哈Ha 在
上一部分中 ,分析了网站各个部分的受欢迎程度,与此同时,出现了一个问题-可以从文章评论中提取哪些数据。 我还想检验一个假设,下面将进行讨论。

数据非常有趣,我们还设法对评论员进行了“小评分”。 继续下割。
资料收集
为了进行分析,我们将使用2019年的数据,尤其是因为已经收到我的csv形式的文章列表。 仍然有必要从每篇文章中提取评论,这对我们来说是幸运的,它们存储在此处,不需要其他请求。
要从文章中提取评论,以下代码就足够了:
r = requests.get("https://habr.com/ru/post/467453/")
data_html = r.text
comments = data_html.split('<div class="comment" id=')
comments_list = []
for comment in comments:
body = Str(comment).find_between('<div class="comment__message', '<div class="comment__footer"').find_between('>', '</div>')# .replace('\n', '-')
if len(body) < 4: continue
body = body.translate(str.maketrans(dict.fromkeys("\t\n\r\v\f")))
body = body.replace('"', "'").replace(',', " ").replace('<br>', ' ').replace('<p>', '').replace('</p>', '').replace(' ', ' ')
user = Str(comment).find_between('data-user-login', '>').find_between('"', '"')
date_str = Str(comment).find_between('<time class="comment__date-time comment__date-time_published', 'time>').find_between('>', '<')
vote = Str(comment).find_between('<div class="voting-wjt', '</div>').find_between('<span', 'span>').find_between('>', '<')
date = dateparser.parse(date_str)
csv_data = "{},{},{},{}".format(user, date, vote, body)
comments_list.append(csv_data)
( ):
xxxxxxx,2019-02-06 11:50:00,0, ?
xxxxxxx-02-24 16:15:00,+1, .
xxxxxxx,2019-02-23 20:15:00,–5,
, , , , . , .
, , — , . , youtube — , , , . , , , disclaimer. , , . , . , ,
.
, . , 2019 ( ).
448533 , csv-
288. , .
, .

, . « »,
10 18 ;) , , .
:
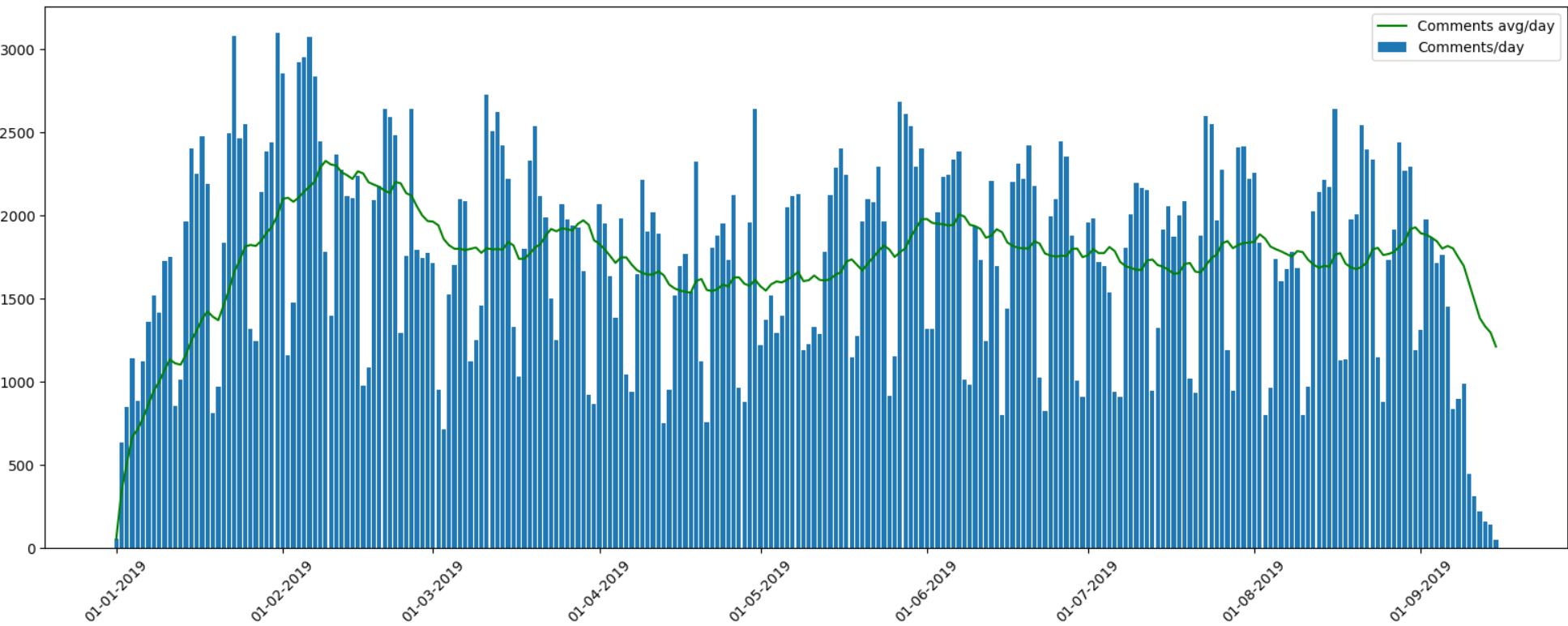
-
— , , ( ).
, , , — , .
, . , ,
25000 .
, , :
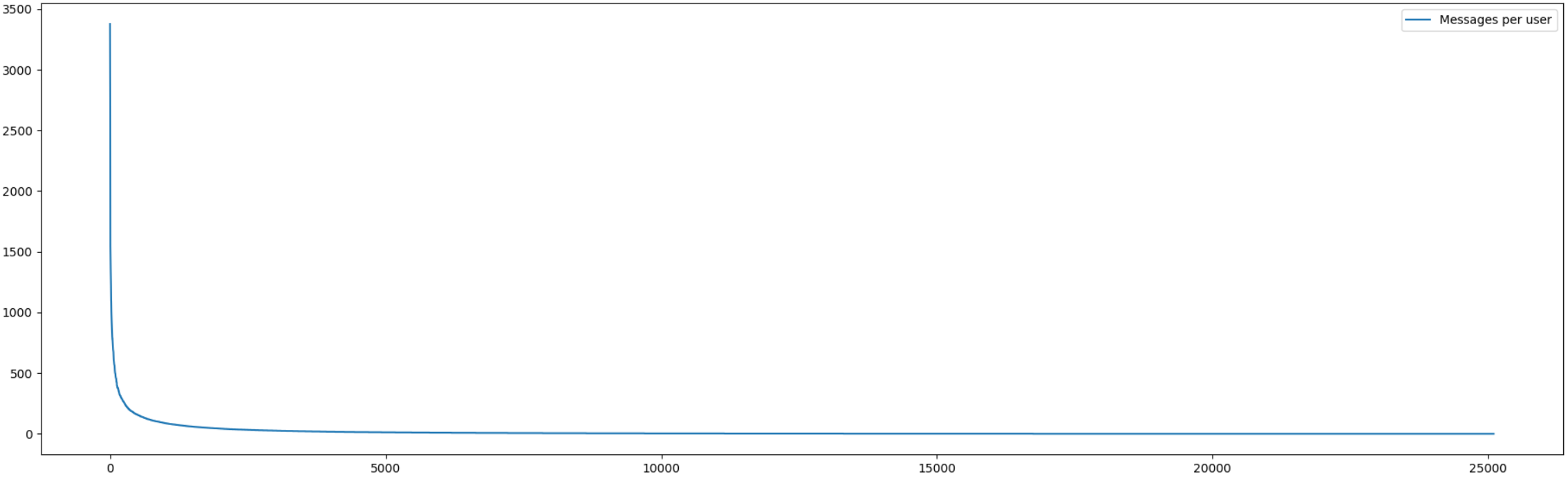
, .
5% 60% . 10% — 74% ( , , 450). , , ( , ).
, — . , , , .
, 5 VoXXXX (3377 ), 0xdXXXXX (3286 ), strXXXX (3043 ), AmXXXX (2897 ) khXXXX (2748 ).
, 5 amXXXX (1395 , +3231/-309), tvXXXX (1544 , +3231/-97), WhuXXXX (921 , +2288/-13), MTXXXX (1328 , +1383/-7) amaXXXX (736 , +1340/-16).
(
)
Milfgard Boomburum. , , , .
.
siXX (473 , 699 ), khXX (1915 , 573 ) nicXXXXX (456 , 487 ). , .
«» vladXXXX (55 , 84 , 0 ), ekoXXXX (77 , 92 , 1 ) iMXXXX (225 , 205 , 12 ).
, , .
, . , « » . - , .
.