
认识到人工智能的重要性,英特尔正在朝着这个方向迈出又一步。 一个月前,在Hot Chips 2019大会上,该公司正式推出了两种专门用于神经网络训练和推理的专用芯片。 这些芯片分别命名为Intel Nervana NNP-
T (神经网络处理器)和Intel Nervana NNP-
I 。 在切口下,您会发现新产品的特征和方案。
英特尔Nervana NNP-T(春冠)
神经网络训练时间以及能源效率是AI系统的关键参数之一,它决定了其应用范围。 最大型的模型和训练集使用的计算能力每三个月翻一番。 同时,在神经网络中只使用了有限的计算集,主要是卷积和矩阵乘法,这为优化开辟了广阔的空间。 理想情况下,我们需要的设备应该在功耗,通信,计算能力和可伸缩性方面达到平衡。
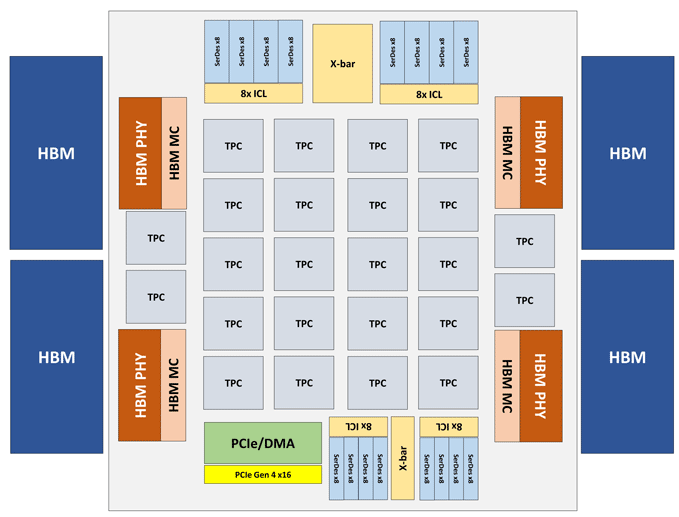
英特尔Nervana NNP-T模块以PCIe 4.0 x16或OAM卡的形式制成。 NNP-T的主要计算元素是24件张量处理集群(TPC),可提供119种TOPS性能。 通过4个HBM端口连接了总共32 GB的HBM2-2400内存。 板上还有一个在64行,SPI,I2C,GPIO接口上的串行化/反序列化单元。 芯片上的分布式内存量为60 MB(每个TPC 2.5 MB)。
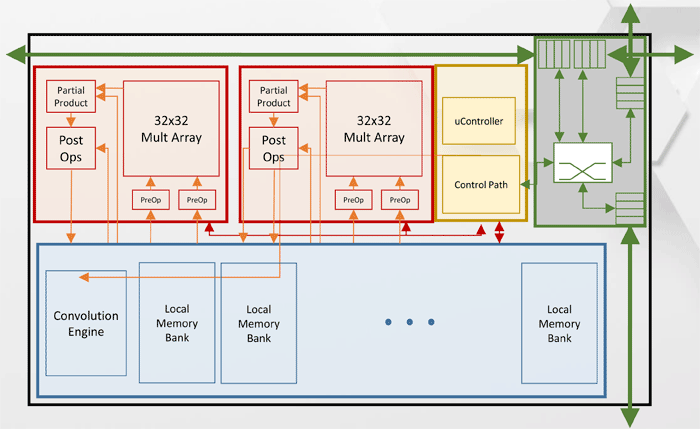 张量处理集群(TPC)架构
张量处理集群(TPC)架构其他英特尔Nervana NNP-T性能规格。
从图中可以看到,每个TPC具有两个支持BFloat16的32x32矩阵乘法内核。 其他操作以BFloat16或FP32格式执行。 一台主机上最多可以安装8张卡,最大可扩展性-最多1024个节点。
英特尔Nervana NNP-I(Spring Hill)
在设计英特尔Nervana NNP-I时,其目的是根据大型数据中心的规模提供最大的能源效率-大约5 TOP /W。
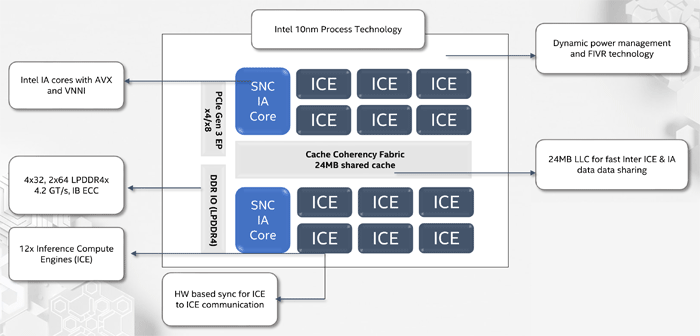
NNP-I是一种根据10纳米制程技术制造的SoC,包括两个支持AVX和VNNI的标准x86内核,以及12个专用的推理计算引擎(ICE)内核。 最高性能为92 TORS,TDP-50瓦。 内部存储器容量为75 MB。 在结构上,该设备以扩展卡M.2的形式制成。
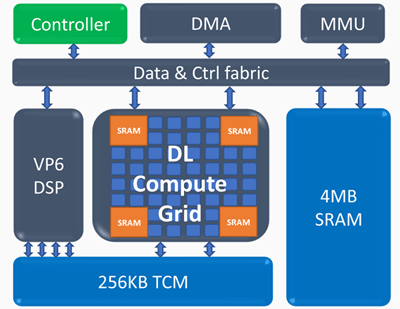 推理计算引擎(ICE)架构
推理计算引擎(ICE)架构推理计算引擎的关键要素:
深度学习计算网格- 每个周期4k MAC(int8)
- 可扩展支持FP16,INT8,INT 4/2/1
- 大量的内部存储器
- 非线性运算和池化
可编程向量处理器- 高性能-5 VLIW 512 b
- 扩展的NN支持-FP16 / 16b / 8b
获得了以下英特尔Nervana NNP-I的性能指标:在50层ResNet网络上,能耗为10 W,每秒实现3600次推理的速度,即,以瓦特为单位,能源效率为每秒360张图像。