大家好!
我已经在此博客中谈到了微服务体系结构的模块化监视系统的组织以及从Graphite + Whisper到Graphite + ClickHouse的过渡,以在高负载下存储指标 。 之后,我的同事Sergey Noskov 写了关于我们的监控系统的第一个链接-由我们开发的Bioyino ,这是一个分布式可扩展的指标聚合器。
现在该刷新有关我们如何在Avito中准备监视的信息了-我们的上一篇文章早在2018年,在此期间,监视体系结构,触发器和通知管理,ClickHouse中的各种数据优化以及其他创新都有一些有趣的变化,关于我只想告诉你的。

但是,让我们从顺序开始。
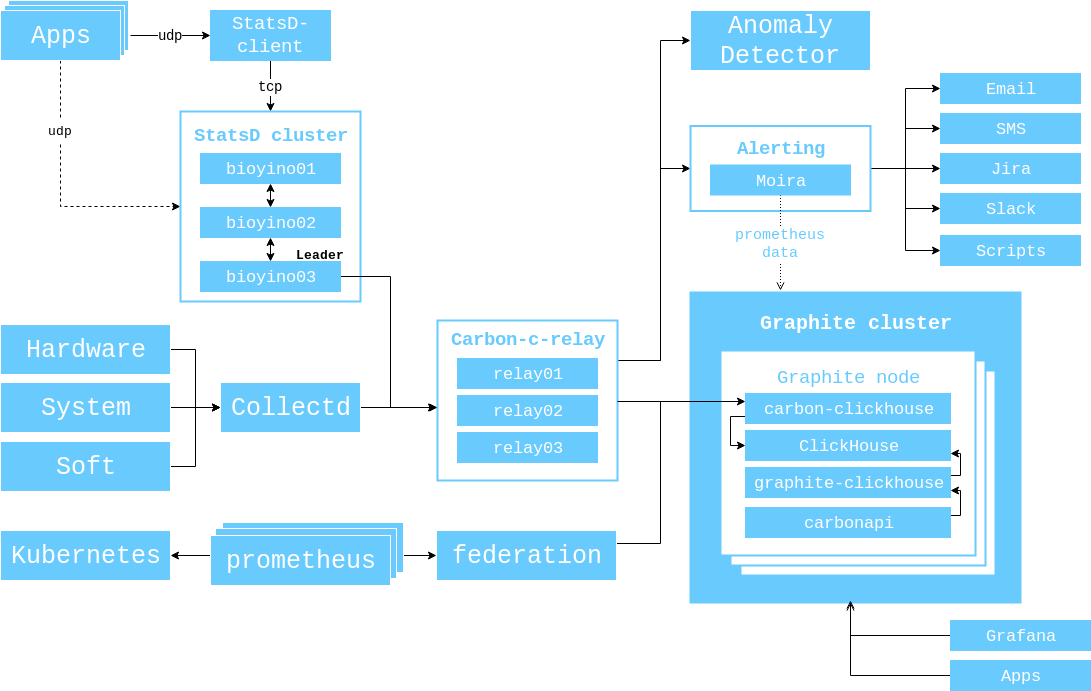
早在2017年,我就展示了当时相关的组件交互图,我想再次进行演示,这样您就不必再次切换选项卡了。

从那一刻起,发生了以下事情。
Graphite群集中的服务器数量已从3增加到6。
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net )。
我们用bioyino代替了brubeck-我们自己的Rust实现StatsD ,甚至撰写了整篇文章 。 但是,在文章发布之后,我们提出了对标记(Graphite)和Raft的支持以选择领导者。
我们确定了使用生物抑制剂作为StatsD代理的可能性,并将此类代理放置在整块实例附近以及k8中需要的位置。
我们终于摆脱了旧的Munin监视系统(以前我们仍然拥有它,但是不再使用其数据)。
由于新版本的Kubernetes不支持Heapster,因此通过Prometheus / Federations组织了来自Kubernetes集群的数据收集。
监控方式
在过去的两年中,接受和处理的指标数量增长了约9倍。
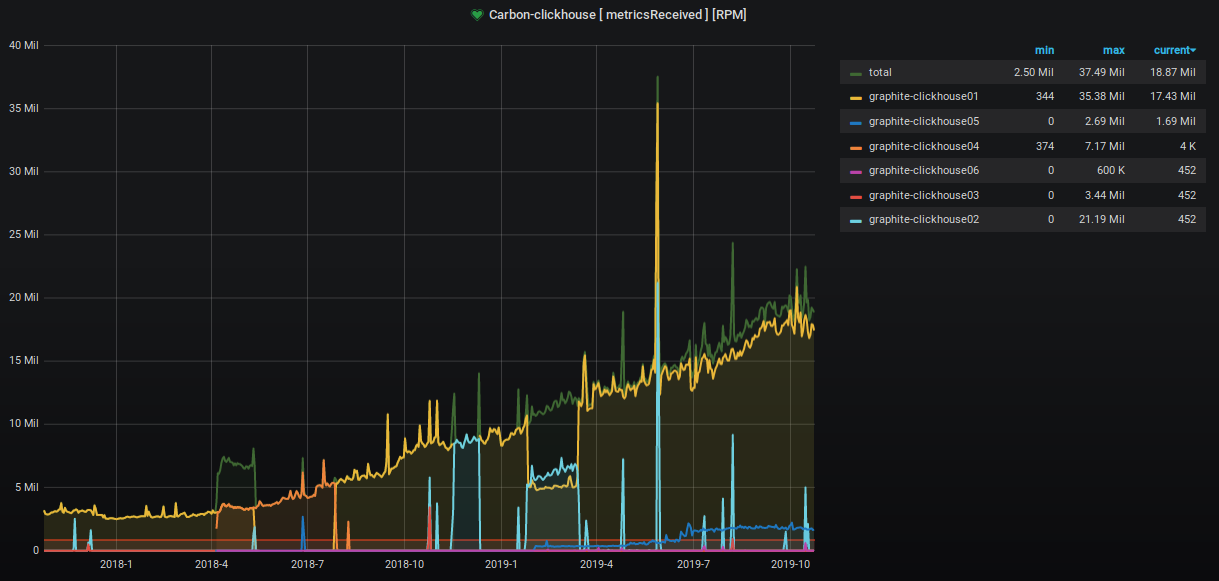
占用的服务器空间百分比也在无情地攀升,我们正在采取各种措施来降低它。 这在图表上清晰可见。
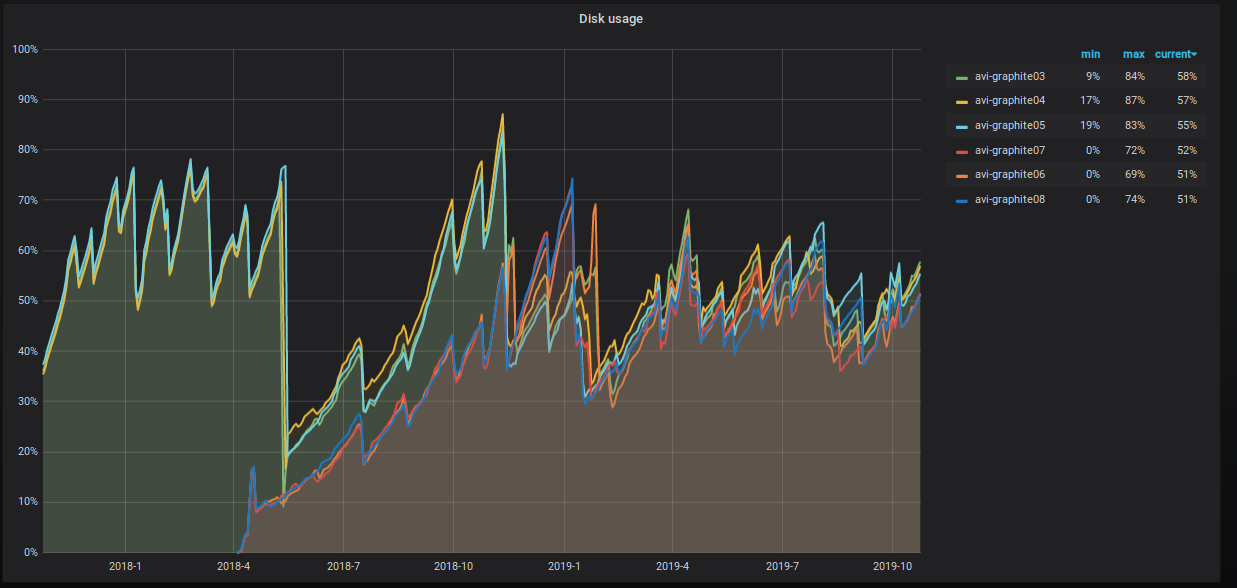
我们到底在做什么?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- 我们共享了数据表。 现在,我们有了三个带有两个副本的碎片,每个副本都有一个代表度量的哈希碎片键。 这种方法为我们提供了执行汇总过程的机会,因为特定指标的所有值都在同一个分片内,并且所有分片上的磁盘空间都被统一用完。
分布式表架构如下。
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
我们还为用户分配了“默认”只读权限,并将对表的写入过程的执行权交给了单独的用户systemXXX 。
ClickHouse中的Graphite群集的配置如下。
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
除了写入负载之外,从Graphite读取数据的请求数量也增加了。 该数据用于:
- 触发处理并生成警报;
- 在越来越多的公司员工的办公室,笔记本电脑和PC屏幕上的显示器上显示图形。
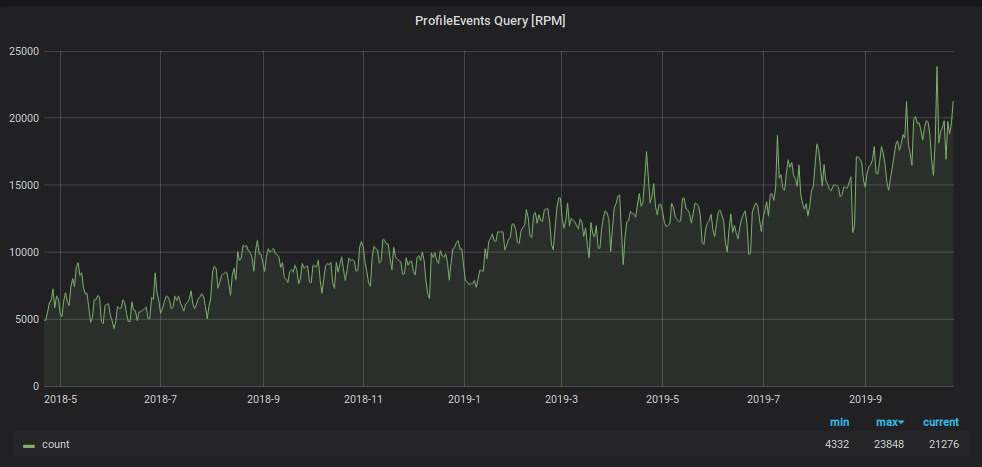
为了防止监视程序在此负载下淹没,我们使用了另一种方法:将最近两天的数据存储在单独的“小”盘中,然后将过去两天的所有读取请求发送到那里,以减少主分片表的负载。 同样对于这种“小型”平板电脑,我们使用了反向度量存储方案,该方案极大地加快了对其中包含的数据的搜索,并为它组织了每日分区。 该板的方案如下。
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
为了向其中定向数据,我们在carbon-clickhouse应用程序配置文件中添加了一个新部分。
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
为了删除超过两天的分区,我们编写了一个cron任务。 看起来像这样。
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
为了从表中读取数据,在graphite-clickhouse配置文件中添加了一个部分:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
结果,我们有了一个表,其中100%的数据已复制到所有六台服务器,这些服务器在不到两天的时间内处理了来自请求的全部读取负载(其中有95%)。 另外,我们还有一个分片表,其中每个分片上的数据为1/3,可读取所有历史数据。 即使这样的请求很小,来自它们的负载也要高得多。
CPU发生了什么? 由于Graphite群集中已记录和读取的数据量增加,服务器上的总CPU负载也增加了。 看起来像这样。
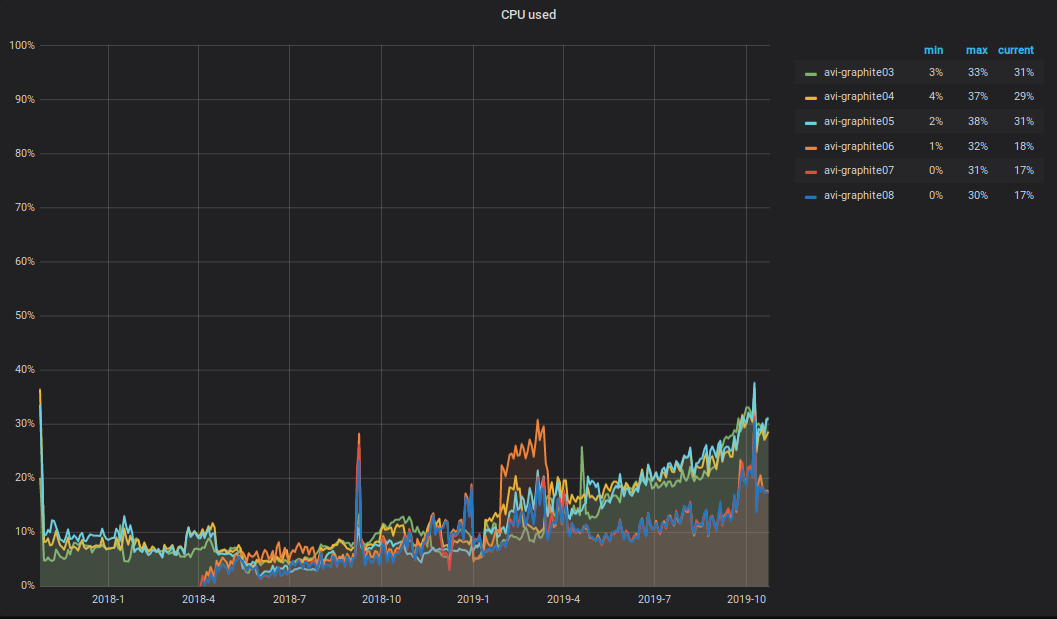
我想提请注意以下细微差别:一半的CPU用于Carbon-c-relay (2018-09-05版本v3.2,负责传输度量标准)中的度量标准的解析和主处理,它位于六台服务器中的三台中。 从图中可以看出,这三个服务器位于TOP中。
警报
作为警报系统,我们仍然有Moira和为其编写的moira-client 。 为了灵活地管理触发器,通知和升级,我们使用了一个称为alert.yaml的声明性描述。 它是通过PaaS创建服务时自动生成的(有关更多信息,请参见Vadim Madison的文章“我们对微服务的了解” ),并将其放置在其存储库中。 为了使用alert.yaml,我们在moira-client上进行了绑定,并将其命名为alert-autoconf(我们计划开放)。 在TeamCity中组装服务有一个步骤,即通过alert-autoconf将触发器和通知导出到Moira。 将更改提交到alert.yaml时,将运行自动测试,以检查yaml文件的有效性,并针对每个度量标准模板向Graphite发出请求,以验证其正确性。
对于不使用PaaS的基础架构团队,我们组织了一个单独的存储库,称为“警报”。 它的格式如下:Team / Project / alert.yaml。 对于每个alert.yaml,我们在TeamCity中生成一个单独的程序集,该程序集运行测试并在Moira中推送alert.yaml的内容。
因此,我们所有的员工都可以使用一种方法来管理触发器,通知和升级。
由于在通过GUI触发触发器之前,我们实现了以yaml格式上传触发器的功能。 可以将接收到的yaml文档的内容插入到alert.yaml中,而无需进行任何其他转换,然后将更改推送到向导中。 在构建期间,alert-autoconf将了解这样的触发器已经存在,并将其注册到我们在Redis中的注册表中。
不久前,我们全天候24x7轮班工作。 为了将触发器转移给他们以进行维修,请在alert.yaml中足够正确地填写“看到后该怎么办”的说明,将标签[24x7]放置到向导中。 滚动alert.yaml后,其中描述的所有触发器将自动置于24x7的24小时轮班监控之下。 U-简化! 美女!
业务指标收集
自上一篇有关收集和处理业务指标的文章以来,我们的bioyino变得更好。
- 而不是通过领事来选择领导者,而是使用内置的Raft 。
- 标签以Graphite格式正确处理。
- 现在您可以将bioyino (StatsD服务器)用作代理。
- 为了计算唯一值,支持“设置”格式。
- 指标的最终汇总可以在多个线程中完成。
- 数据可以通过多个并行连接发送到Graphite块。
- 修复了发现的所有错误。
现在它像这样工作。
我们开始在所有大型度量生成器旁边积极引入StatsD代理:在具有整体实例的容器中,在服务旁边的k8s pod中,在具有基础结构组件的主机上等。
Statsd代理位于应用程序旁边。 它通过UDP使用此应用程序中的度量标准,但不再使用网络子系统(由于Linux内核中的优化)。 所有事件都是预先汇总的,并且每秒收集的数据(可以配置时间间隔)以Cap'n Proto格式发送到StatsD服务器的主要群集(bioyino0 [1-3])。
度量标准的进一步处理和聚合,StatsD群集中领导者的选择以及领导者向Graphite发送度量标准都没有改变。 您可以在上一篇文章中详细了解此内容 。
至于数字,它们如下。
收到的StatsD事件图
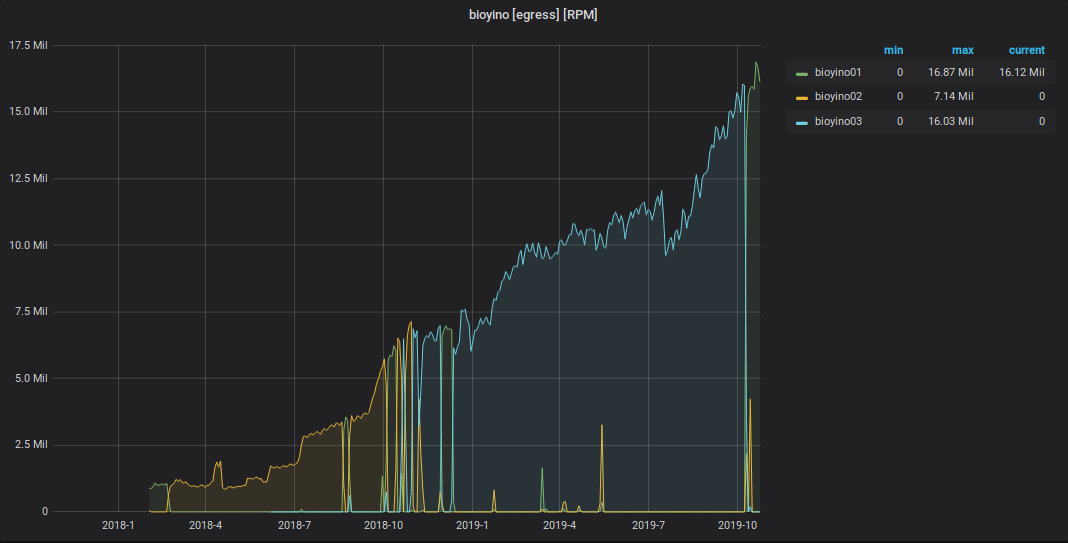

从StatsD发送到Graphite的指标图
合计
目前,监视组件之间交互的一般方案如下所示。
指标总数:2 189 484 898 474。
指标的总存储深度:3年。
唯一度量标准名称的数目:6 585 413 171。
触发器数量:1053,它们的作用范围是1到15,000。
近期计划:
- 开始将产品服务移至标记的度量标准存储方案;
- 向Graphite集群添加三台服务器;
- 用持久的组织结交Moira朋友;
- 在监视团队中查找其他开发人员。
我将很乐意在这里发表评论和提出问题-写。 我还将在11月7日使用Highload ++进行表演 ,如果您在那里,我们可以谈谈。