
今天,在星期三,
将举行下一版本的Kubernetes-1.16。 根据博客发展的传统,在十周年之际,我们正在谈论新版本中最重大的变化。
用于准备此材料的信息来自
Kubernetes增强跟踪表 CHANGELOG-1.16和相关问题,请求,以及Kubernetes增强提案(KEP)。 所以走吧!..
结
在K8s-clusters(Kubelet)节点的侧面展示了数量众多的显着创新(处于alpha版本状态)。
首先,介绍了所谓的
“ 临时容器 ” (Ephemeral Containers) ,旨在简化Pod中的调试过程 。 新机制使您可以运行特殊容器,这些容器从现有容器的命名空间中开始,并且存在很短时间。 它们的目的是与其他容器和容器进行交互,以解决任何问题并进行调试。 为此功能,实现了一个新的
kubectl debug命令,本质上与
kubectl exec相似:仅在容器中启动容器,而不是在容器中启动进程(如
exec的情况)。 例如,这样的命令会将新容器连接到Pod:
kubectl debug -c debug-shell --image=debian target-pod -- bash
临时容器的详细信息(及其使用示例)可以在
相应的KEP中找到。 当前的实现(在K8s 1.16中)是Alpha版本,并且要转移到Beta版本的标准之一是“测试Ephemeral Containers API的至少2个发行版[Kubernetes]”。
注意 :本质上,甚至功能的名称都类似于我们已经写过的已经存在的kubectl-debug插件。 假定随着临时容器的出现,将停止开发单独的外部插件。另一项创新
PodOverhead旨在提供一种
计算Pod开销成本的机制,该
机制可能会因所使用的运行
PodOverhead有很大差异。 例如,
该KEP的作者引用了Kata容器,它要求启动来宾内核,kata代理,init系统等。 当开销太大时,就不能忽略它,这意味着需要一种方法来考虑进一步的配额,计划等。 为了实现
PodSpec ,将
Overhead *ResourceList字段添加到
PodSpec (与
RuntimeClass数据(如果使用的话)相比)。
另一个值得注意的创新是
Node Topology Manager ,它旨在统一微调Kubernetes中各种组件的硬件资源分配的方法。 这项举措是由于各种现代系统(来自电信,机器学习,金融服务等)对高性能并行计算以及使执行操作的延迟最小化的需求日益增长而引起的,这些系统使用了CPU和硬件加速的高级功能。 到目前为止,得益于不同的组件(CPU管理器,设备管理器,CNI),Kubernetes中的此类优化已经实现,现在它们将添加单个内部接口,以统一该方法并简化Kubelet端上新的类似组件(所谓的拓扑感知)组件的连接。 详细信息在
相应的KEP中 。
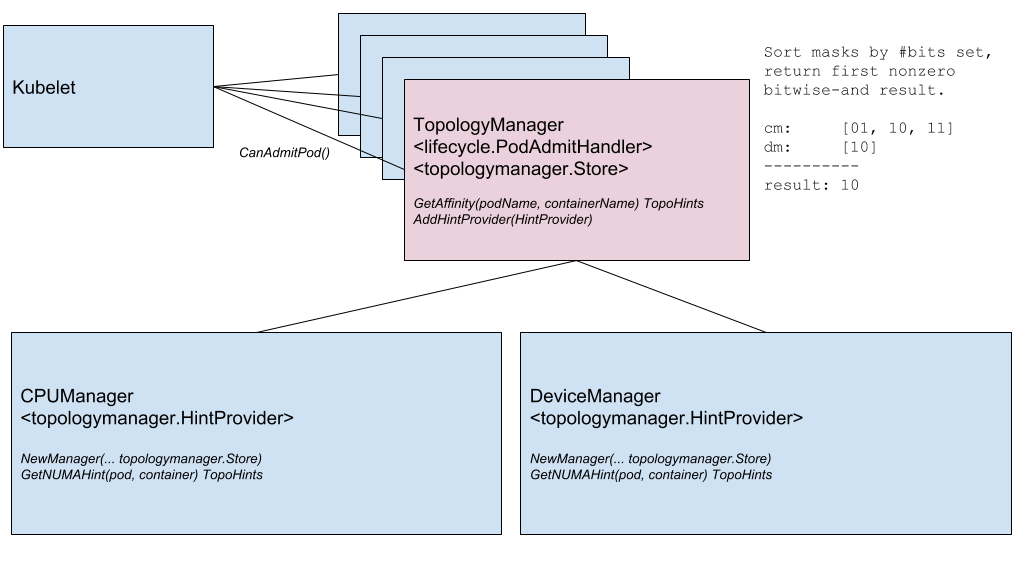 拓扑管理器组件图
拓扑管理器组件图下一个功能是
在启动过程中检查容器( 启动探针 ) 。 如您所知,对于长时间运行的容器,很难获得当前状态:它们要么在实际开始运行之前就被“杀死”,要么长期处于死锁状态。 一项新的检查(通过称为
StartupProbeEnabled的功能门启用)会取消(或
StartupProbeEnabled任何其他检查的操作,直到吊舱完成启动为止。 因此,该功能最初称为
pod-startup liveness-probe holdoff 。 对于启动时间很长的Pod,可以在相对较短的时间间隔内轮询状态。
此外,在beta状态下,立即添加了对RuntimeClass的改进,增加了对“异构集群”的支持。 使用
RuntimeClass Scheduling,现在不需要每个节点都支持每个RuntimeClass:对于Pod,您可以选择RuntimeClass,而无需考虑集群拓扑。 以前,要实现此目的(为了使Pod出现在节点上并支持他们所需的一切),他们必须为NodeSelector和公差分配适当的规则。
KEP讨论了用法示例,当然还有实现细节。
联播网
在Kubernetes 1.16中首次出现的两个重要网络功能(在Alpha版本中)是:
- 支持双网络堆栈-IPv4 / IPv6-及其在pod,节点,服务级别的相应“理解”。 它包括从Pod到外部服务的Pod之间的IPv4到IPv4和IPv6到IPv6的交互,参考实现(在Bridge CNI,PTP CNI和Host-Local IPAM插件的框架内)以及反向操作。与仅在IPv4或IPv6上工作的Kubernetes集群兼容。 实施细节在KEP中 。
Pod列表中的两种IP地址(IPv4和IPv6)输出示例:
kube-master
- Endpoint的新API是EndpointSlice API 。 它以性能/可伸缩性解决了现有Endpoint API的问题,这些问题会影响控制平面中的各个组件(apiserver,etcd,endpoints-controller,kube-proxy)。 新的API将被添加到Discovery API组中,并将能够在由一千个节点组成的集群中为每个服务提供数万个后端端点。 为此,每个服务都映射到N个
EndpointSlice对象,每个对象默认情况下最多不超过100个端点(该值是可配置的)。 EndpointSlice API也将为其未来的发展提供机会:支持每个Pod的多个IP地址,端点的新状态(不仅为Ready和NotReady ),端点的动态子集。
最后一个版本中提供的
终结器 ,称为
service.kubernetes.io/load-balancer-cleanup并已附加到具有
LoadBalancer类型的每个服务,
LoadBalancer升级到beta版。 在删除此类服务时,它会阻止资源的实际删除,直到平衡器所有相应资源的“清理”完成为止。
API机械
真正的“稳定里程碑”固定在Kubernetes API服务器的区域中并与之交互。 从很多方面
来看 ,发生这种情况是由于
CustomResourceDefinitions (CRD)转移到了稳定状态,不需要特殊的表示形式 ,而自遥远的Kubernetes 1.7以来它一直处于beta状态(这是2017年6月!)。 与它们相关的功能也具有相同的稳定性:
- “子资源”,带有
/status和/scale用于CustomResources的/scale ; - 基于外部Webhook的CRD版本转换 ;
- 最近引入 (在K8s 1.15中)CustomResources的默认值(默认)和自动字段删除(修剪) ;
- 使用OpenAPI v3方案创建和发布用于验证服务器端CRD资源的OpenAPI文档的可能性 。
Kubernetes管理员很早就熟悉的另一种机制:
准入 webhook-也很长时间处于beta状态(自K8s 1.9起),现已声明为稳定。
测试版还提供了其他两个功能:
服务器端应用和
观看书签 。
Alpha版本中唯一的重大创新就是
拒绝了SelfLink一种表示指定对象的特殊URI,它是
ObjectMeta和
ListMeta一部分(即
ListMeta中任何对象的一部分)。 为什么拒绝呢? “简单”的动机
听起来像是缺少该领域继续存在的真正(不可逾越)原因的动机。 更为正式的原因是为了优化性能(删除不必要的字段)并简化通用API服务器的工作,这被迫以特殊方式处理此类字段(这是在序列化对象之前唯一设置的字段)。
SelfLink的真正“过时”(在beta版中)将发生在Kubernetes 1.20版中,最后一个是1.21版。
资料储存
与以前的版本一样,在
CSI的
支持领域中也可以看到存储领域的主要工作。 这里的主要变化是:
- 第一次(在Alpha版本中) 出现了对Windows工作节点的CSI插件的支持 :当前使用存储库的方式将替换Kubernetes核心中的树内插件和Microsoft的基于Powershell的FlexVolume插件;
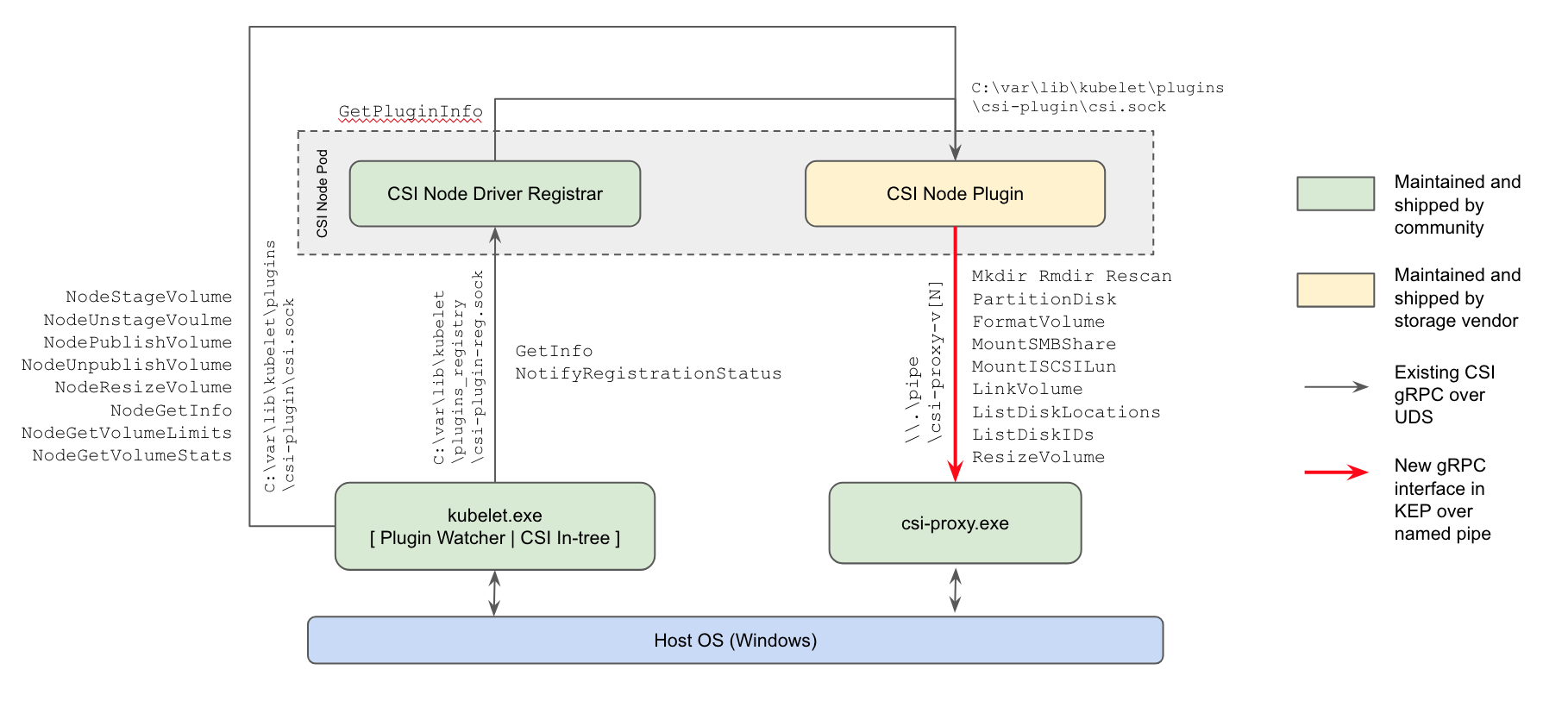
Kubernetes Windows CSI插件实施方案
- K8s 1.12中引入的调整CSI卷大小的功能已发展为beta版;
- 使用CSI创建本地临时卷( CSI内联卷支持 )的可能性达到了类似的“增加”(从alpha到beta)。
克隆在以前版本的Kubernetes
中出现的
功能 (使用现有的PVC作为
DataSource来创建新的PVC)现在也处于beta状态。
策划人
计划中的两个显着更改(均为alpha版本):
EvenPodsSpreading是使用 EvenPodsSpreading 来“公平地分配”负载而不是应用程序逻辑单元 (例如Deployment和ReplicaSet)并调整此分配(作为严格要求或作为温和条件,即优先级)的能力。 此功能将扩展计划的Pod的现有分发功能,现在受PodAffinity和PodAntiAffinity ,使管理员可以更好地控制此问题,这意味着更好的可访问性和优化的资源消耗。 详细信息在KEP中 。- 在Pod调度期间使用RequestedToCapacityRatio优先级函数中的BestFit策略 ,可以将bin打包 (“容器打包”)用于核心资源(处理器,内存)和扩展资源(如GPU)。 有关更多详细信息,请参见KEP 。

Pod计划:使用最适合的策略(直接通过默认计划程序)并使用它(通过计划程序扩展程序)之前
此外,
还提供了在Kubernetes(树外)主要开发树之外为调度程序创建自己的插件
的机会。
其他变化
同样在Kubernetes 1.16版本中,您可以注意到
主动将现有指标完整地或更准确地按照K8s仪表的
官方要求 。 他们基本上依赖于相关的
Prometheus文档 。 造成不一致的原因多种多样(例如,一些度量标准只是在当前说明出现之前创建的),并且开发人员认为是时候将所有内容统一到一个标准,“与Prometheus生态系统的其余部分保持一致”。 该计划的当前实施处于alpha版本的状态,它将在Kubernetes的未来版本中逐渐增加到beta(1.17)和稳定版(1.18)。
此外,还应注意以下更改:
- 随着此操作系统的Kubeadm实用程序(alpha版本)的出现 ,Windows支持的开发,用于Windows容器的
RunAsUserName的可能性 (alpha版本),对组托管服务帐户(gMSA)的beta版支持的改进,对vSphere卷的安装/附加支持 。 - 重新设计 了API响应中的数据压缩机制 。 以前,HTTP筛选器用于这些目的,它施加了许多限制,默认情况下阻止其被包含。 现在,“请求的透明压缩”起作用了:如果邮件头的大小超过128 Kb,则在标头中发送
Accept-Encoding: gzip客户端将收到GZIP中的压缩响应。 Go上的客户端会自动支持压缩(发送所需的标头),因此他们会立即注意到流量减少。 (对于其他语言,可能需要稍作修改。) - 基于外部指标, 可以将 HPA从零扩展到零扩展 。 如果扩展基于对象/外部指标,则当工作负载空闲时,您可以自动扩展到0个副本以节省资源。 对于工作人员请求GPU资源且不同类型的空闲工作人员的数量超过可用GPU的情况,此功能特别有用。
- 一个新的客户端
k8s.io/client-go/metadata.Client用于“通用”访问对象。 它旨在轻松地从群集资源中获取元数据(即, metadata子节),并从垃圾回收和配额类别中对其执行操作。 - 现在可以在没有过时(“内置”树内)云提供程序(alpha版本)的情况下构建 Kubernetes。
- 在 kubeadm实用程序中添加了在
init , join和upgrade操作过程中应用kustomize补丁的实验性(Alpha版)功能。 有关如何使用--experimental-kustomize详细信息,请参见KEP 。 - apiserver的新端点为readyz,它允许您导出准备信息。 API服务器还具有
--maximum-startup-sequence-duration标志,可用于调整其重新启动。 - 声明Azure的两个功能稳定:支持可用区和跨资源组 (RG)。 此外,Azure添加了:
- AAD和ADFS 身份验证支持
- 注释
service.beta.kubernetes.io/azure-pip-name指定负载均衡器的公共IP; - 能够配置
LoadBalancerName和LoadBalancerResourceGroup 。
- AWS在Windows上支持 EBS,并且优化了 EC2 API调用
DescribeInstances 。 - Kubeadm现在在升级到CoreDNS时自行迁移其 CoreDNS配置。
- 相应的Docker映像中的二进制文件etcd使其可以全局执行,从而使您无需root特权即可运行该映像。 此外,etcd迁移映像已放弃了对etcd2版本的支持。
- Cluster Autoscaler 1.16.0切换为使用distroless作为基本映像,提高了性能,并添加了新的云提供程序(DigitalOcean,Magnum,Packet)。
- 使用过的/相关软件的更新:Go 1.12.9,etcd 3.3.15,CoreDNS 1.6.2。
聚苯乙烯
另请参阅我们的博客: