近一年来,我一直在使用Yandex音乐服务,一切都适合我。 但是此服务中有一个有趣的页面-历史记录。 它按时间顺序存储已收听的所有曲目。 当然,我想下载它并分析我一直听到的声音。

第一次尝试
开始处理此页面时,我立即遇到了问题。 该服务不会一次下载所有曲目,而只会在您滚动时下载。 我不想下载嗅探器并了解流量,并且那时我还没有技巧。 因此,我决定通过使用硒模拟浏览器来简化操作。
该脚本已编写。 但是他工作很不稳定而且很长时间。 但是他确实设法载入了故事。 经过简单分析,我保留了脚本的任何修改,直到一段时间后,我再次不想下载该故事。 希望达到最好,我推出了它。 而且,当然,他犯了一个错误。 然后我意识到是时候该做所有的事情了。
工作选项
为了进行流量分析,我自己选择了Fiddler,因为它与httpshark不同,因为它具有更强大的HTTP流量界面。 运行嗅探器,我希望看到带有令牌的api请求。 但是没有 我们的目标是在music.yandex.ru/handlers/library.jsx 。 对此的要求需要站点上的完全授权。 我们将从她开始。
登入
这里没什么复杂的。 我们转到passport.yandex.ru/auth ,找到请求的参数并提出两个授权请求。
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
这样我们就登录了。
下载记录
接下来,转到music.yandex.ru/user/<user>/history ,我们在其中还选择了一些参数,这些参数在接收有关曲目的信息时对我们有用。 现在您可以下载故事。 我们在music.yandex.ru/handlers/library.jsx使用参数{'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'}获取music.yandex.ru/handlers/library.jsx {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} 。 我对这里的ncrnd参数感兴趣。 发出请求时,Yandex始终为该参数分配不同的值,但所有操作均相同。 返回时,我们以id轨道和有关前十个轨道的详细信息的形式获得历史记录。 从详细的跟踪信息中,您可以保存很多有趣的数据以供以后分析。 例如,发行年份,曲目持续时间和类型。 有关其余曲目的信息可从music.yandex.ru/handlers/track-entries.jsx获得。 我们将所有这些业务保存在csv中,然后进行分析。
分析方法
为了进行分析,我们使用pandas和matplotlib形式的标准工具。
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
将python的None更改为NaN并将其丢弃。
df = df.replace('None', pd.np.nan).dropna()
让我们从一个简单的开始。 让我们看看我们花在听所有曲目上的时间
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
但是在这里您可以争论这个数字的准确性,因为尚不清楚您需要听曲目的哪一部分,Yandex将其添加到了故事中。
现在,让我们看一下发行年份的曲目分布。
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
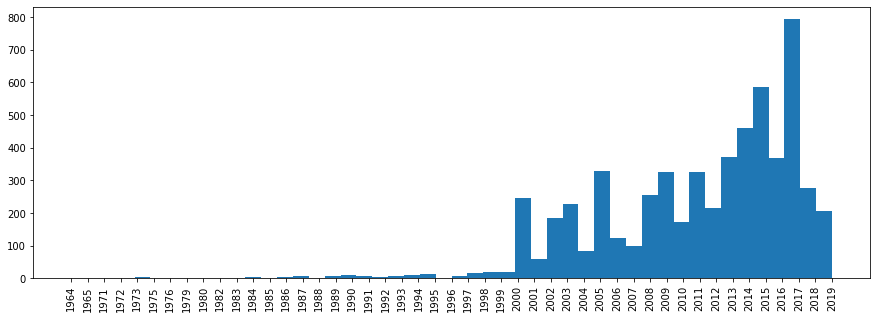
在这里,事情并不是那么简单,因为“最佳歌曲”的多样化收藏将在下一年推出。
其他统计数据将基于非常相似的原理。 我将举一个听得最多的曲目的例子
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
和该艺术家最常播放的曲目
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
完整的代码可以在这里找到。