引言
几年前, 我们认为是时候在.NET中支持SIMD代码了 。 我们引入了类型为Vector2 , Vector3 , Vector4和Vector<T>的System.Numerics命名空间。 这些类型表示通用API,用于在可能的情况下创建,访问和操纵向量指令。 它们还为硬件不支持适当指令的情况提供软件兼容性。 通过最少的重构,这可以向量化许多算法。 尽管如此,这种方法的通用性使其难以应用,以充分利用现代硬件上的矢量指令的全部优势。 此外,现代硬件还提供了许多专用的非矢量指令,可以显着提高性能。 在本文中,我将讨论如何绕过.NET Core 3.0中的这些限制。

注意: Intrisics翻译尚无既定术语。 在文章的结尾,对翻译选项进行了投票。 如果我们选择一个好的选择,我们将更改文章
有哪些内置功能
在.NET Core 3.0中,我们添加了新功能,称为特定于硬件的内置功能 (远距WF)。 此功能提供对许多特定硬件指令的访问,这些指令无法用通用机制简单地表示。 它们与现有的SIMD指令的不同之处在于它们没有通用的用途(新的WF不是跨平台的,并且其体系结构不提供软件兼容性)。 相反,它们直接为.NET开发人员提供平台和特定于硬件的功能。 现有的SIMD功能(例如,跨平台)可提供软件兼容性,并且它们是从底层硬件中抽象出来的。 这种抽象可能很昂贵,此外,它还可以防止某些功能的泄露(例如,当功能不存在或难以在所有目标平台上仿真时)。
新的内置函数和受支持的类型位于System.Runtime.Intrinsics 。 对于.NET Core 3.0,目前有一个System.Runtime.Intrinsics.X86 。 我们正在努力为其他平台(例如System.Runtime.Intrinsics.Arm支持内置功能 。
在特定于平台的名称空间下, WF被分为代表逻辑集成的硬件指令(通常称为指令集体系结构(ISA))组的类。 每个类都提供一个IsSupported属性IsSupported该属性指示运行代码的硬件是否支持此指令集。 此外,每个此类都包含映射到相应指令集的一组方法。 有时还有一个额外的子类,对应于同一指令集的一部分,可能受到特定硬件的限制(支持)。 例如, Lzcnt类提供对用于计数前导零的指令的访问。 他有一个名为X64的子类,其中包含仅在具有64位体系结构的计算机上使用的这些指令的形式。
这些类中的某些本质上是自然分层的。 例如,如果Lzcnt.X64.IsSupported返回true,则Lzcnt.IsSupported也应该返回true,因为这是一个显式的子类。 或者,例如,如果Sse2.IsSupported返回true,则Sse.IsSupported应该返回true,因为Sse2显式继承自Sse 。 但是,值得注意的是,类名的相似性并不表示它们属于同一继承层次结构。 例如, Bmi2不是从Bmi1继承的,因此IsSupported对于这两套指令返回的值将不同。 开发这些类的基本原理是对ISA规范的明确介绍。 SSE2需要对SSE1的支持,因此代表它们的类通过继承进行关联。 同时,BMI2不需要对BMI1的支持,因此我们没有使用继承。 以下是上述API的示例。
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
您可以在GitHub上的以下链接source.dot.net或dotnet / coreclr的源代码中看到更多信息。
IsSupported编译器将IsSupported检查作为运行时常量(启用优化时)进行处理,因此您不需要交叉编译即可支持多个ISA,平台或体系结构。 相反,您只需要使用if表达式编写代码,其结果是在生成本机代码时将丢弃未使用的代码分支(即由于条件语句中的变量值而无法访问的那些分支)。
重要的是,在使用内置硬件命令之前,对相应的IsSupported进行验证。 如果没有这样的检查,则在不支持这些命令的平台/体系结构上运行的特定于平台的命令的代码将引发PlatformNotSupportedException运行时异常。
它们提供什么好处?
当然, 特定于硬件的内置函数并不适合每个人,但可以用来提高加载计算的操作的性能。 CoreFX和ML.NET使用这些方法来加快操作,例如在内存中复制,搜索数组或字符串中元素的索引,调整图像大小或使用向量/矩阵/张量。 手动将某些代码变成瓶颈的代码也可能比听起来简单。 实际上,代码的矢量化通常是一次使用SIMD指令(一个指令流,多个数据流)一次执行多个操作。
在决定对某些代码进行矢量化之前,需要进行概要分析,以确保该代码确实是“热点”的一部分(因此,优化将大大提高性能)。 在向量化的每个阶段进行概要分析也很重要,因为并非所有代码的向量化都会提高生产率。
简单算法的向量化
为了说明内置函数的用法,我们采用该算法对数组或范围的所有元素求和。 这种代码是矢量化的理想选择,因为 在每次迭代中,执行相同的琐碎操作。
这种算法的示例实现可能如下所示:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
这段代码非常简单明了,但同时对于足够大的输入数据也足够慢,因为 每次迭代仅执行一次琐碎的操作。
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
通过部署周期提高生产力
现代处理器具有提高代码性能的多种选择。 对于单线程应用程序,一种这样的选择是在单个处理器周期内执行多个基本操作。
大多数现代处理器可以在一个时钟周期内(在最佳条件下)执行四个加法运算,因此,使用正确的代码“布局”,即使在单线程实现中,有时也可以提高性能。
尽管JIT可以自行执行循环展开,但由于生成的代码的大小,JIT在做出这种决策时比较保守。 因此,以代码形式手动部署循环可能是有利的。
您可以在上面的代码中扩展循环,如下所示:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
这段代码有点复杂,但是可以更好地利用硬件功能。
对于非常小的循环,此代码运行速度稍慢。 但是对于8个元素的输入数据,这种趋势已经发生了变化,此后执行速度开始提高(对于32,000个元素,优化代码的执行时间比原始版本的时间减少了26%)。 值得注意的是,这种优化并不总是会提高生产率。 例如,当使用元素类型为float集合时,该算法float “已部署”版本的速度几乎与原始速度相同。 因此,进行概要分析非常重要。

通过循环矢量化提高生产力
尽其所能,但是我们仍然可以稍微优化一下此代码。 SIMD指令是现代处理器提供的另一种提高性能的选项。 使用一条指令,它们使您可以在单个时钟周期内执行多项操作。 这可能比直接循环展开更好,因为事实上,可以完成相同的事情,但是生成的代码量较小。
为了清楚起见,每个部署操作在一个部署周期中占用4个字节。 因此,以扩展形式,我们需要16个字节来进行4个加法运算。 同时,SIMD加法指令还执行4个加法运算,但仅占用4个字节。 这意味着我们对CPU的指令更少。 除此之外,对于SIMD指令,CPU可以进行假设并执行优化,但这不在本文的讨论范围之内。 更好的是,现代处理器可以一次执行多个SIMD指令,即在某些情况下,您可以应用混合策略,同时执行部分周期扫描和矢量化。
通常,您需要先查看Vector<T>通用类以完成您的任务。 与新的WF一样,他将嵌入SIMD指令,但是同时,鉴于此类的多功能性,他可以减少“手动”编码的数量。
代码可能看起来像这样:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
这段代码的运行速度更快,但是在计算最终数量时,我们不得不分别引用每个元素。 另外, Vector<T>大小没有精确定义,并且可能会有所不同,具体取决于运行代码的设备。 特定于硬件的内置功能提供了一些附加功能,可以稍微改善此代码并使其更快一点(以增加代码复杂性和维护要求为代价)。

注意对于本文,我使用内部配置参数( COMPlus_SIMD16ByteOnly=1 )强制使Vector<T>大小等于16个字节。 当将SumVectorT与SumVectorizedSse进行比较时,此调整对结果进行了归一化,从而使代码保持简单。 特别地,它避免了编写if (Avx2.IsSupported) { }的条件跳转。 该代码与Sse2的代码几乎相同,但是处理Vector256<T> (32字节),并在循环的一次迭代中处理甚至更多的元素。
因此,使用新的内置函数 ,可以按以下方式重写代码:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
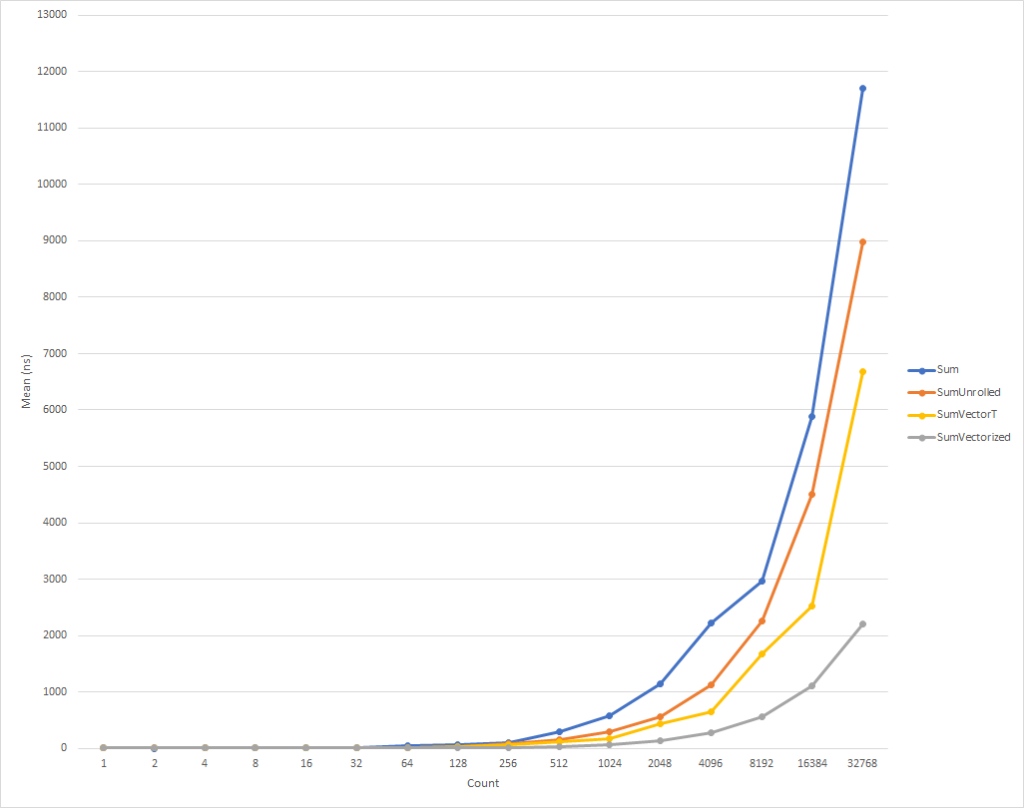
这段代码再复杂一点,但是对于每个人,除了最小的输入集外,它的速度要快得多。 对于32,000个元素,此代码比扩展的周期执行速度快75%,比示例的源代码执行速度快81%。
您注意到我们写了一些IsSupported检查。 第一个检查当前硬件是否支持所需的内置函数集 ,如果不是,则通过结合使用scan和Vector<T>进行优化。 对于不支持所需指令集的平台(如ARM / ARM64),或者如果平台已禁用该指令集,则将选择后一个选项。 如果硬件支持Ssse3指令Ssse3 ,则使用SumVectorizedSse2方法中的第二个IsSupported测试进行其他优化。
否则,大多数逻辑与扩展循环基本相同。 Vector128<T>是包含Vector128<T>.Count元素的128位类型。 在这种情况下,本身是32位的uint可以具有4(128/32)个元素,这就是我们启动循环的方式。
结论
新的内置功能使您有机会利用运行代码的计算机的硬件特定功能。 X86和X64大约有1,500个API,分布在15个集合中,一篇文章中介绍的太多了。 通过分析代码以识别瓶颈,您可以确定代码中受益于矢量化的部分,并观察到相当不错的性能提升。 在许多情况下都可以应用矢量化,而循环展开仅仅是个开始。
任何想查看更多示例的人都可以在框架(请参阅dotnet和aspnet )或其他社区文章中使用内置函数 。 尽管当前的WF数量巨大,但是仍然需要引入许多功能。 如果您具有要介绍的功能,请随时通过GitHub上的dotnet / corefx注册您的API请求。 这里描述了 API审核过程,并且有一个很好的示例 ,该示例在步骤1中指定了API请求模板。
特别感谢
我要特别感谢我们的社区成员Fei Peng(@fiigii)和Jacek Blaszczynski(@ 4creators)在实施WF方面的帮助,以及社区的所有成员,感谢他们对该功能的开发,实施和易用性提供了宝贵的反馈意见。
后记翻译
我喜欢观察.NET平台的发展,尤其是C#语言的发展。 来自C ++领域,对使用Delphi和Java进行开发几乎没有经验,因此我很乐意开始用C#编写程序。 在2006年,在托管垃圾收集和跨平台领域中,这种编程语言(语言本身)比Java更为简洁实用。 因此,我的选择落在了C#上,我并不后悔。 语言发展的第一阶段就是它的出现。 到2006年,C#吸收了当时最好的语言和平台上的所有优点:C ++ / Java / Delphi。 2010年,F#上市。 这是一个研究功能范式的实验平台,旨在将其引入.NET世界。 实验的结果是C#进化的下一阶段-通过引入匿名函数,lambda表达式以及最终的LINQ,将其功能扩展到FP。 从我的角度来看,这种语言的扩展使C#成为最先进的通用语言。 下一步的发展步骤与支持并发和异步有关。 任务/任务<T>,TPL的整个概念,LINQ-PLINQ的开发以及最后的异步/等待。 , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .