哈Ha
在
上一部分中 ,对该站点的用户的消息进行了分析,从而引起了关于各种参数(消息数量,等级,“业力”等)主题的热烈讨论。 这样的问题已经积累到足以构成第二部分了。
那些对本年度评论中最大讨论的持续时间长短,用户的最大和最小“业力”可能是什么以及其他统计数据感兴趣的人,我要求得到帮助。
资料收集
首先,我必须补充解析器,以便它可以收集更多数据。 有关消息的等级和消息在线程中的位置的信息已经在HTML中,但是为了获得用户的“业力”,必须提出一个附加请求。 当然,这些值被缓存,以便同一用户不再多次请求数据。
现在,更新后的数据集如下所示(删除了用户昵称):
https://habr.com/ru/post/322900/,comment_19707920,comment_19706258,UserXXXX,karma:112.2,answers:1,2019-02-04 20:26:00,rating:1,up:1,down:0, ?
https://habr.com/ru/company/mailru/blog/351212/,comment_19794710,comment_19794310,UserXXXX,karma:-10.0,answers:1,2019-02-23 18:16:00,rating:3,up:5,down:-2,
...
从其他字段中,添加了答案字段(答案数),用户的业力以及正面和负面的评分。
例如,通过用户的昵称获取“业力”的功能如下所示:
def get_karma(user: str): data_html = get_as_str("https://habr.com/ru/users/%s/" % user) karma = data_html.find_between('info/help/karma/', '</a>').find_between('stacked-counter__value', '/div>').find_between('>', '<').replace(",", ".").replace('–', '-') return float(karma) if len(karma) > 0 else 0.0
如您所见,一切都非常简单,没有火箭科学。 我们还应该感谢Habr程序员提供清晰易懂的HTML代码。
此2019年所得CSV文件的大小为334 MB。 您可以开始分析。 在开始之前,我提醒您所有已发布的数据都是公开和公开的,搜索引擎也会对它们进行索引。 我没有内幕信息,所有内容均摘自该网站的页面。
业力
如上一部分所示,“业力问题”是最令人感兴趣的,所以让我们开始吧。 如您所知,“业力”是该网站任何活跃用户的属性,参与者可以选择增加或减少它。 坦白说,我从来没有问过它是如何工作以及它有什么限制的问题,所以我只给出数据而无需任何特殊评论。
总计,在收集评级时,网站上有
25,109个用户 ,这些
用户至少一次发表了至少一条评论。 其中,9973位用户(占39%)的
业力为零 。 12346个用户(49%)的
业力为
正 ,其中5384个用户(21%)的
业力<= 4且
> 40 =业力 (此级别允许您参与“奖励计划”并获得商品付款)有1,522用户(6 %)。 2790位使用者(11%)的
业障为负 。
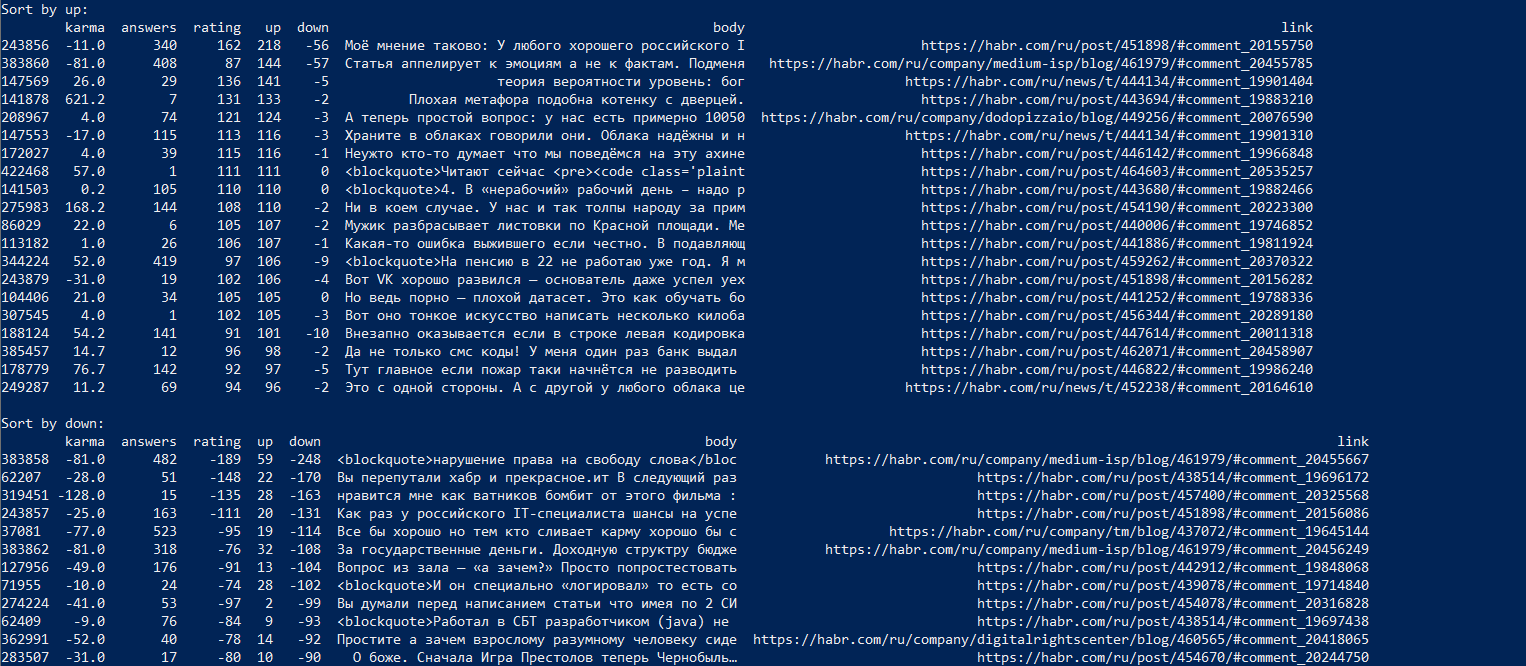
图形上,分布的主要部分如下所示:

垂直-具有这种业障的用户数。 图表裁剪在顶部,因为 最大业力为零的用户(9973对2570,“业力”为1)。 “志趣相投”的用户并不多,但是时间表却转移到了一个加号上,这很令人满意。 因果报应有多高?
十大业力等级由
Zelenyikot (+1509.2),
Milfgard (+1471.0),
m1rko (+1039.5),
PatientZero (+986.0),
Boomburum (+881.9),
ValdikSS (+873.5),
alizar (+837.5),
tangro占据 (+802.5),
lozga (+764.7)和
DIHALT (696.1)。 我认为可以恭喜他们-做得好,伙计:)如果我想念别人-用私人短信写信,我会手动添加。
顺便说一下,事实证明,我的karmareiting计算函数存在错误-它不能正确处理大于1000的值(Habr在数字上加了一个空格,我不知道这一点),但是这种情况很少见,我没有马上注意到。
他们采用业力的
Antitope-10 ...不,我可能不会
透露他们的昵称,以免使这样的用户成为有兴趣的“广告”,他们可以从扰流板下方的屏幕快照中获取数据。 当然,该站点上的负面因果报应只说一个人对该站点表达了不受欢迎的观点,并且不对自己的个人素质说任何话,因此,请那些不属于“对立面”的人受到冒犯。
留言内容
在消息中,您还可以找到很多有趣的东西。
前5条消息的长度分别为26、17、16、15和
14 KB。
以图形形式查看分布很有趣:

如您所见,峰值落在大约100个字符的消息上。
等级
评分最高的消息:
+ 218 ,
+144 ,
+141 ,
+133和
+124 。
评分最高的消息是
-248 ,
-170 ,
-163 ,
-131和
-114 。
有趣的是,根据评级,消息数量的分布与“业力”的分布大致相似-消息的评价既有正面评价也有负面评价,但有更多的“正面”评价。 再次,不禁高兴。
讨论区
下一个有趣的问题是在消息中找到最长的线程。 事实证明,这样做非常简单-HTML中的每个消息都有一个唯一的标识符,还有一个data-parent_id参数,其余的,正如他们所说的,是技术问题。
因此,2019年讨论时间最长:
619个答案 ,
618个答案 ,
614个答案 ,
556个答案和
553个答案 。 有趣的是,导致这些线程的5条消息中有4条是由业力小于-20的用户编写的。
根据对它们的答复数量将这些注释分组:
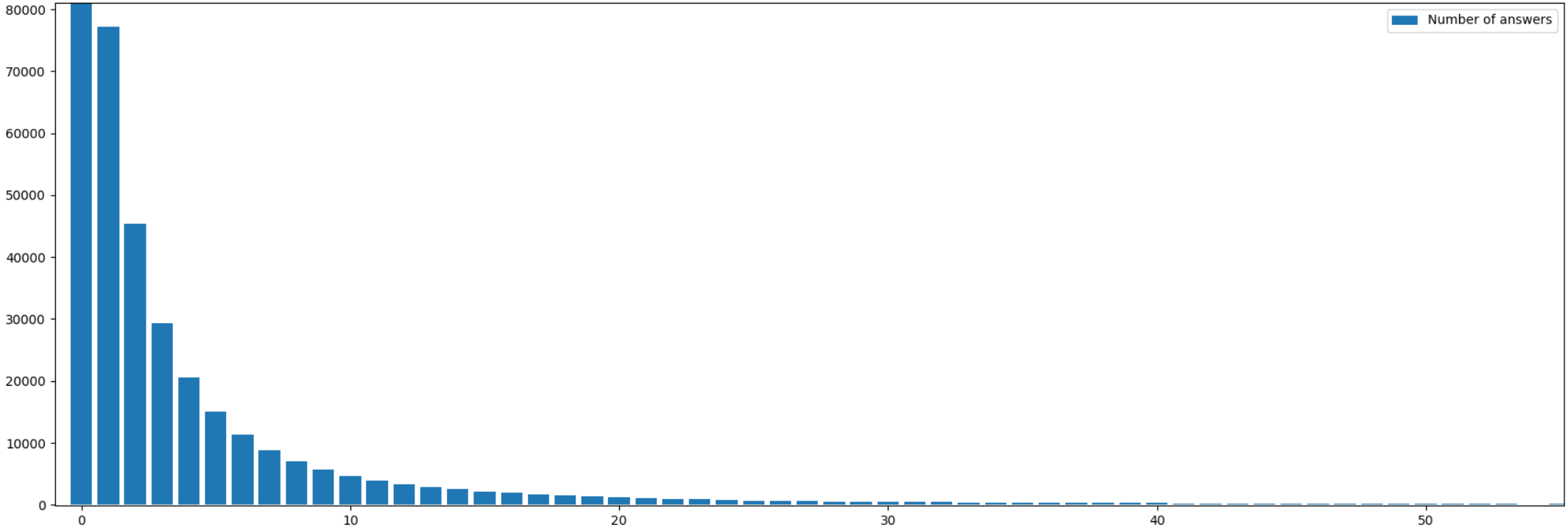
垂直-今年的职位数。 大部分评论(41%或183000)根本没有任何回应,7.5万条评论有1个答案,可以在图片中看到进一步的分布。
结论
在此之前,我将完成“ habrastatistics”的主题,直到一月-到今年年底,将发布2019年最佳文章的最终评级,好吧,可能还会有其他有趣的模式。
我希望这很有趣。 如果我忘记了某人,请写,改正。