哈Ha
在
上一部分中 ,通过主要参数(文章数量,其观点和等级)分析了Habr的出勤率。 但是,未考虑网站各部分的受欢迎程度问题。 对此进行更详细的研究,并找到最受欢迎和最受欢迎的集线器变得很有趣。 最后,我将更详细地研究“极客时间效应”,最后,读者将收到有关新收视率的最佳文章的新选择。
谁在乎发生了什么,继续被削减。
我再次提醒您,统计数据和评级不是官方的,我没有任何内幕信息。 也不能保证我没有在某个地方弄错或没有错过任何东西。 但是,我仍然认为这很有趣。 我们将从与代码无关的代码开始,可以跳过第一部分。
资料收集
在解析器的第一个版本中,仅考虑了视图,评论和文章的等级。 这已经很好,但是不允许您进行更复杂的查询。 现在该分析网站的主题部分了,这将使您能够进行相当有趣的研究,例如,了解“ C ++”部分的流行度在过去几年中如何变化。
文章解析器得到了改进,现在返回了文章所属的中心,以及作者的昵称和他的评分(在这里您还可以做很多有趣的事情,但稍后再说)。 数据保存在大约以下类型的csv文件中:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
获取站点的主要主题中心的列表。
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
find_between函数和Str类突出显示了两个标签之间的界线,我
之前已经使用过它们。 主题中心标记有“ *”,因此易于突出显示,您也可以取消注释相应的行以获取其他类别的部分。
在get_hubs函数的输出中,我们获得了相当不错的列表,并将其保存为字典。 我特别引用了整个列表,以便可以估计其数量。
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
为了进行比较,geektimes部分看起来更适中:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
同样,其余的集线器也已保存。 现在,编写返回结果的函数很容易,本文涉及的是极客时间或个人资料中心。
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
其他部分(“开发”,“管理”等)也具有类似的功能。
处理中
现在该开始分析了。 我们加载数据集并处理中心的数据。
def to_list(s: str) -> List[str]:
现在,我们可以按天对数据进行分组,并按不同的中心显示出版物的数量。
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
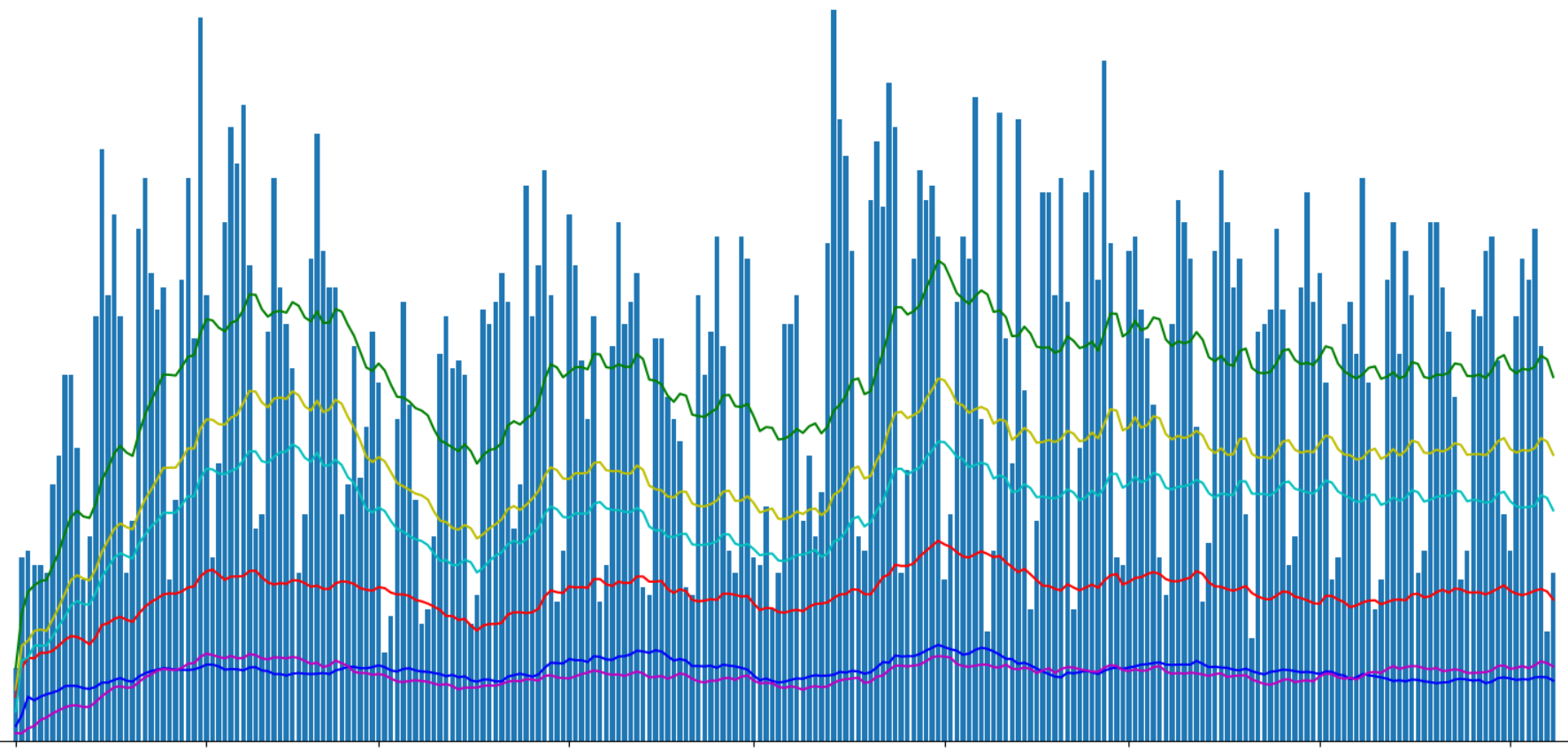
使用Matplotlib显示已发表文章的数量:

我将图表中的“ geektimes”和“ geektimes only”分为两类,因为 一篇文章可以同时属于两个部分(例如,“ DIY” +“微控制器” +“ C ++”)。 我用“个人资料”这个名称突出显示了该网站的个人资料文章,尽管英语中的个人资料可能对此不太正确。
在上一部分中,我们询问了与今年夏天以来针对极客时间的商品支付规则的变化有关的“极客时间效应”。 我们得出单独的极客时间文章:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
结果很有趣。 文章极客时间的观看次数占总观看次数的比例大约为1:5。 但是,如果视图总数出现明显波动,则“有趣”文章的视图将保持在大致相同的水平。

您还可以注意到,更改规则后,“极客时间”部分中文章的观看总数下降了,但“按眼”下降了不超过总数的5%。
看到每篇文章的平均观看次数很有趣:

对于“有趣”的文章,它比平均水平高40%左右。 这可能不足为奇。 对我来说,四月初的失败尚不明确,也许是这样,还是某种解析错误,或者其中一位作者是geektimes休假了;)。
顺便说一句,在图表上,文章浏览量的峰值是另外两个-新年和五月假期。
集线器
让我们继续对集线器进行预期的分析。 我们将按视图数显示前20个中心:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
结果:

令人惊讶的是,就观看而言,“信息安全”中心被证明是最受欢迎的,“编程”和“大众科学”也位居前五名。
Antitope需要Gtk和可可粉。

我会告诉你一个秘密,尽管
这里没有显示视图数,但是在
这里也可以看到顶部的中心。
等级
最后是承诺的评分。 使用对中心的分析数据,我们可以显示2019年最受欢迎的中心上最受欢迎的文章。
信息安全程式设计科普职业生涯资讯科技法例网站开发GTK最后,为了不冒犯他人,我将为您提供访问量最少的枢纽“ gtk”的评分。 其中,
一年中发表了一篇文章,它也是“自动”占据评分的第一行。
结论
没有结论。 祝大家阅读愉快。