敬礼,哈布里沃派! 祝贺所有程序员,并分享了本文的翻译内容,该文章是专为“ High Load Architect”课程的学生准备的。 “分享。 还是不要分片。 不用尝试。”
“分享。 还是不要分片。 不用尝试。”
-尤达今天,我们将深入探讨几个MySQL服务器之间的数据分离。 我们在2012年初完成了分片,该系统仍用于存储我们的基本数据。
在讨论如何共享数据之前,让我们更好地了解它们。 设置好灯光,让草莓变成巧克力,记住《星际迷航》中的名言...
Pinterest是您感兴趣的所有内容的搜索引擎。 在数据方面,Pinterest是全球人类利益最大的图表。 它包含超过500亿个引脚,这些引脚已被用户保存在十亿多个板上。 人们为自己保留一些大头针,像其他大头针一样,订阅其他大头针,板子和兴趣,查看他们所订阅的所有大头针,板子和兴趣的原始资料。 太好了! 现在,让它具有可扩展性!
痛苦的成长
2011年,我们开始获得动力。 据
估计 ,我们的增长速度超过当时已知的任何一家初创公司。 在2011年9月前后,我们基础架构的每个组件都超负荷运行。 我们有几种NoSQL技术可供使用,而所有这些灾难性地失败了。 我们也有很多MySQL从站,我们曾经阅读过这些从站,这导致了很多异常错误,尤其是在缓存时。 我们重建了整个存储模型。 为了有效地工作,我们仔细地处理了需求的开发。
要求条件
- 整个系统应该非常稳定,易于使用,并随着站点的增长从小盒子的大小到月球的大小进行缩放。
- 固定者生成的所有内容应随时在网站上可用。
- 系统应以确定的顺序(例如,以创建时间的相反顺序或用户指定的顺序)支持对板上N个引脚的请求。 同样适用于固定器,固定器等。
- 为简单起见,您应该以各种可能的方式努力进行更新。 为了获得必要的一致性,将需要其他玩具,例如分布式交易日志。 这很有趣,而且(不太容易)!
建筑哲学与笔记
由于我们希望这些数据跨越多个数据库,因此尽管它们可以用于不跨越数据库的子查询,但我们不能仅使用联接,外键和索引来收集所有数据。
我们还需要保持数据的负载平衡。 我们认为逐元素移动数据会使系统不必要地变得复杂,并导致许多错误。 如果我们需要移动数据,最好将整个虚拟节点移动到另一个物理节点。
为了使我们的实施能够快速流通,我们需要分布式数据平台中最简单,最方便的解决方案以及非常稳定的节点。
必须将所有数据复制到从属计算机上以创建备份,并具有高可用性并将其转储到S3以进行MapReduce。 我们仅在生产时与主人互动。 在生产环境中,您将不需要写入或读取从站。 从属滞后,它会导致奇怪的错误。 如果完成分片,则在生产中与从站进行交互是没有意义的。
最后,我们需要一种很好的方法为所有对象生成通用唯一标识符(UUID)。
分片方式
我们要创建的内容必须满足要求,并且要稳定地运行,通常来说,是可行的和可维护的。 这就是为什么我们选择已经相当成熟的MySQL
技术作为基础技术的原因。 我们故意警告自动扩展MongoDB,Cassandra和Membase的新技术,因为它们还远远不够成熟(在我们的案例中,它们以令人印象深刻的方式崩溃了!)。
另外:我仍然建议初创企业避免出现新的怪异现象-只需尝试使用MySQL。 相信我 我可以用疤痕证明这一点。
MySQL-该技术经过验证,稳定且简单-可以运行。 我们不仅使用它,而且它在其他公司中也广受欢迎,其规模甚至更令人印象深刻。 MySQL完全满足我们简化数据查询,选择特定数据范围和行级事务的需求。 实际上,在他的武器库中有更多的机会,但是我们大家都不需要它们。 但是MySQL是“盒装”解决方案,因此必须分片数据。 这是我们的解决方案:
我们从八台EC2服务器开始,每台服务器上都有一个MySQL实例:
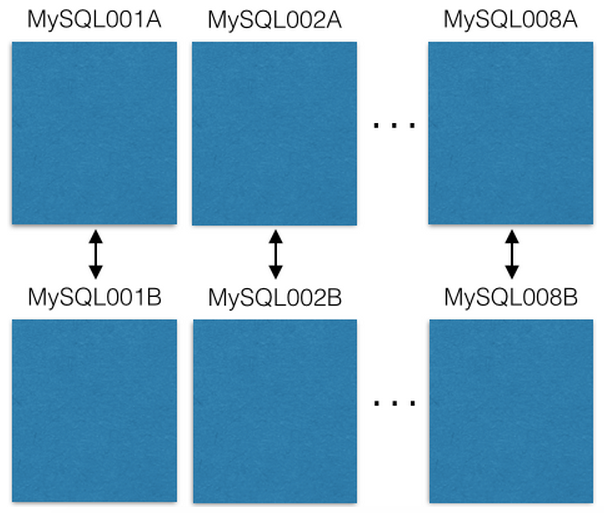
如果发生主要故障,则将每个MySQL主/主服务器复制到备份主机。 我们的生产服务器仅读或写主机。 我建议您也这样做。 这大大简化并避免了复制延迟带来的错误。
每个MySQL实体都有许多数据库:

请注意,每个数据库都有唯一的名称:db00000,db00001到dbNNNNN。 每个数据库都是我们数据的一部分。 我们做出了一项架构决策,在此基础上,只有部分数据属于该碎片,并且永远不会超出该碎片。 但是,您可以通过将分片移动到其他计算机来获得更大的容量(我们将在后面讨论)。
我们使用一个配置表来指示哪些计算机具有分片:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
仅当我们需要移动分片或更换主机时,此配置才会更改。 如果
master死了,我们可以使用现有的
slave ,然后选择一个新的
slave 。 该配置位于
ZooKeeper中,并在更新后发送到服务于MySQL分片的服务。
每个分片都有相同的表集:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user等。 我待会儿再说。
我们如何分配这些分片的数据?
我们创建一个64位ID,其中包含分片的ID,其中包含的数据类型以及此数据在表中的位置(本地ID)。 分片ID由16位组成,类型ID为10位,本地ID为36位。 高等数学家会注意到只有62位。 我过去作为编译器和电路板开发人员的经验告诉我,备用位是值得的。 因此,我们有两个这样的位(设置为零)。
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
让我们看一下这个图钉:
https ://www.pinterest.com/pin/241294492511762325/,让我们分析一下它的ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
因此,销钉对象位于3429碎片中。 其类型为“ 1”(即“ Pin”),并且在引脚表中的7075733行上。 例如,让我们想象这个分片在MySQL012A中。 我们可以做到如下:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
数据有两种类型:对象和映射。 对象包含零件,例如引脚数据。
对象表
针脚,用户,面板和注释等对象表具有一个ID(本地ID,具有自动增加的主键)和一个包含JSON和所有对象数据的Blob。
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
例如,固定对象如下所示:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
为了创建一个新的引脚,我们收集所有数据并创建一个JSON Blob。 然后,我们选择分片ID(我们希望选择与放置它的板相同的分片ID,但这不是必需的)。 对于引脚类型1。我们连接到该数据库,并将JSON插入到引脚表中。 MySQL将返回一个自动增加的本地ID。 现在我们有了一个分片,一个类型和一个新的本地ID,因此我们可以编译完整的64位标识符!
要编辑图钉,我们使用
MySQL事务读取-修改-写入JSON:
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
要删除图钉,您可以在MySQL中删除它的行。 但是,最好在JSON中添加
“ active”字段并将其设置为
“ false” ,并在客户端过滤结果。
映射表
映射表将一个对象链接到另一个对象,例如,上面有针脚的电路板。 用于映射的MySQL表包含三列:ID为“ from”的64位,ID为“ where”的ID和顺序ID的64位。 在这个三元组(从何处,何处,序列中)中有索引键,它们位于标识符“ from”的碎片上。
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
映射表是单向的,例如
board_has_pins表。 如果您需要相反的方向,则需要一个单独的
pin_owned_by_board表。 序列ID定义了序列(由于新的本地ID不同,因此无法在分片之间比较我们的ID)。 通常,我们将新引脚插入序列号等于unix(unix时间戳)中时间的新板上。 序列中可以有任意数量,但是unix-time是顺序存储新材料的一种好方法,因为该指标单调增加。 您可以查看映射表中的数据:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
这将为您提供50多个pin_id,然后您可以使用它们来搜索pin对象。
我们刚才所做的是一个应用程序层连接(board_id-> pin_id-> pin对象)。 在应用程序级别,连接的令人惊奇的特性之一是您可以将图像与对象分开进行缓存。 我们将pin_id存储在内存缓存集群中pin对象的缓存中,但是将board_id保存在redis集群中的pin_id中。 这使我们能够选择最适合缓存对象的正确技术。
增加容量
有三种主要方法可以增加系统容量。 更新机器的最简单方法(增加空间,放置更快的硬盘驱动器,更多RAM)。
增加容量的下一种方法是开辟新的范围。 最初,尽管分片ID由16位组成(共64k个分片),但我们总共创建了4096个分片。 只能在这些前4k分片中创建新对象。 在某个时候,我们决定用4096到8191的碎片创建新的MySQL服务器,并开始填充它们。
我们提高容量的最后一种方法是将某些分片移动到新机器上。 如果要增加MySQL001A的容量(分片从0到511),我们将使用以下最大可能名称(例如MySQL009A和B)创建一个新的master-master对,并从MySQL001A开始复制。
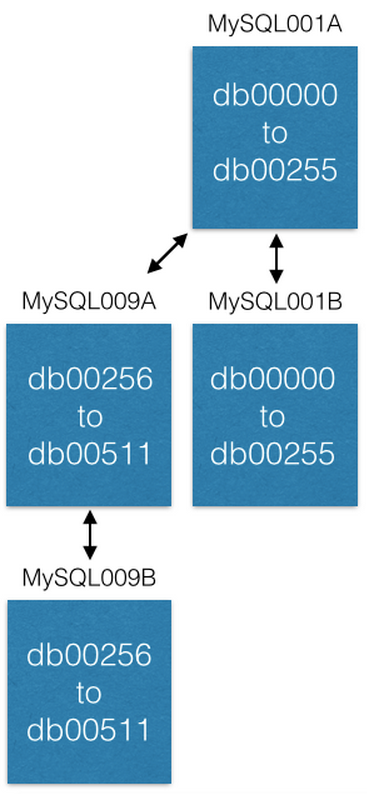
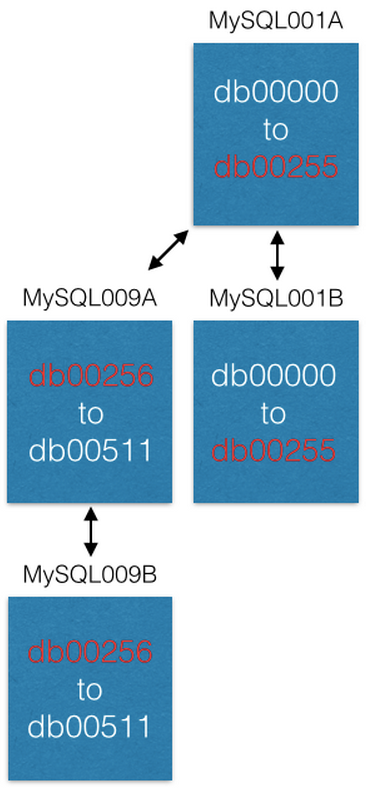
复制完成后,我们将更改配置,以便在MySQL001A中只有0到255的分片,在MySQL009A中只有256到511的分片。现在,每个服务器应该只处理以前处理过的分片的一半。
一些很酷的功能
那些已经拥有用于生成新
UUID的系统的人将了解,在此系统中,我们将免费获得它们! 创建新对象并将其插入对象表时,它将返回一个新的本地标识符。 该本地ID与分片ID和类型ID结合在一起,为您提供了UUID。
那些执行过ALTERs以便向MySQL表添加更多列的人知道,它们的工作速度极慢,成为一个大问题。 我们的方法不需要任何MySQL级别更改。 在Pinterest上,我们过去三年可能只完成了一次变更。 要向对象添加新字段,只需告诉您的服务JSON模式中有几个新字段。 您可以更改默认值,以便在不使用新字段的对象中反序列化JSON时获得默认值。 如果需要映射表,请创建一个新的映射表,并在需要时开始填充它。 完成后,您可以发送!
莫德碎片
这几乎就像一个
国防大队 ,只是完全不同。
需要找到一些没有ID的对象。 例如,如果用户使用Facebook帐户登录,则需要从Facebook ID映射到Pinterest ID。 对我们来说,Facebook ID只是位,因此我们将它们存储在称为mod shard的单独的分片系统中。
其他示例包括IP地址,用户名和电子邮件地址。
Mod Shard与上一部分中所述的分片系统非常相似,唯一的区别在于您可以使用任意输入数据搜索数据。 根据系统中分片的总数对该输入进行哈希处理和修改。 结果,将获得数据将位于或已经位于其上的分片。 例如:
shard = md5(“1.2.3.4") % 4096
在这种情况下,分片将等于1524。我们处理与分片ID对应的配置文件:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
因此,为了在IP地址1.2.3.4上查找数据,我们将需要执行以下操作:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
您将丢失分片ID的某些良好属性,例如空间局部性。 您将必须从一开始就创建的所有分片开始,然后自己创建密钥(不会自动生成密钥)。 最好使用不可变的ID表示系统上的对象。 因此,例如,当用户更改其“用户名”时,您不需要更新许多链接。
最后的想法
该系统已经在Pinterest上运行了3.5年,并且有可能永远存在。 它的实现相对简单,但是要使其投入运行并从旧机器中移走所有数据却很困难。 如果在刚创建新的分片时遇到问题,请考虑创建一个后台数据处理机集群(提示:使用
pyres ),以将带有脚本的数据从旧数据库移动到新的分片。 无论您多么努力,我都保证某些数据将丢失(我发誓都是格雷灵),因此一次又一次地重复数据传输,直到分片中的新信息量变得很小或根本没有。
该系统已尽一切努力。 但是它不以任何方式提供原子性,隔离性或连贯性。 哇! 听起来不好! 不过不用担心 当然,没有它们,您会感觉很棒。 如有必要,您始终可以与其他进程/系统一起构建这些层,但是默认情况下并且免费,您已经获得了很多:工作能力。 通过简单实现可靠性,甚至可以快速工作!
但是容错呢? 我们创建了一个服务于MySQL分片的服务,并将分片配置表保存在ZooKeeper中。 当主服务器崩溃时,我们举起从机,然后举起将替换它的机器(始终是最新的)。 到目前为止,我们不使用自动故障处理。