CQM与深度学习不同,可以优化自然语言搜索
简短说明:校准量子网格(CQM)是RNN / LSTM(递归神经网络)/长短期记忆(LSTM)的下一步。 有一种称为校准量子网格(CQM)的新算法,它有望在不使用标记训练数据的情况下提高自然语言搜索的准确性。
已经创建了一种全新的自然语言搜索(NLS)和自然语言理解(NLU)算法,它不仅超越了传统的RNN / LSTM甚至是CNN算法,而且还具有自学习功能,并且不需要标记数据即可进行训练。
听起来真是太好了,但初步结果令人印象深刻。 CQM-由Praful Krishna及其团队在Coseer(旧金山)开发。
尽管公司规模还很小,但他们与多家财富500强公司合作,并已开始举行技术会议。
他们希望在这里证明自己:
准确性:根据克里希纳(Krishna)的说法,不太严重的聊天机器人中的平均NLS功能通常只有约70%的准确性。
在返回正确的相关信息时,Coseer的初始应用程序的准确性达到了95%以上。 关键字不是必需的。
不需要标记的培训数据:我们都知道标记的培训数据是一种财务和时间上的花费,限制了我们聊天机器人的准确性。
几年前 由于准确性,安德森放弃了与IBM Watson进行的昂贵且长达数年的肿瘤学实验。
阻碍准确性的是非常有经验的癌症研究人员需要注释外壳中的文件。 他们应该这样做而不是进行研究。
实施速度: Coseer说,无需培训数据,大多数部署可以在4到12周内启动。 这比当用户开始使用预先训练的系统时要少得多,该系统的操作从预先加载标记的文档开始。
此外,与当前使用传统深度学习算法的大型供应商不同,Coseer倾向于将它们部署在安全和私有云中以确保数据安全。
用于得出结论的所有“证据”都存储在日记中,可用于证明透明度和对数据安全规则(例如GDPR)的遵守情况。
如何运作
Coseer讨论了定义CQM的三项原则:
1.单词(变量)具有不同的含义。
考虑“烤箱”一词,它可以是名词或动词。 例如,“ verse”(可能意为“诗歌”或动词“ verse wind”)-这些是同音异义词。
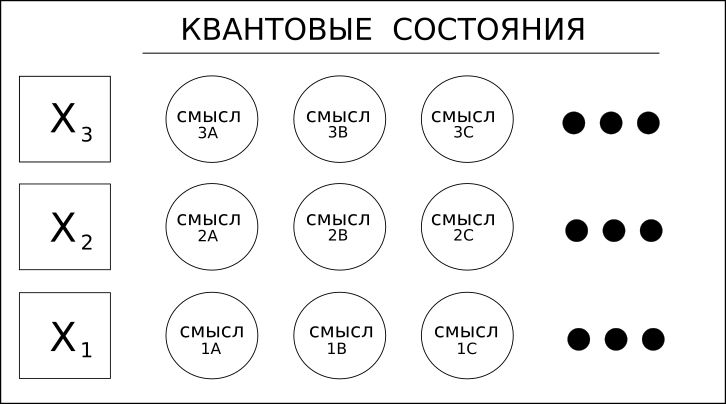
深度学习解决方案,包括RNN / LSTM甚至文本的CNN,都只能向前或向后确定单词的“上下文”,从而确定其含义。
Coseer考虑了单词的所有可能含义,并根据整个文档或语料库将统计概率应用于每个单词。
在这种情况下,术语“量子”的使用仅指具有多个值的可能性,而不是指量子计算的更奇特的叠加。
2.一切都在价值网格中相互联系:
第二个原则是从所有可用的单词(变量)中提取它们所有可能的关系。
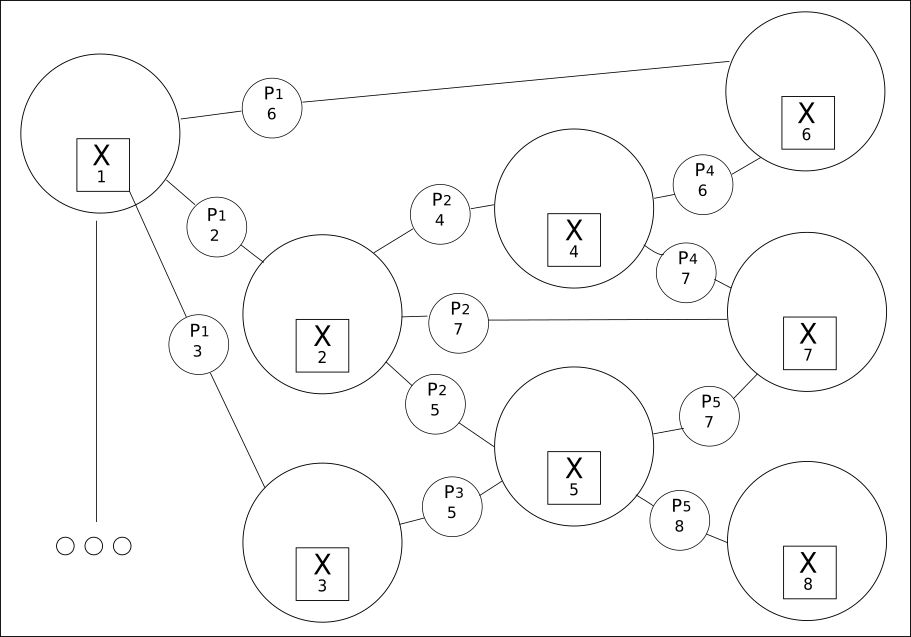
CQM创建一个可能值的网格,在其中可以找到实际值。 与传统的深度学习所提供的相比,使用这种方法揭示了之前或之后的短语之间更广泛的关系。
尽管可以限制单词的数量,但是它们之间的关系可以达到数十万个。
3.依次使用所有可用信息将网格合并为单个值。 该校准过程可以快速识别丢失的单词或概念,并提供非常快速和准确的培训。
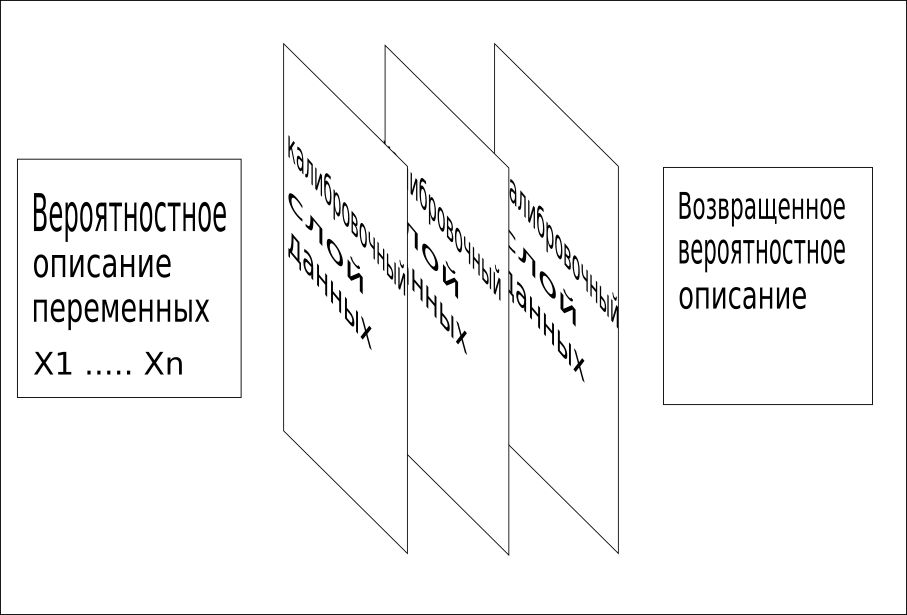
CQM模型使用训练数据,上下文数据,参考数据和其他有关问题的已知事实来识别这些校准数据层。
不幸的是,Coseer在公共领域只发表了很少的文章来解释算法的技术方面。
在培训过程中消除标记数据方面的任何突破都应受到欢迎,当然,提高准确性将导致一个事实,那就是,更满意的客户将使用您的聊天机器人。