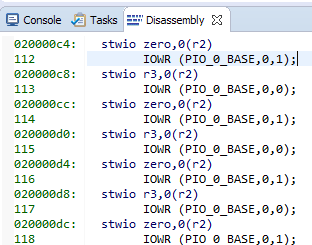
8组,每组4个字节。 每条高速缓存行获得32个字节...我们看一下我们最喜欢的帮助文件C:\ Work \ CachePlay \ software \ CachePlay_bsp \ system.h,请参见:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
实际计算的数据与理论相符。 此外,从文档中可以得出,字符串的大小不能更改。 它始终等于32个字节。
更复杂的实验
让我们尝试在建立的工作期间激发缓存以重新启动。 让我们稍微更改一下测试程序。 我们创建两个函数,并从
main()函数中调用它们,并在其中放置一个循环。 我不会设置断点。 顺便说一句,如果使功能完全相同,优化器会注意到这一点并删除其中之一,因此至少要删除一行,但是它们应该有所不同……这就是我一开始所写的:优化器现在非常聪明。
修改后的测试程序代码。 extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
我们已经以程序的既定模式拍摄了漂亮的结果。
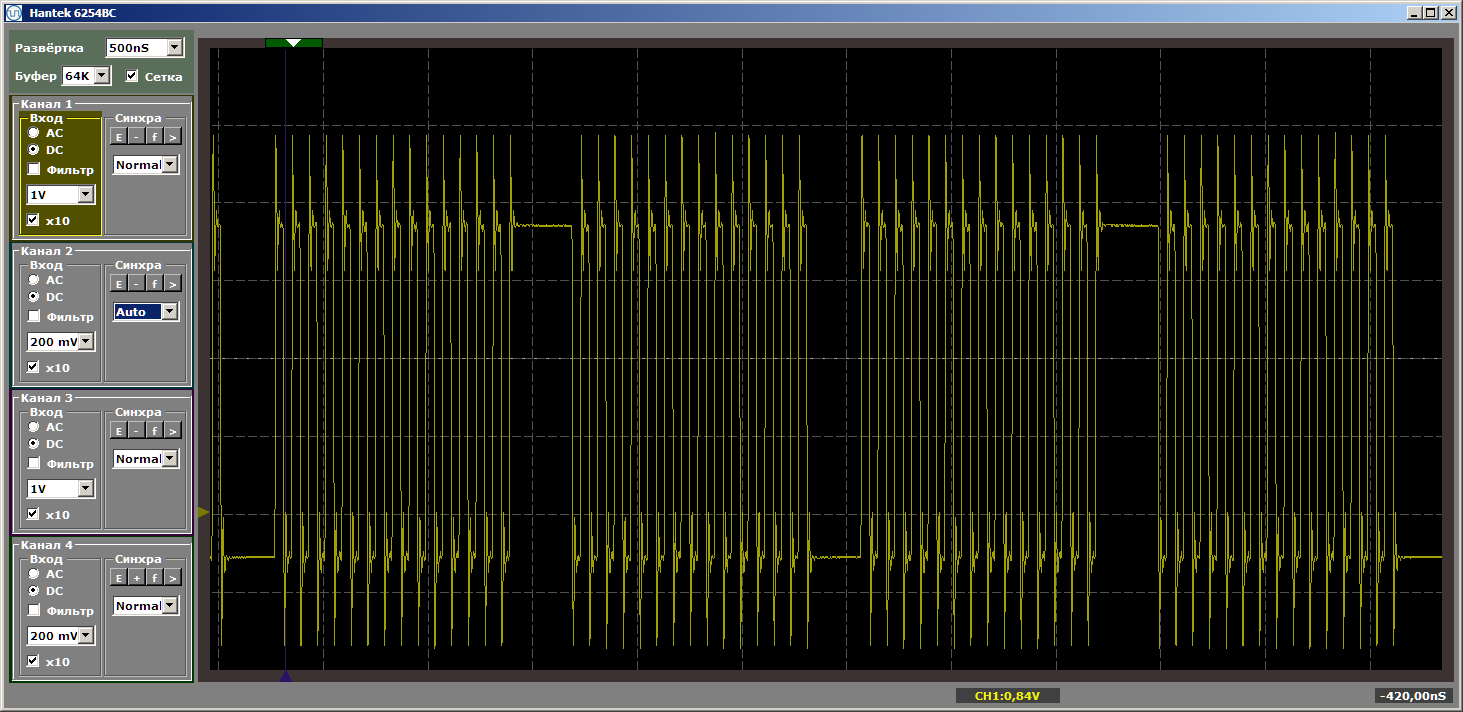
现在,我们将在这对函数之间放置一些新函数,我们将不对其进行调用,它将仅放置在内存中的它们之间。 现在,我将尝试使其占用更多空间...缓存的大小为4 KB,因此我们将其设为4 KB。只需插入1024个NOP,每个NOP的大小为4字节。 我将显示第一个函数的结尾,新函数和第二个函数的开头,这样很清楚程序是如何变化的:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
程序的逻辑没有改变,但是现在运行时,我们得到了脉冲撕裂
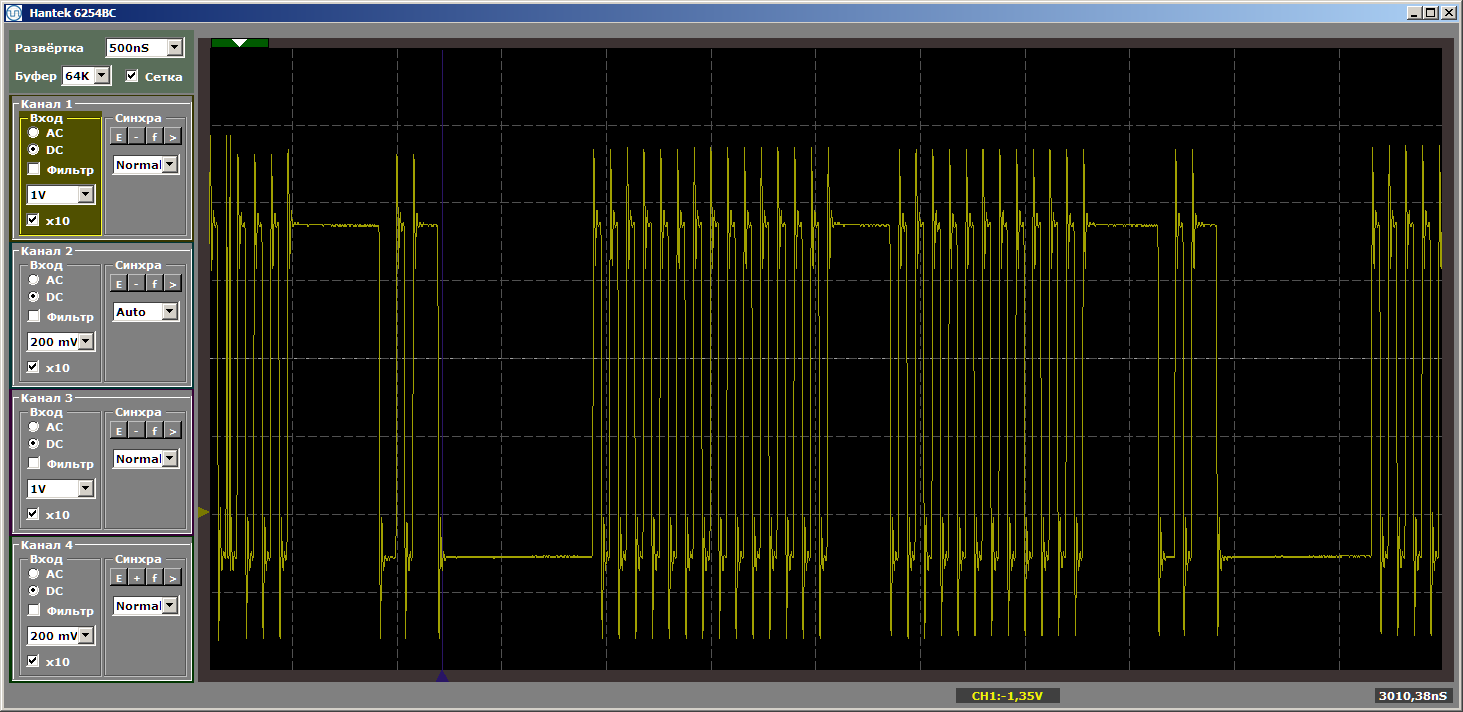
我会问一个幼稚的问题:我们飞出了缓存,现在,随着差距的扩大,是否总会有负载? 一点都不! 更改“错误”功能的大小,使其等于5 KB。 五比四,我们还在飞吗? 还是不行 将此替换为:
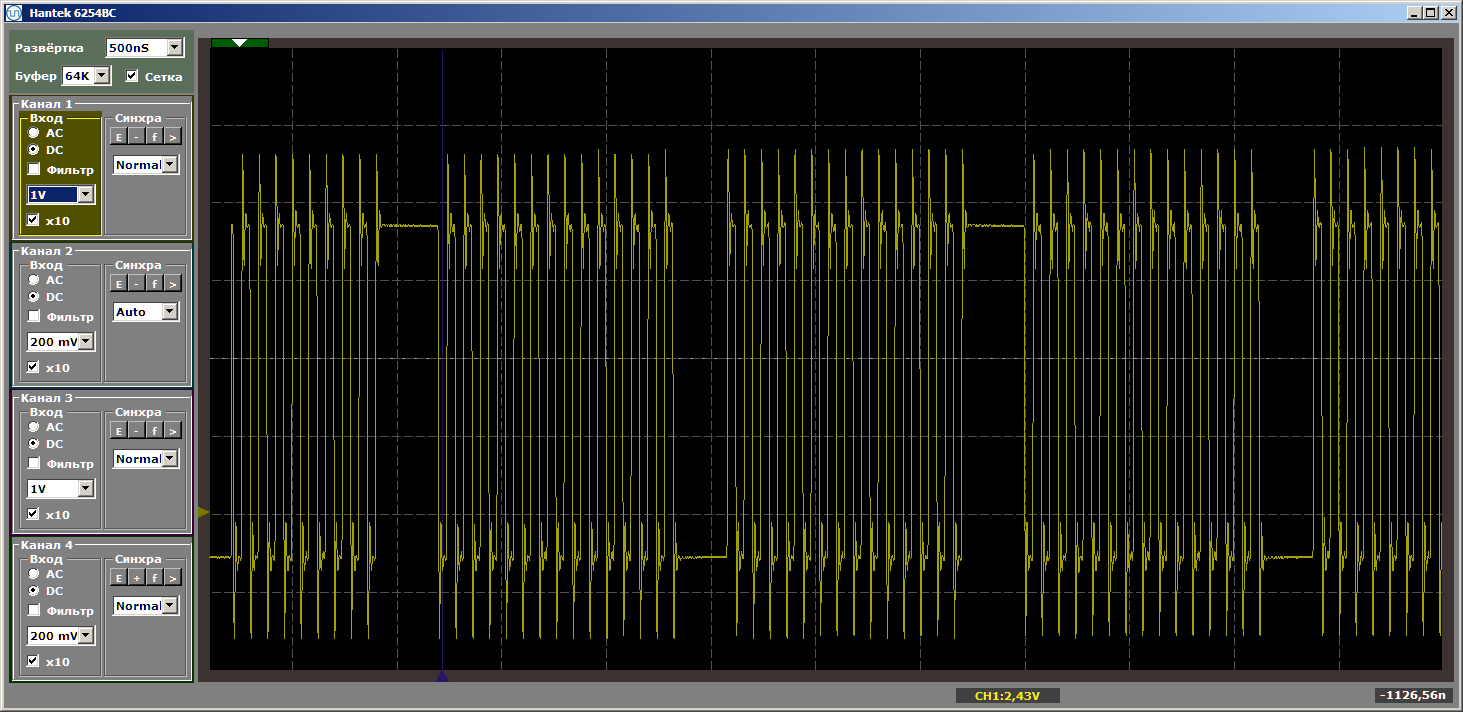
volatile void FuncBetween() { Nops1024 Nops256 }
再一次,我们得到了美丽:
那么,什么决定需要将代码加载到缓存中呢? 我们可以预测一些事情,还是每次需要查看事实时? 让我们深入研究《
Nios II处理器参考指南》为我们提供帮助的理论。
一点理论
这是地址字段在处理器中的拆分方式:
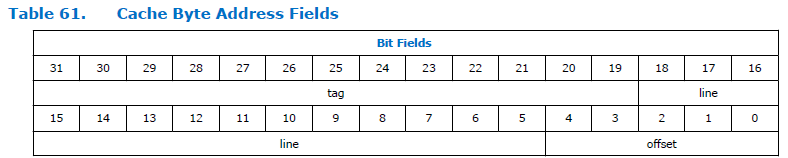
如您所见,地址分为三个部分。 标签,线和偏移量。 对于Nios II处理器,偏移量域的尺寸是恒定的,并且始终为5位,即它可以寻址32个字节。 “行”字段的尺寸取决于配置处理器时指定的缓存大小。 在上图中,它很大。 我不知道为什么文档这么大。 我们的缓存大小为4 KB,这意味着总位深度和偏移量为12位。 5位采用偏移量,对于一行,剩余12-5 = 7位。
我们得到一个128行的特定表,每行32个字节。 我将给出前6行:
因此,我们转到了地址0x123
004 。 如果丢弃“不重要”部分,则“线+偏移”对为0x004。 这是零行范围。 数据将被加载到该行中。 并将进一步处理0x123
000到0x123
01F范围内的数据。 在什么条件下字符串会过载? 当访问任何其他地址(范围从0x000到0x01F)时。 好吧,也就是说,如果我们转到地址0xABC
204 ,则所有内容都将保留在原处,因为低位地址的范围与我们的地址不重叠。 而0xABC
804不会破坏任何内容。 但是,当从地址0xABC
004执行代码时
,将导致新内容被加载到缓存行中。 并且已经过渡到地址0x123
004将再次导致过载。 如果您在0xABC
004和0x123
004之间不断跳转,则会连续发生过载。
让我们尝试以图片的形式来描述它。 假设我们缓存中只有8行,那么为它们涂上不同的颜色会更方便。 我将行大小设置为0x10,以便在图片中绘制地址更加方便(请记住,在实际的Nios II中,行大小始终为0x20字节)。 与高速缓存行大小相同的条件页上的内存跳动。 内存的红色页面将始终转到缓存的红线,橙色到橙色,依此类推。 因此,旧内容将被卸载。

好了,实际上,该程序在实验期间的行为现在很清楚。 当功能严格分开4 KB时,它们会命中相似颜色的页面。 因此代码
while (1) { MagicFunction1(); MagicFunction2(); }
导致加载缓存是为了一个,然后是另一个功能。 当间距不是4,而是5 KB时,功能被分成不同颜色的块。 没有冲突,一切正常进行。
结论
很多年前,当我读到分别针对生产性产品,实时工作和廉价系统设计的Cortex A,Cortex R和Cortex M内核系列时,我最初并不了解,但实际上有什么区别。 不,便宜的系统是可以理解的,但是前两个有什么区别? 但是,在玩完了Cyclone V SoC FPGA中可用的Cortex A9内核之后,我感觉到在使用Iron时缓存的所有缺点。 Cortex A的核心中有许多缓存...系统行为的可预测性几乎为零。 但是缓存确实可以提高性能。 有时候,如果一切工作都无法预测到节拍的准确性,而是快于预期的慢,那会更好。 对于计算或显示图形尤其如此。
但是主要的问题不是文章中描述的东西出现了,而是系统的行为将在组装之间改变,因为没人知道在添加或删除代码后函数将指向什么地址。 15年前,在用于有线电视解码器的Sega游戏机模拟器的项目中,我们必须制作一个完整的预处理器,每次编辑后,都要在SPARC-8内核上移动模拟Motorola汇编器命令的函数,以使它们的执行时间始终相同(由于存在缓存,否则所有内容都会游走很多)。
但是我们什么时候需要可预测性? 当然,在以编程方式形成时序图的过程中(请记住,通常在FPGA中也可以将其委托给设备,但是有一些快速开发的细节)。 但是,在使用计算算法时,它并不是那么重要。 除非算法很复杂,否则您需要确保关键部分不会引起持续的高速缓存过载。 在大多数情况下,缓存不会产生问题,并且可以提高生产率。
在下一篇文章中,我们将研究如何将关键功能预测到始终以最快速度运行的不可缓存存储器中,并讨论该过程中使用的技术所带来的FPGA与标准系统相比的隐式优势。
为了最周到
腐蚀性的读者可能会问:“为什么在插入4 KB的代码时示波图撕裂不足?” 一切都很简单。 如果您恰好插入了4 KB,那么我们将获得以下地址,用于在内存中放置函数:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
为了获得完美的坏波形,您需要插入NOP,以使它们的容量以及
MagicFunction1()函数的长度为4 KB。 无论您要拍什么美丽的照片! 将插入内容更改为此:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
我一遍又一遍地注意该插入没有得到控制。 它只是简单地更改了函数在内存中的相对位置。 有了这个插入,我们得到了想要的可怕的恐怖:
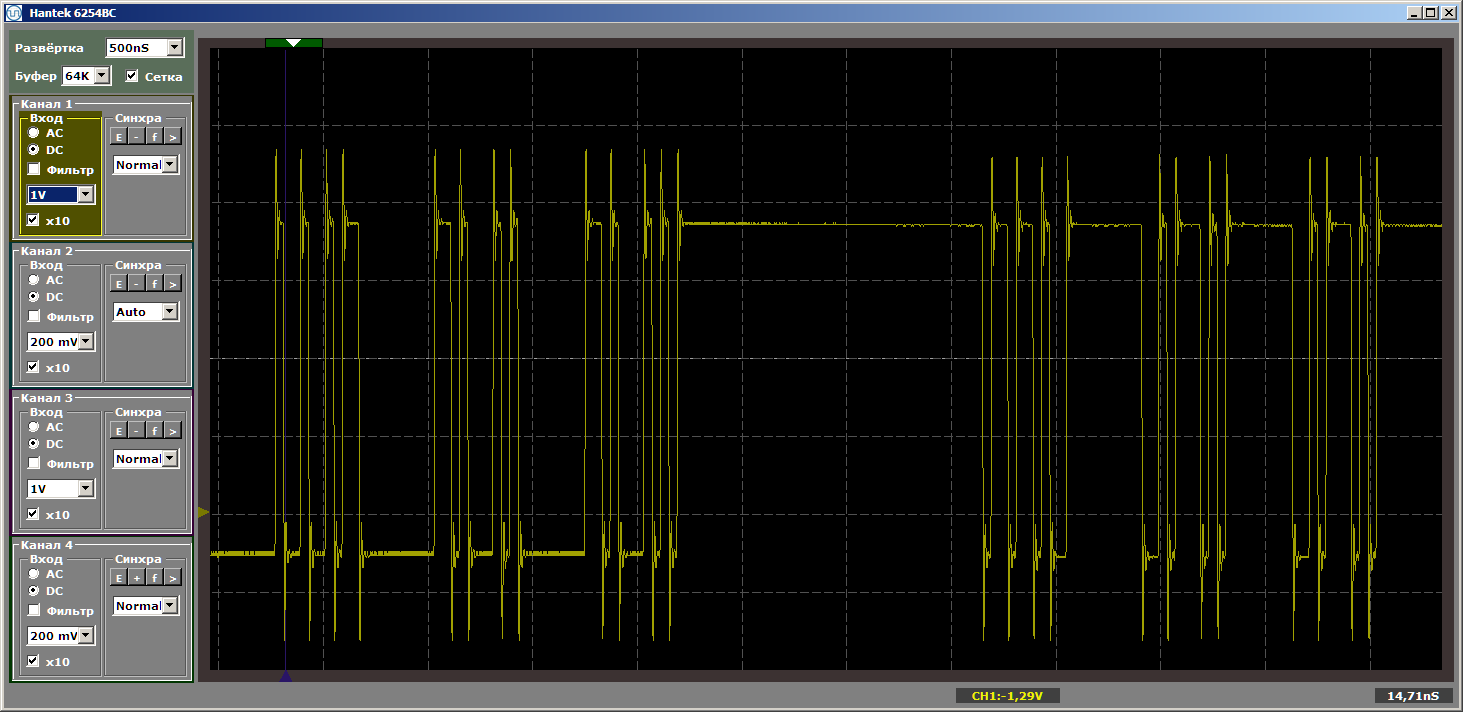
在我看来,插入正文中的此类细节会使每个人都从正文中分散注意力,因此我将其放在了附言中。