可以在此链接上找到完整的俄语课程。
此链接提供原始英语课程。

目录内容
- 塞巴斯蒂安·特伦的采访
- 引言
- 转移学习模型
- 移动网
- CoLab:受过培训的猫对狗
- 进入卷积神经网络
- 实际部分:通过培训转移确定颜色
- 总结
塞巴斯蒂安·特伦的采访
-这是第6课,它完全致力于转移学习。 学习转移是使用现有模型的过程,对新任务的改进很少。 训练的转移通过在开始学习时提高效率来帮助减少模型的训练时间。 塞巴斯蒂安,您如何看待培训转移? 您曾经在工作和研究中使用过教学转移方法吗?
-我的论文专门针对培训转移的主题,被称为“ 基于培训转移的解释 ”。 当我们进行论文研究时,我们的想法是可以教导以各种变化形式和格式区分一个对象(数据集,实体)上的所有其他此类对象。 在工作中,我们使用了开发的算法,该算法可以区分对象的主要特征(属性),并将其与另一个对象进行比较。 像Tensorflow这样的库已经带有预训练的模型。
-是的,在Tensorflow中,我们有一套完整的预训练模型,您可以用来解决实际问题。 稍后我们将讨论现成的场景。
-是的,是的! 如果您考虑一下,那么人们将终生从事培训的转移。
-我们可以说,由于采用了转移培训的方法,我们的新学生在某个时候将不必了解机器学习的知识,因为它足以连接已经准备好的模型并使用它?
-编程是逐行编写的,我们向计算机提供命令。 我们的目标是通过仅向计算机提供输入数据示例来确保地球上的每个人都能编程。 同意,如果您想教一台计算机来区分猫和狗,那么找到100k张不同的猫图像和100k张不同的狗图像是非常困难的,而且由于进行了培训,您可以在几行中解决此问题。
-是的,确实是! 谢谢您的回答,让我们最后继续学习。
引言
-您好,欢迎回来!
-上次我们训练了卷积神经网络对图像中的猫和狗进行分类。 我们对第一个神经网络进行了重新训练,因此其结果并不是很高-准确率约为70%。 之后,我们实施了数据扩展和数据删除(神经元的任意断开连接),这使我们可以将预测的准确性提高到80%。
-尽管80%似乎是一个很好的指标,但20%的误差仍然太大。 对不对 我们怎样做才能提高分类的准确性? 在本课程中,我们将使用知识转移技术(知识模型的转移),这将使我们能够使用由专家开发并受过巨大数据阵列训练的模型。 正如我们将在实践中看到的那样,通过转移知识模型,我们可以达到95%的分类精度。 让我们开始吧!
学习模型转移
在2012年,AlexNet神经网络赢得了ImageNet大规模视觉识别挑战,彻底改变了机器学习领域,并普及了使用卷积神经网络进行分类。
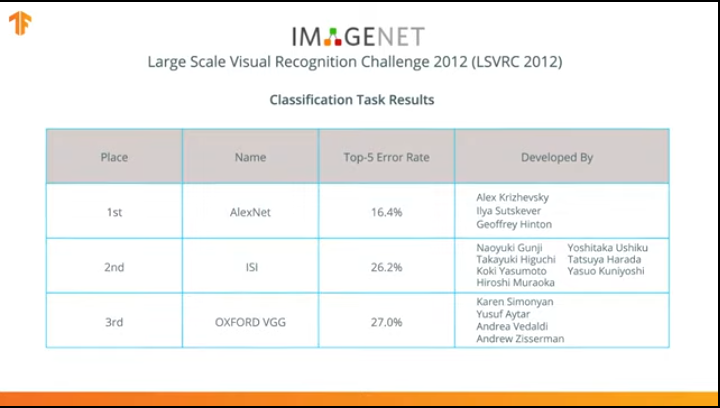
此后,人们开始努力开发更准确,高效的神经网络,在对ImageNet数据集中的图像进行分类的任务中,可能会超过AlexNet。
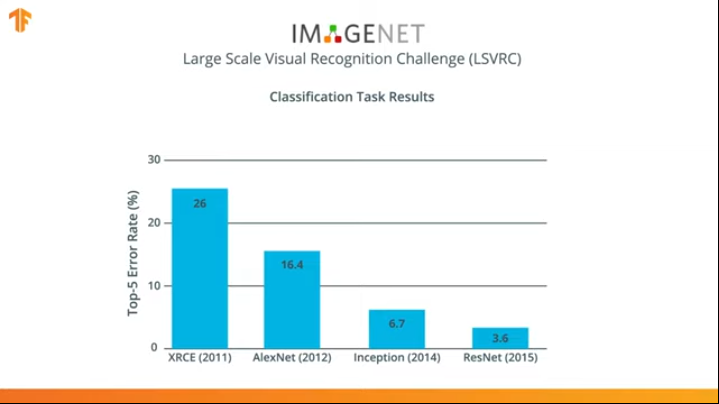
几年来,神经网络已经比AlexNet-Inception和ResNet更好地解决了分类任务。
同意能够利用已经在ImageNet的巨大数据集上训练过的这些神经网络并在您的猫狗分类器中使用它们会很棒吗?
事实证明,我们可以做到! 该技术称为转移学习。 传输训练模型的方法的主要思想是基于这样的事实,即在大型数据集上训练了神经网络之后,我们可以将获得的模型应用于该模型尚未遇到的数据集。 这就是为什么将该技术称为转移学习的原因-将学习过程从一个数据集转移到另一个数据集。
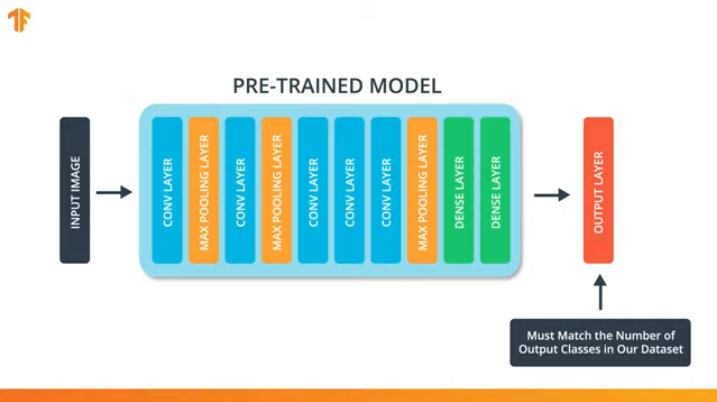
为了使我们能够应用传递训练模型的方法,我们需要更改卷积神经网络的最后一层:
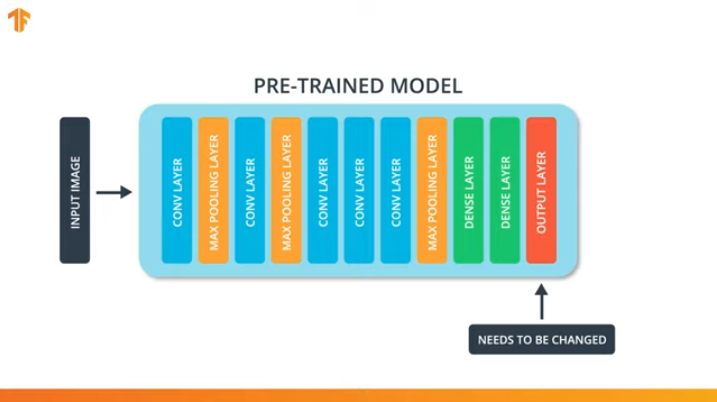
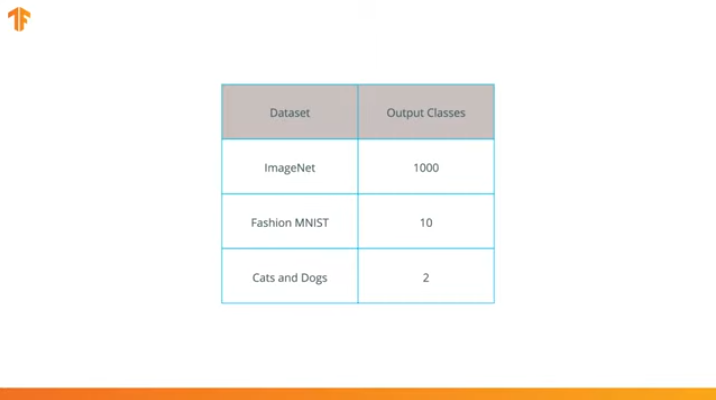
我们执行此操作是因为每个数据集都包含不同数量的输出类别。 例如,ImageNet中的数据集包含1000个不同的输出类。 FashionMNIST包含10个课程。 我们的分类数据集仅包含2类-猫和狗。
这就是为什么有必要更改卷积神经网络的最后一层,使其包含与新集中的类数相对应的输出数的原因。
我们还需要确保在训练过程中不要更改预先训练的模型。 解决方案是关闭预训练模型的变量-我们只是禁止算法在向前和向后传播期间更新值以更改它们。
此过程称为“冻结模型”。
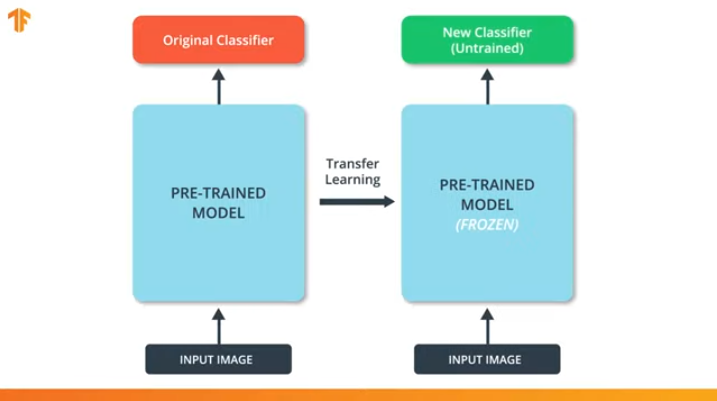
通过“冻结”预训练模型的参数,我们允许我们仅学习分类网络的最后一层,预训练模型的变量值保持不变。
预训练模型的另一个无可争议的优势是,我们仅通过训练变量数量少得多的最后一层而不是整个模型来减少训练时间。
如果我们不“冻结”预训练模型的变量,则在训练过程中,变量的值将在新数据集上更改。 这是因为分类最后一层的变量值将填充随机值。 由于最后一层的随机值,我们的模型将在分类中犯重大错误,这反过来又将导致预训练模型的初始权重发生重大变化,这对我们来说是极不希望的。
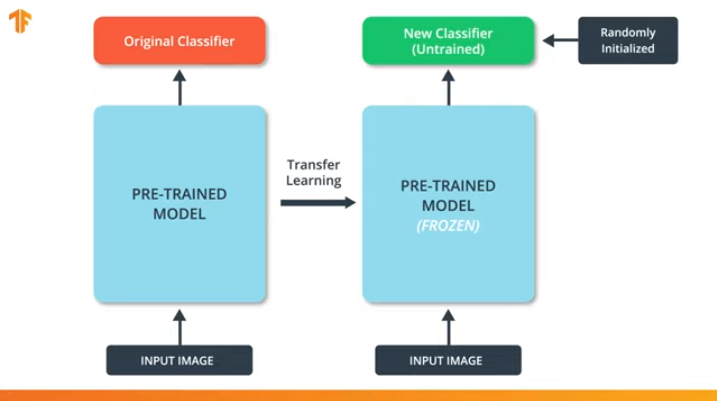
出于这个原因,我们应该始终记住,在使用现有模型时,变量的值应该被“冻结”,并且应该关闭训练预训练模型的需要。
既然我们知道了训练模型的传递是如何工作的,我们只需要选择一个预先训练的神经网络就可以在我们自己的分类器中使用! 我们将在下一部分中进行此操作。
移动网
正如我们前面提到的,开发了非常有效的神经网络,该网络在ImageNet数据集上显示了很高的结果-AlexNet,Inception,Resonant。 这些神经网络是非常深的网络,包含成千上万个参数。 大量参数允许网络学习更多复杂的模式,从而提高分类精度。 神经网络的大量训练参数会影响学习速度,存储网络所需的内存量以及计算的复杂性。
在本课程中,我们将使用现代卷积神经网络MobileNet。 MobileNet是一种高效的卷积神经网络体系结构,可减少用于计算的内存量,同时保持高精度的预测。 因此,MobileNet非常适合在内存和计算资源有限的移动设备上使用。
MobileNet由Google开发,并接受ImageNet数据集的培训。
由于从ImageNet数据集中对MobileNet进行了1,000个类别的培训,因此MobileNet具有1,000个输出类别,而不是我们需要的两个输出类别(猫和狗)。
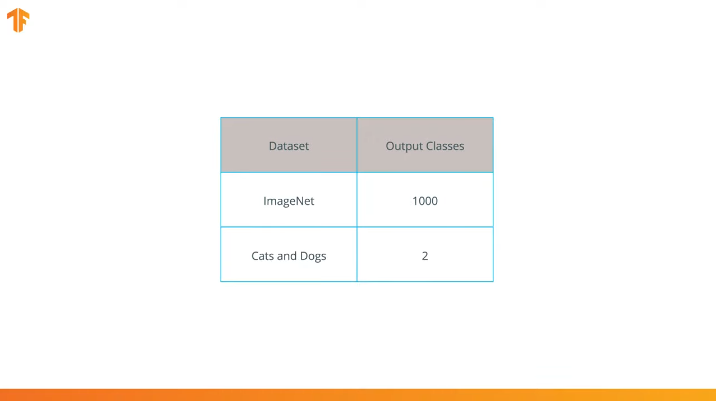
为了完成训练的传递,我们预载了没有分类层的特征向量:

在Tensorflow中,加载的特征向量可以用作具有特定大小的输入数据的常规Keras图层。
由于MobileNet是在ImageNet数据集上进行训练的,因此我们需要将输入数据的大小带到训练过程中使用的那些数据中。 在我们的案例中,MobileNet在224x224px固定大小的RGB图像上进行了训练。
TensorFlow包含一个经过预训练的存储库,称为TensorFlow Hub。
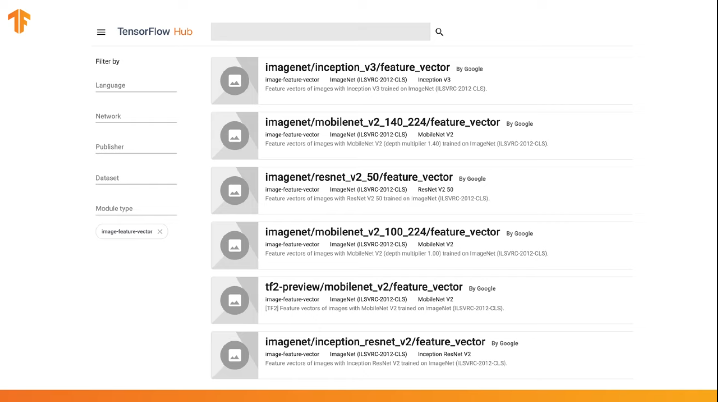
TensorFlow Hub包含一些经过预训练的模型,其中从神经网络的架构中排除了最后一个分类层,以供后续重用。
您可以在几行代码中使用TensorFlow Hub:

只需指定所需训练模型的特征向量的URL,然后将该模型嵌入具有所需输出类数的最后一层的分类器中即可。 这是将接受训练和更改参数值的最后一层。 我们新模型的编译和培训以与以前相同的方式进行:
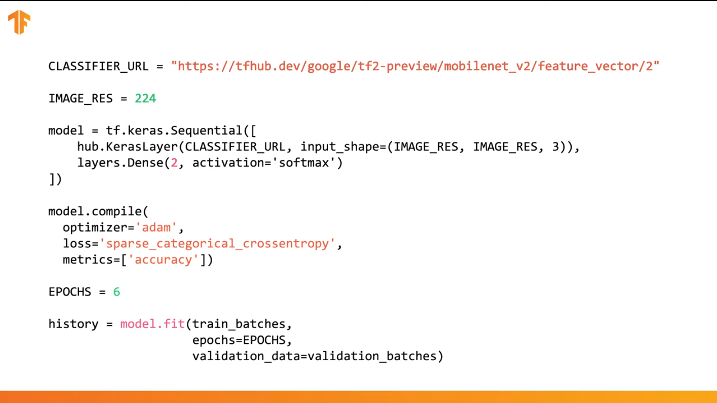
让我们看看它如何实际工作并编写适当的代码。
CoLab:受过培训的猫对狗
链接到俄语的 CoLab和英语的CoLab 。
TensorFlow Hub是一个包含我们可以使用的预训练模型的存储库。
学习转移是一个过程,我们采用预先训练的模型并将其扩展以执行特定任务。 同时,我们保留了集成到神经网络中的预训练模型部分,但只训练最后的输出层以获得所需的结果。
在这一实际部分中,我们将测试这两个选项。
该链接使您可以浏览可用模型的整个列表。
在Colab的这一部分
- 我们将使用TensorFlow Hub模型进行预测;
- 我们将对猫和狗的数据集使用TensorFlow Hub模型;
- 让我们使用TensorFlow Hub中的模型来传递训练。
在继续执行当前实际部分之前,我们建议重置Runtime -> Reset all runtimes...
图书馆进口
在本实用部分中,我们将使用许多正式版本中尚未使用的TensorFlow库功能。 这就是为什么我们将首先为开发人员安装TensorFlow和TensorFlow Hub版本的原因。
安装TensorFlow开发版本会自动激活最新安装的版本。 在处理完此实际部分之后,建议您通过菜单项Runtime -> Reset all runtimes...恢复TensorFlow设置并返回到稳定版本。 执行此命令会将所有环境设置重置为原始设置。
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
结论:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
我们之前已经看过并使用过一些导入。 从新安装的import tensorflow_hub ,我们已安装并在本实际部分中将使用它。
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
结论:
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
第1部分:使用TensorFlow Hub MobileNet进行预测
在CoLab的这一部分中,我们将采用预先训练的模型,将其上传到Keras并进行测试。
我们使用的模型是MobileNet v2(可以使用具有tfhub.dev的任何其他tf2兼容图像分类器模型代替MobileNet)。
下载分类器
下载MobileNet模型并从中创建Keras模型。 输入端的MobileNet期望接收3个颜色通道(RGB)的尺寸为224x224像素的图像。
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
在单个图像上运行分类器
MobileNet已经在ImageNet数据集上进行了培训。 ImageNet包含1000个输出类别,其中一个类别是军服。 让我们找到将要穿着军装的图像,该图像将不属于ImageNet培训工具包中以验证分类准确性。
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
结论:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
结论:
(224, 224, 3)
请记住,模型始终会收到一组(块)图像供输入处理。 在下面的代码中,我们添加了一个新的维度-块大小。
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
结论:
(1, 1001)
预测的结果是一个大小为1,001个元素的向量,其中每个值代表图像中的对象属于某个类别的概率。
可以使用argmax函数找到最大概率值的位置。 但是,还有一个问题我们仍未回答-如何确定某个元素属于哪个类别的可能性最大?
predicted_class = np.argmax(result[0], axis=-1) predicted_class
结论:
653
破译预测
为了确定预测所涉及的类别,我们上载了ImageNet标签列表,并通过保真度最大的索引来确定预测所涉及的类别。
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
结论:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

宾果! 我们的模型正确识别了军装。
第2部分:将TensorFlow Hub模型用于猫和狗数据集
现在,我们将使用MobileNet模型的完整版本,并查看它如何处理猫和狗的数据集。
数据集
我们可以使用TensorFlow数据集下载猫和狗的数据集。
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
结论:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
并非猫和狗数据集中的所有图像都具有相同的大小。
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
结论:
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
因此,从获得的数据集中获得的图像需要缩小为单个尺寸,MobileNet模型期望该尺寸为输入224 x 224。
这里.repeat()函数和steps_per_epoch ,但是它们使您每次训练迭代可以节省约15秒,因为 在学习过程的最开始,临时缓冲区只需初始化一次。
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
在图像集上运行分类器
让我提醒您,在此阶段,仍然有一个完整版本的预训练MobileNet网络,其中包含1,000个可能的输出类。 ImageNet包含大量的猫和狗的图像,因此,让我们尝试从数据集中输入其中一张测试图像,看看该模型将为我们提供什么预测。
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
结论:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
标签类似于猫和狗的品种名称。 现在让我们显示猫狗数据集中的一些图像,并在每个图像上放置一个预测标签。
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

第3部分:使用TensorFlow Hub实施学习转移
现在让我们使用TensorFlow Hub将学习从一种模型转移到另一种模型。
在传递训练的过程中,我们通过更改其最后一层或多层来重用一个预先训练的模型,然后在新的数据集上再次开始训练过程。
在TensorFlow Hub中,您不仅可以找到完整的预训练模型(具有最后一层),还可以找到没有最后分类层的模型。 后者可以很容易地用于转移训练。 出于以下简单原因,我们将继续使用MobileNet v2:在本课程的后续部分中,我们将转移此模型并使用TensorFlow Lite在移动设备上启动它。
我们还将继续使用猫和狗的数据集,因此我们将有机会将这种模型的性能与我们从头开始实现的模型进行比较。
请注意,我们使用TensorFlow Hub(没有最后一个分类层) feature_extractor调用了部分模型。 该名称由以下事实解释:模型接受数据作为输入,并将其转换为一组有限的所选属性(特征)。 因此,我们的模型完成了识别图像内容的工作,但没有在输出类别上产生最终的概率分布。 该模型从图像中提取了一组属性。
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
让我们通过feature_extractor运行一组图像,然后查看结果形式(输出格式)。 32-图像数量,1280-带TensorFlow Hub的预训练模型最后一层中的神经元数量。
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
结论:
(32, 1280)
我们“冻结”属性提取层中的变量,以便在训练过程中仅分类层变量的值发生变化。
feature_extractor.trainable = False
添加分类层
现在将来自TensorFlow Hub的层包装到tf.keras.Sequential模型中,并添加一个分类层。
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
结论:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
火车模型
现在,我们在调用compile然后进行fit训练之前,以与以前一样的方式来训练结果模型。
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
结论:
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
您可能已经注意到,我们在验证数据集上的预测准确率达到了97%。 太棒了! 与我们自己训练的第一个模型相比,当前方法已大大提高了分类准确度,并且获得了约87%的分类准确度。 原因是MobileNet是由专家设计的,经过长时间的精心开发,然后在庞大的ImageNet数据集上进行了培训。
您可以在此链接中了解如何在Keras中创建自己的MobileNet。
让我们在训练和验证数据集上构建准确性和损失值的变化图。
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
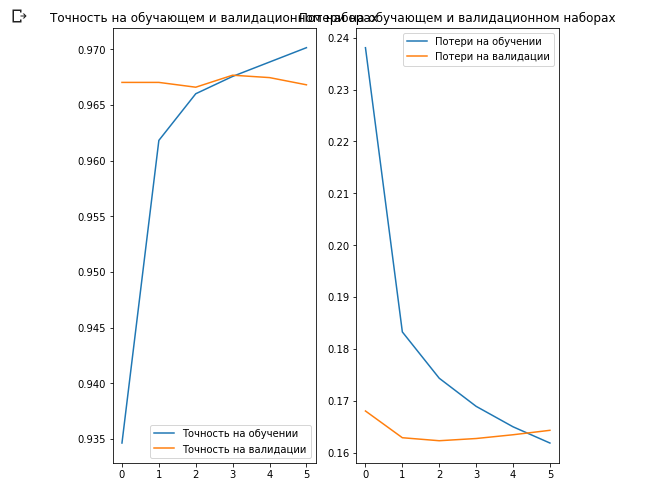
这里有趣的是,从学习过程的开始到结束,验证数据集的结果要优于训练数据集的结果。
此行为的一个原因是,在训练迭代结束时测量了验证数据集的准确性,并且将训练数据集的准确性视为所有训练迭代中的平均值。
出现这种现象的最大原因是使用了预先训练的MobileNet子网,该子网以前是在大型猫狗数据集上进行训练的。 在学习过程中,我们的网络将继续扩展输入的训练数据集(相同的扩充),而不是扩展验证集。 这意味着在训练数据集上生成的图像比来自已验证数据集的普通图像更难以分类。
检查预测结果
要重复上一节中的图,首先您需要获得一个排序的类名列表:
class_names = np.array(info.features['label'].names) class_names
结论:
array(['cat', 'dog'], dtype='<U3')
将带有图像的块传递通过模型,并将生成的索引转换为类名:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
结论:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
让我们看一下真实的标签并进行预测:
print(": ", label_batch) print(": ", predicted_ids)
结论:
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

进入卷积神经网络
使用卷积神经网络,我们设法确保它们能够很好地处理图像分类任务。 但是,目前,我们无法想象它们是如何工作的。 如果我们能够了解学习过程是如何发生的,那么从原则上讲,我们可以进一步改善分类工作。 理解卷积神经网络如何工作的一种方法是可视化层及其工作结果。 我们强烈建议您在此处学习材料,以更好地理解如何可视化卷积层的结果。

自卷积神经网络问世以来,计算机视觉领域就看到了隧道尽头的光芒,并取得了重大进展。 在过去的几年里,这一领域的研究速度惊人,互联网上发布的大量图像也取得了令人难以置信的结果。 卷积神经网络的兴起始于2012年由Alex Krizhevsky,Ilya Sutskever和Jeffrey Hinton创建的AlexNet,并赢得了著名的ImageNet大规模视觉识别挑战赛。 从那时起,毫无疑问,使用卷积神经网络的前景一片光明,而计算机视觉领域及其工作结果也证实了这一事实。 卷积神经网络从在手机上识别您的脸部到识别自动驾驶汽车中的物体开始,已经设法显示和证明其力量并解决了现实世界中的许多问题。
尽管有大量的大数据集和卷积神经网络的预训练模型,但有时仍然很难理解该网络的工作原理以及该网络的确切训练对象,特别是对于在机器学习领域没有足够知识的人们而言。 , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

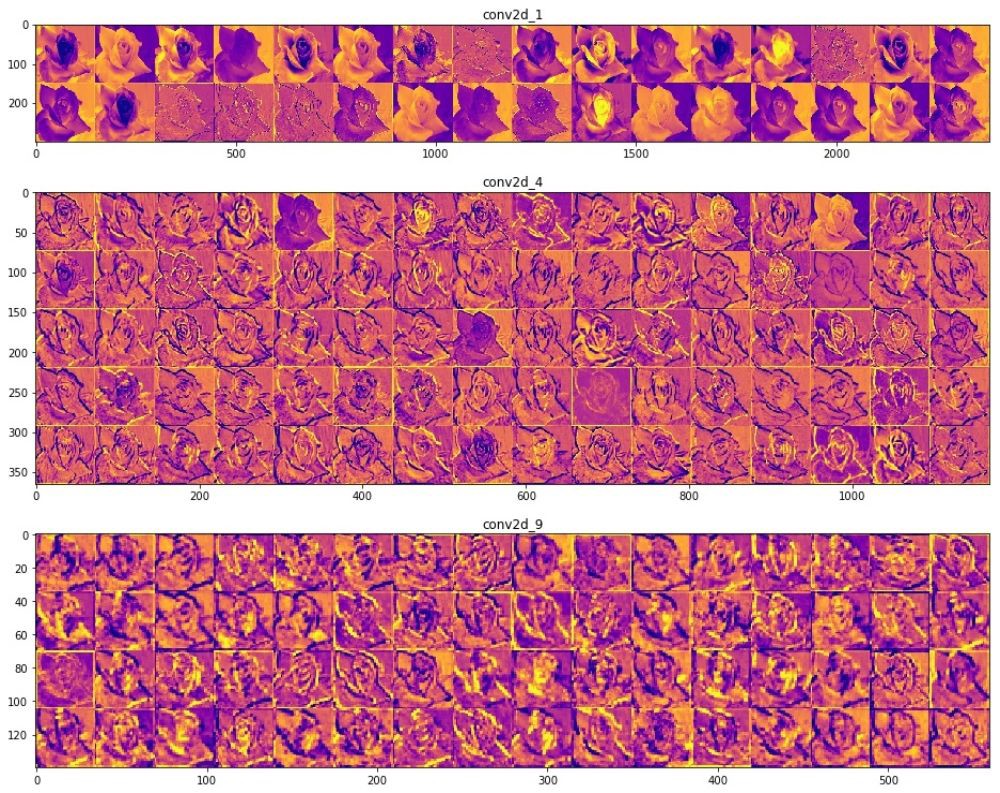
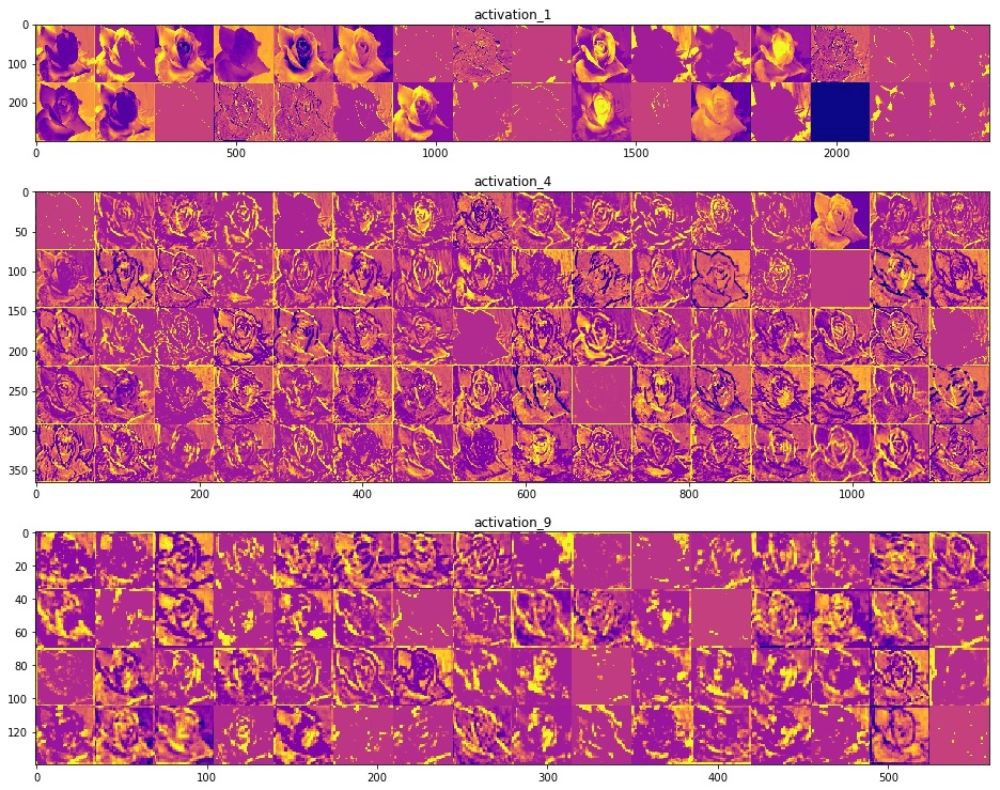
— . .
, () . (), , , , . , , , , .
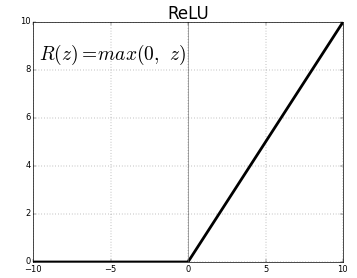
ReLU- . , ReLU(z) = max(0, z) .
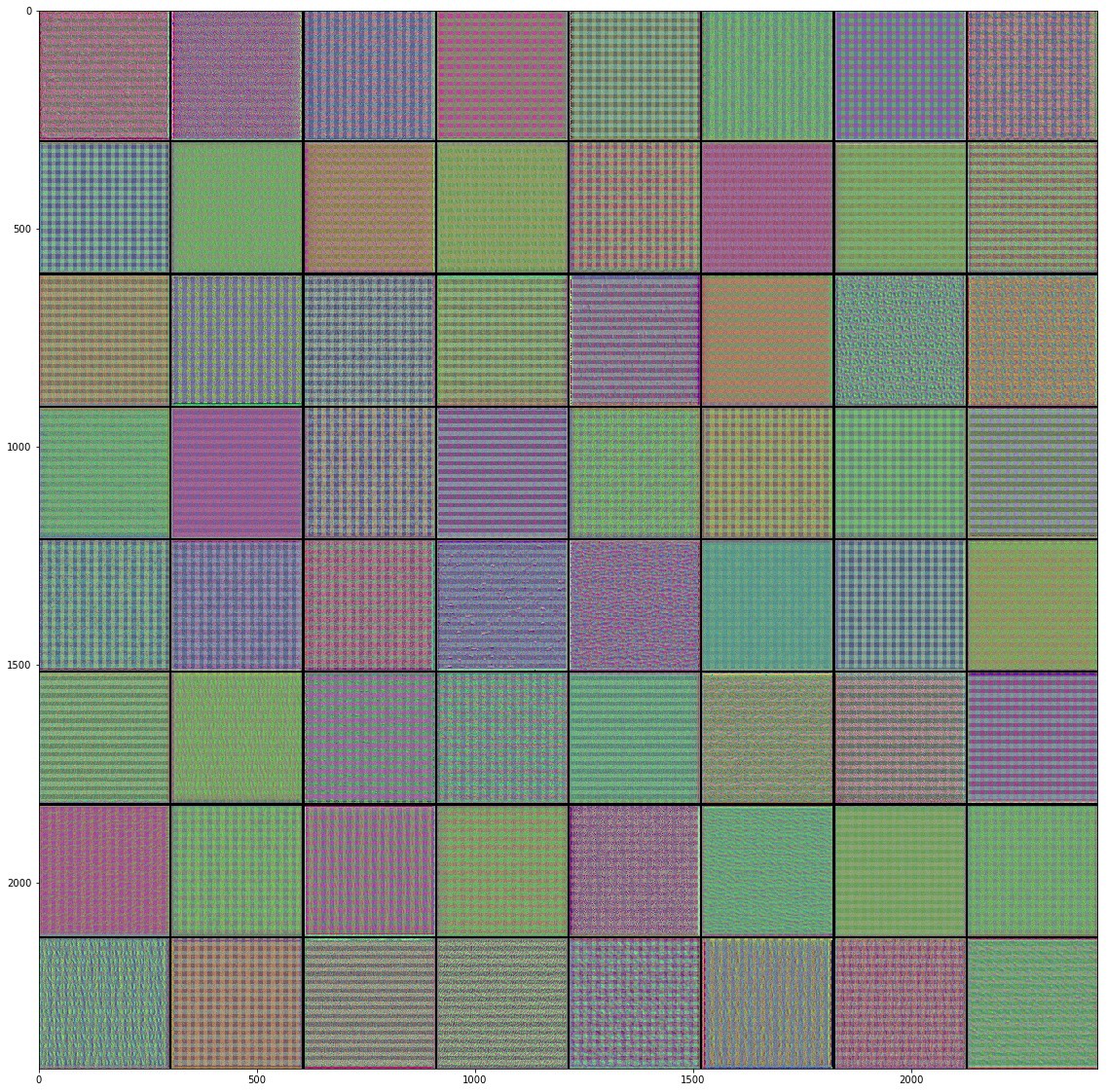
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
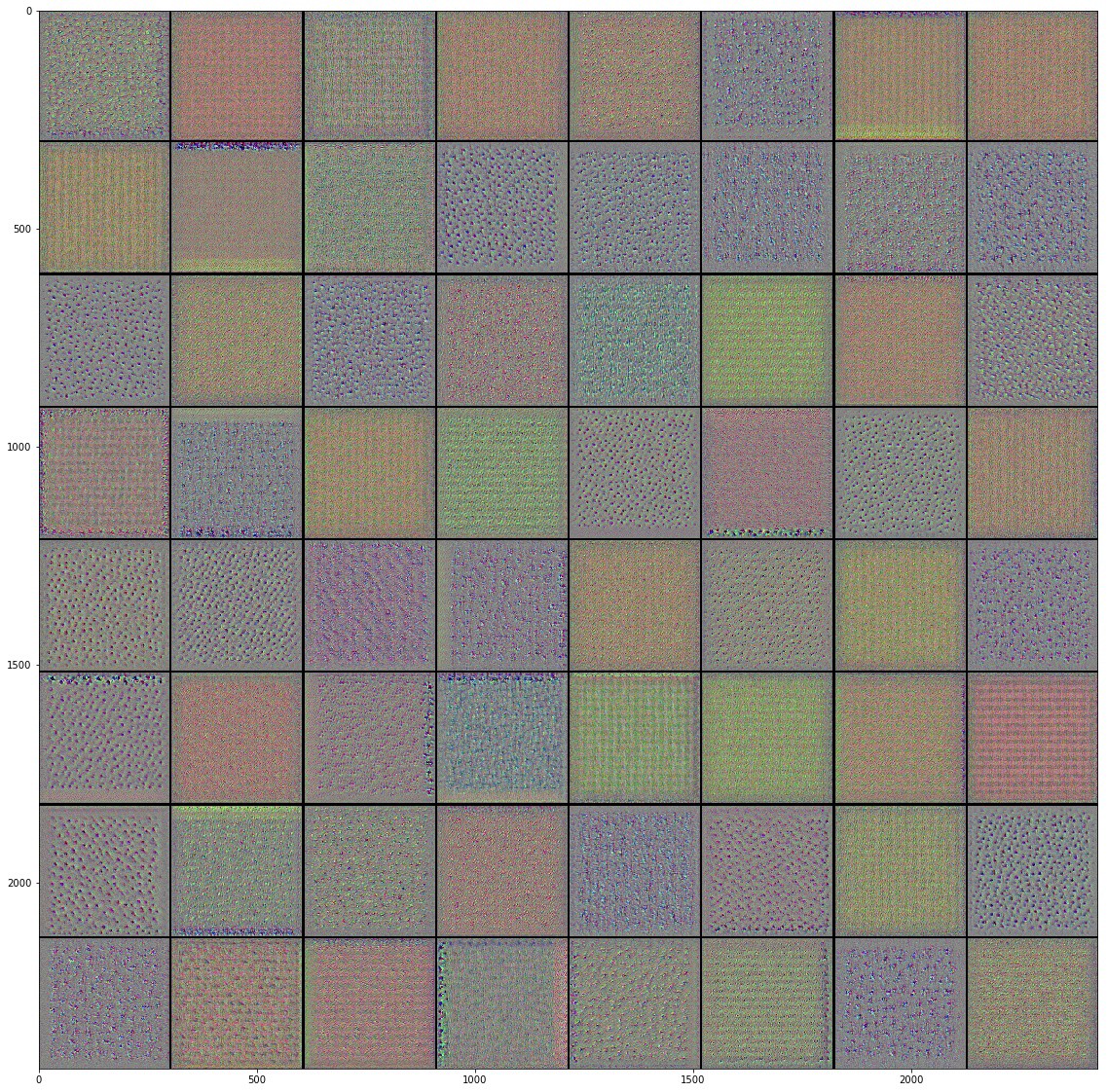

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
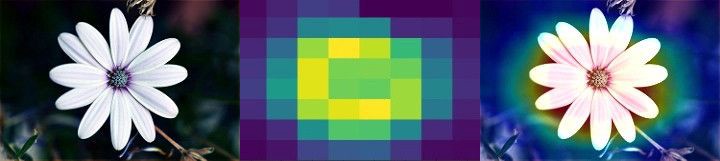

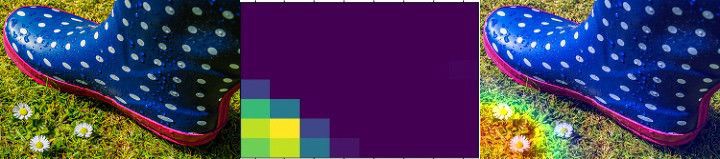
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
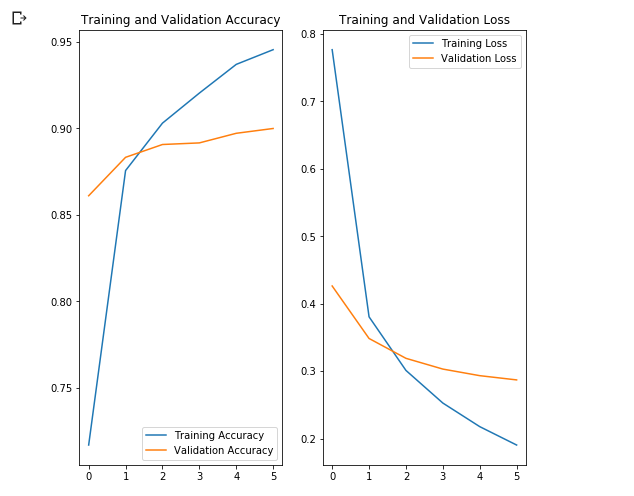
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
总结
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
电报
VKontakte
Ojok .