
工作环境中的问题总是灾难。 它发生在您回家时,原因总是显得很愚蠢。 最近,我们在Kubernetes集群中的节点上用尽了内存,尽管该节点立即恢复了,没有明显的中断。 今天,我们将讨论此案,遭受的损害以及将来如何避免类似问题。
案例一
2019年6月15日星期六下午5:12
蓝色斗牛士(是的,我们要进行自我监控!)生成警报:Kubernetes生产集群中一个节点上的事件-SystemOOM。
17:16
Blue Matador会发出警告:EBS突发平衡在节点的根卷(发生SystemOOM事件的根卷)上较低。 尽管在收到有关SystemOOM的通知之后出现了有关突发余额的警告,但实际的CloudWatch数据显示突发余额已在17:02达到最低水平。 延迟的原因是EBS指标始终落后10-15分钟,并且我们的系统无法实时捕获所有事件。
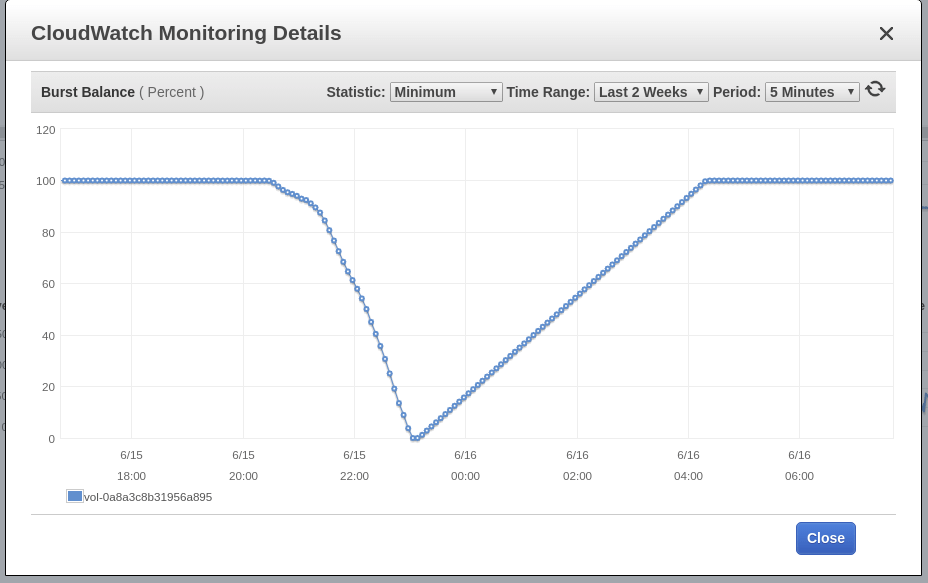
17:18
现在,我看到了警报和警告。 我迅速运行kubectl get pods来查看我们遭受了什么破坏,而我惊讶地发现应用程序中的pods恰好是0 死掉的 。 的确,它已经恢复并且使用了大约60%的内存。 现在是下午5点,精酿啤酒已经开始升温。 在确保节点正常运行并且没有损坏单个吊舱之后,我确定发生了事故。 如果有的话,我周一会解决。
这是我们当晚与Slack服务站的往来信件:

案例二
2019年6月16日星期六晚上6:02
蓝色斗牛士会生成警报:该事件已经在另一个节点上,也就是SystemOOM。 当时肯定是服务站只是在看着智能手机的屏幕,因为它写信给我,让我立即参加该活动,我本人无法打开计算机(是时候重新安装Windows了吗?)。 再说一次,一切似乎都很正常。 没有一个Pod被杀死,该节点几乎不消耗70%的内存。
18:06
蓝色斗牛士再次发出警告:EBS爆炸平衡。 一天第二次,这意味着我无法解决这个问题。 在CloudWatch保持不变的情况下,Burst Balance在发现问题之前2个小时或更长时间偏离了标准。
18:11
我转到Datalog,查看有关内存消耗的数据。 我看到在SystemOOM事件发生之前,可疑节点确实占用了大量内存。 这条小路通向我们流利的豆荚。

在发生SystemOOM事件的大约同一时间,您可以清楚地看到内存消耗的急剧变化。 我的结论是:这些容器占用了所有内存,当SystemOOM发生时,Kubernetes意识到可以杀死这些容器并重新启动以返回必要的内存,而不会影响我的其他容器。 干得好,Kubernetes!
那么,为什么周六我发现哪个吊舱重新启动时却没有看到这个? 事实是,我在一个单独的命名空间中运行了流利的Sudology Pod,匆匆忙忙地不想去研究它。
结论1:寻找重新启动的Pod时,请检查所有名称空间。
接收到这些数据后,我计算出第二天其他节点上的内存将不会结束,但是,我继续并重新启动了所有Sumicologic Pod,以便它们以低内存消耗开始工作。 第二天早上,我计划提出如何将有关该问题的工作整合到一周的计划中,而在周日晚上则不会增加过多的工作量。
23:00
我观看了下一个系列的《黑镜》(顺便说一句,我喜欢麦莉),决定看一下集群的运行情况。 内存消耗是正常的,因此可以随意保留一切,一整夜。
修复
星期一,我花了一些时间解决这个问题。 每天晚上和她一起狩猎并没有什么害处。 我目前所知道的:
- 流利的容器包装吞噬了大量的记忆;
- SystemOOM事件之前有大量磁盘活动,但我不知道是哪一个。
起初,我以为流利的容器可以接受,以便在原木突然涌入时吃掉记忆。 但是,在对Sumologic进行检查之后,我发现日志已稳定使用,并且在出现问题的同时,这些日志没有增加。
稍作搜索,我在github上发现了此任务,该任务建议调整一些Ruby设置-以减少内存消耗。 我决定尝试一下,在pod规范中添加一个环境变量并运行它:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
浏览流畅的摘要清单时,我注意到我没有定义资源请求和限制。 我开始怀疑RUBY_GCP_HEAP修复程序会产生某种奇迹,因此现在可以设置内存消耗限制。 即使我不解决内存问题,也至少可以将其消耗限制在这组Pod中。 使用kubectl顶部吊舱| grep fluentd-sumologic ,我已经知道需要多少资源:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
结论2:设置资源限制,尤其是对于第三方应用程序。
执行验证
几天后,我确认上述方法有效。 内存消耗稳定,并且-Kubernetes,EC2和EBS的任何组件都没有问题。 现在,很明显,确定我运行的所有pod的资源请求和限制有多么重要,这是需要做的事情:应用默认资源限制和资源 配额的某种组合。
最后一个未解之谜是EBS突发平衡,它与SystemOOM事件一致。 我知道,当内存不足时,操作系统会使用交换区,以免完全没有内存。 但是我不是昨天出生的,我知道Kubernetes甚至不会在激活交换文件的服务器上启动。 我只是想确保,我通过SSH进入了我的节点-检查页面文件是否被激活; 我同时使用了可用内存和交换区域中的可用内存。 该文件未激活。
而且由于交换不起作用,所以我有更多线索了解导致I / O流增加的原因,这就是为什么节点几乎用尽内存的原因。 总的来说,我有一个预感:流利的Sud pod本身此时正在编写大量日志消息,甚至可能是与设置Ruby GC相关的日志消息。 还有可能还有其他Kubernetes来源或日记消息在内存用尽时变得过分生产,我在设置流畅的同时就消除了它们。 不幸的是,我不再有权访问发生故障之前立即记录的日志文件,现在我无法进行更深入的研究。
结论3:尽管有机会,但在分析根本原因时,无论出现什么问题,都应更深入地研究。
结论
而且,尽管我没有找到原因的根本原因,但我确信不需要它们来防止将来发生相同的故障。 时间就是金钱,但是我忙了太久了,之后我还为您写了这篇文章。 而且由于我们使用Blue Matador ,因此对此类故障进行了详细处理,因此我允许自己放下刹车,而不会分散主项目的注意力。