在
上一篇文章中,我们发现缓存无疑是有用的,但是就控制器逻辑而言,它有时会带来困难。 特别是,它在时序图的程序设计中引入了脉冲持续时间或其他延迟的不可预测性。 好的,在“通用程序化”计划中,该函数的位置不正确会降低从缓存中获得的收益,甚至导致缓存从缓慢的内存重启。 我提到15年前,我们必须制造一种特殊的预处理器来解决SPARC-8处理器出现的问题,并承诺要告诉您在开发推荐用于Redd软件包的合成Nios II处理器时解决这些困难有多么容易。 现在是兑现诺言的时候了。

该系列中的先前文章:
- 为Redd中安装的FPGA开发最简单的“固件”,并以内存测试为例进行调试。
- 为Redd中安装的FPGA开发最简单的“固件”。 第2部分。程序代码。
- 开发自己的内核以嵌入基于FPGA的处理器系统。
- 以访问FPGA为例,为中央处理器Redd开发程序。
- 在Redd Complex的FPGA中CPU和处理器的连接示例中,首先使用流协议进行实验。
- Merry Quartusel或处理器如何成为这样的生活。
- Redd的代码优化方法。 第1部分:缓存效果。
今天,我们的参考书将是《
嵌入式设计手册》 ,或者更确切地说是其
7.5节
。 Nios II处理器教程使用紧密耦合的内存 。 该部分本身是彩色的。 今天,我们在平台设计器程序中为英特尔FPGA设计处理器系统。 在Altera时代,它被称为QSys(因此项目文件的
.qsys扩展名)。 但是在QSsys出现之前,每个人都使用了其祖先SOPC Builder(
保留了
.sopcinfo文件扩展名)。 因此,尽管该文档标有Intel徽标,但其中的图片是此SOPC Builder的屏幕截图。 显然是十多年前写的,从那以后,只对其中的术语进行了更正。 的确,这些文本非常现代,因此该文档作为培训手册非常有用。
设备准备
这样啊 我们希望将内存添加到我们的Spartan处理器系统中,该内存永远不会被缓存,并且同时以最快的速度运行。 当然,这将是内部FPGA存储器。 我们将为代码和数据添加内存,但是这些将是不同的块。 让我们从最简单的数据存储器开始。 我们
将已知的
OnChip内存添加到系统中。
好吧,假设它的容量为2 KB(FPGA内部存储器的主要问题是它很小,因此必须保存)。 其余的是我们已经添加的普通内存。

但是我们不会将其连接到数据总线,而是连接到专用总线。 要使其显示,请进入处理器属性,转到“
高速 缓存和内存接口”选项卡,然后在选择列表
中紧密耦合的数据主端口的数量中选择值1。
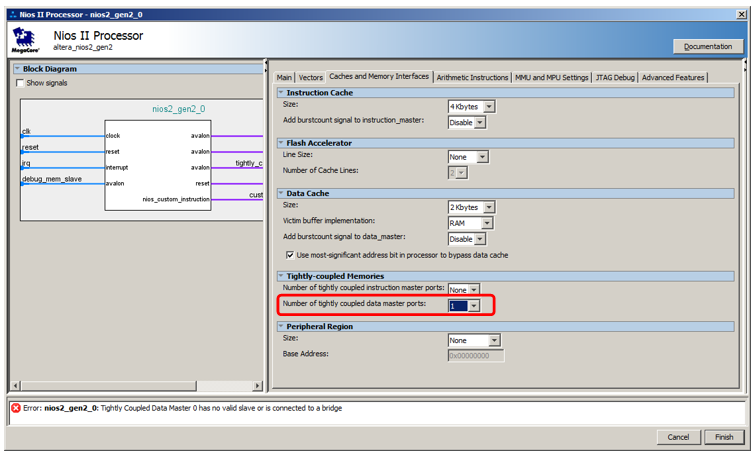
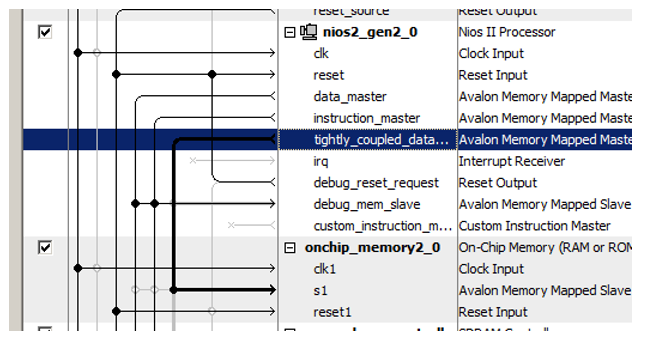
这是处理器的新端口:

我们最近将新添加的内存块连接到它!
另一个技巧是将地址分配给该新内存。 该文件对地址解码的最佳性有很长的推理依据。 它指出,必须通过地址的一个明确表示的位来将非缓存的内存与所有其他类型的内存区分开。 因此,在文档中,所有不可缓存的内存都属于范围0x2XXXXXXX。 因此,请手动输入地址0x2000000并将其锁定,以使其在以下自动分配中不会更改。

好吧,纯粹出于美学考虑,请重命名该块……让我们称其为
NonCachedData 。

有了用于非缓存数据存储器的硬件,就是这样。 我们传递给内存进行代码存储。 此处的一切几乎相同,但更为复杂。 实际上,所有事情都可以完全相同地完成,只是在
紧密耦合的指令主端口数列表中打开了总线主端口,但是,不可能调试这样的系统。 当程序被调试器填充后,它将通过数据总线流到那里。 停止时,调试器还会通过数据总线读取反汇编的代码。 即使程序是从外部加载程序加载的(我们还没有考虑过这种方法,特别是因为在开发版本的免费版本中,我们不得不仅在连接了JTAG调试器的情况下才能工作,但是一般来说,没有人禁止这样做),填充也通过总线进行数据。 因此,内存将不得不做双端口。 将一个在主端口工作的未缓存的指令向导连接到一个端口,将另一个主辅助数据总线连接到另一个端口。 它将用于从外部下载程序,以及由调试器获取RAM的内容。 其余时间该轮胎将处于怠速状态。 这就是文档理论部分的外观:

请注意,该文档没有解释原因,但是要注意,即使具有双端口内存,也只能将一个端口连接到未缓存的主服务器。 第二个应该连接到通常。
让我们添加8 KB的内存,使其成为双端口,默认情况下保留其余部分:
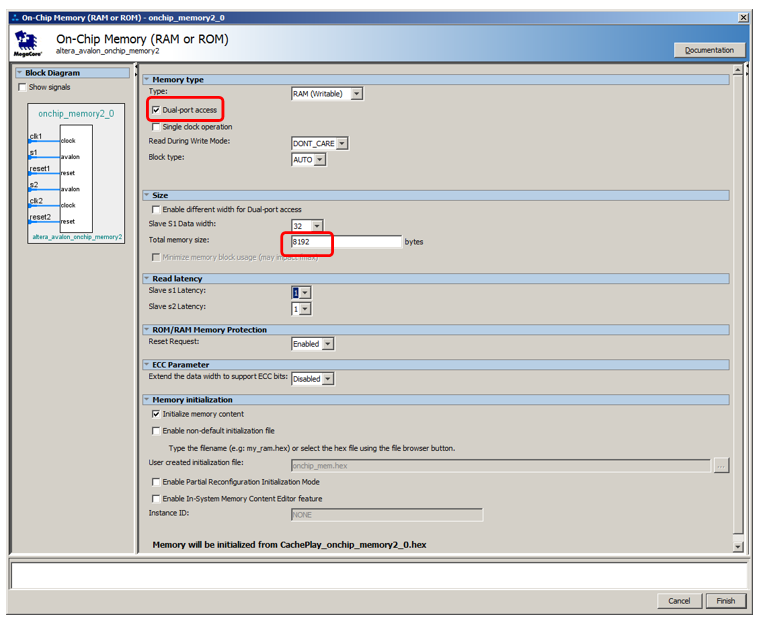
向处理器添加不可缓存的指令端口:

我们将内存
称为NonCachedCode ,将内存连接到总线,为其分配地址0x20010000并将其锁定(对于两个端口)。 总计,我们得到如下信息:
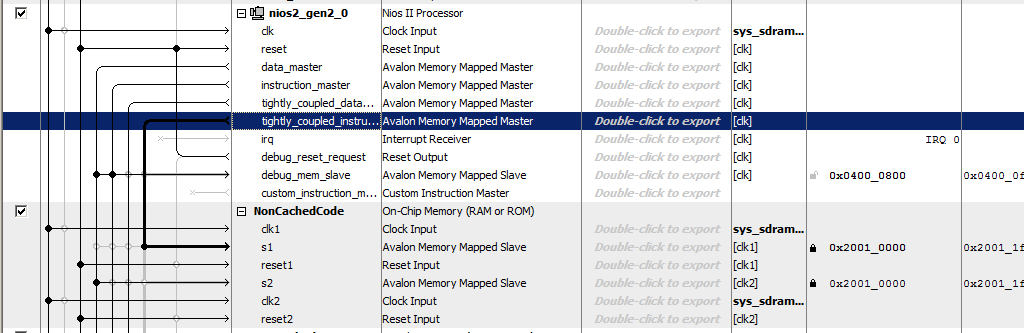
仅此而已。 我们保存并生成系统,收集项目。 硬件已准备就绪。 我们传递到软件部分。
在软件部分准备BSP
通常,在更改处理器系统后,只需选择“
生成BSP”菜单项,但是今天我们必须打开BSP编辑器。 由于我们很少这样做,所以让我提醒您相应菜单项的位置:
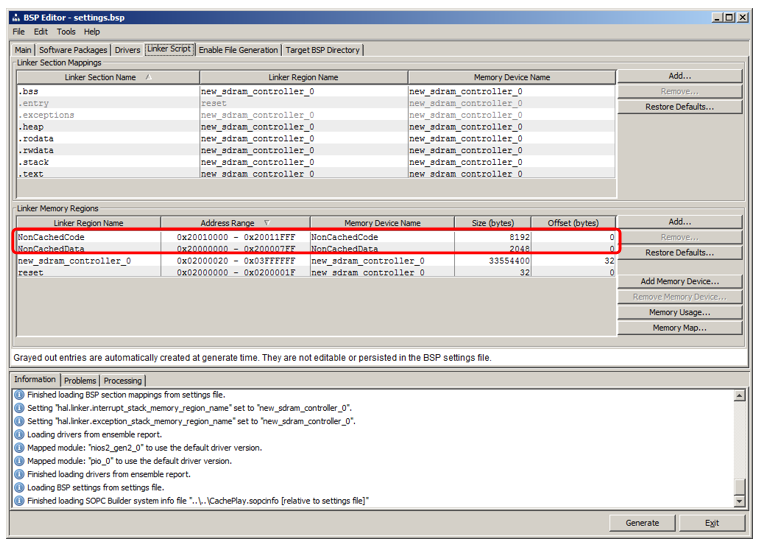
在那里,我们转到
链接器脚本选项卡。 我们看到我们添加了从RAM块继承名称的区域:
我将展示如何添加将放置代码的部分。 在该部分中,单击添加:
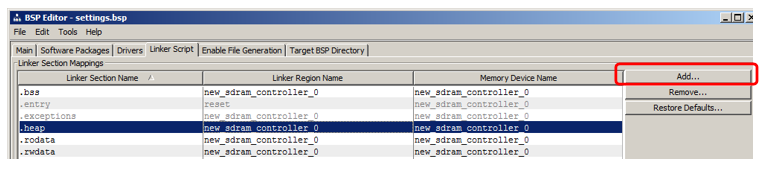
在出现的窗口中,输入部分的名称(为避免在文章中造成混淆,我将其命名为与区域名称(nccode)非常不同),并将其与区域关联(我从列表中选择了
NonCachedCode ):

就这样,生成BSP并关闭编辑器。
将代码放在新的内存部分中
让我提醒您,该程序中有两个函数继承自上一篇文章:
MagicFunction1()和
MagicFunction2() 。 在第一遍中,他们俩都将自己的身体加载到了缓存中,这在示波器上是可见的。 此外,根据环境的不同,他们要么以最快的速度工作,要么不断地与自己的身体摩擦,从而导致从SDRAM不断下载。
让我们将第一个函数移至新的非缓存段,然后将第二个函数保留在原处,然后执行几次运行。
要将函数放在新部分中,请向其添加section属性。
在定义
MagicFunction1()函数之前,
我们还将其声明与此属性一起放置:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
我们执行循环的一次迭代的第一次运行(我在while行上放置了一个断点):
while (1) { MagicFunction1(); MagicFunction2(); }
我们看到以下结果:
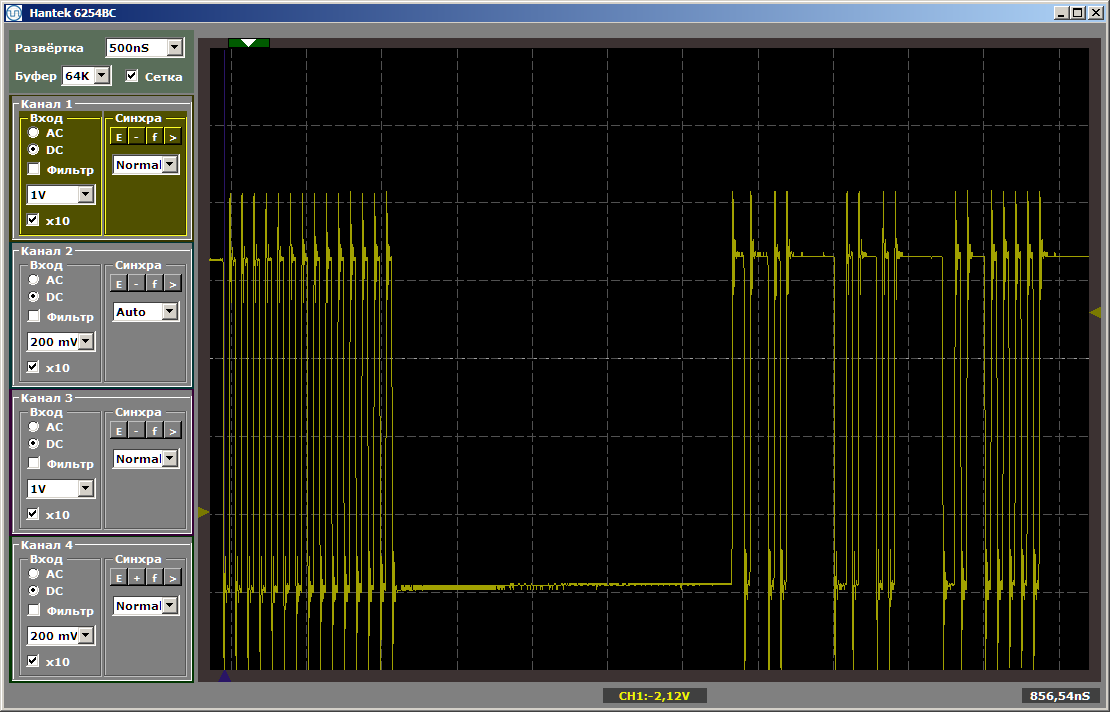
如您所见,第一个函数实际上是以最大速度执行的,第二个函数是从SDRAM加载的。 运行第二次:
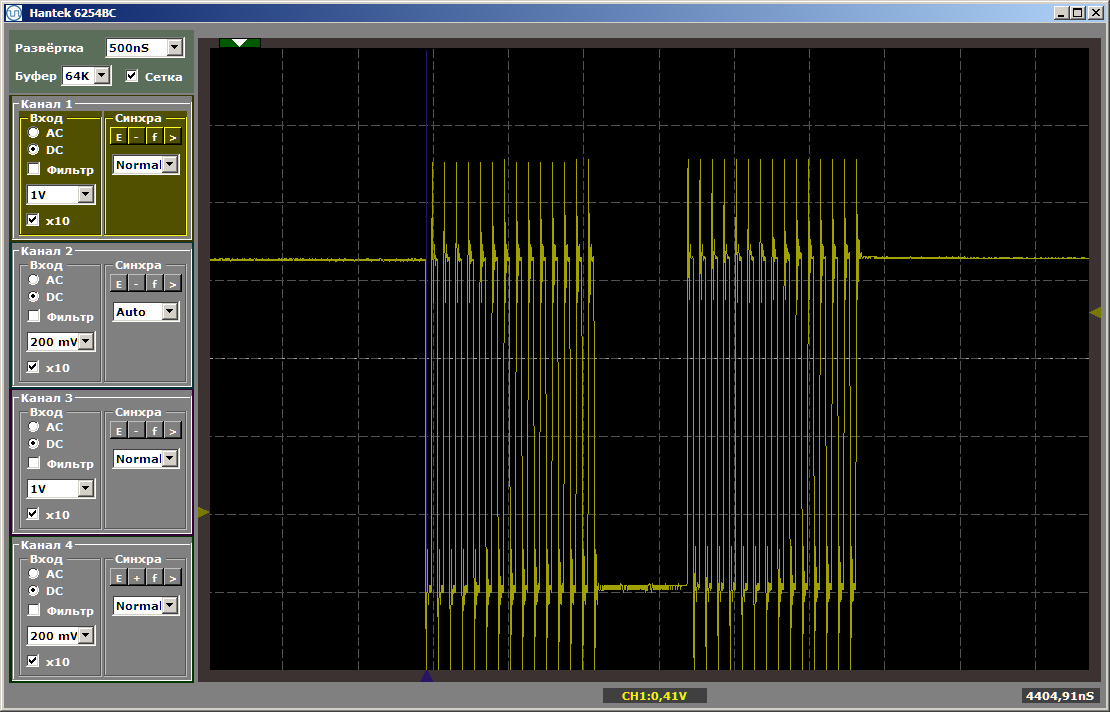
两种功能均以最大速度运行。 而且第一个函数不会从缓存中卸载第二个函数,尽管事实上它们之间是我写了最后一篇文章后剩下的插入内容:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
这种插入不再影响两个函数的相对位置,因为它们中的第一个留在了完全不同的内存区域中。
关于数据的几句话
同样,您可以创建一个非缓存数据部分,并在其中放置全局变量,为它们分配相同的属性,但是为了节省空间,我不会给出此类示例。
我们已经为该内存创建了一个区域,可以通过与代码段相同的方式来映射到该段。 剩下的仅仅是了解如何将相应的属性分配给变量。 这是声明在自动生成的代码的肠中找到的此类数据的第一个示例:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
它给我们带来什么
好吧,实际上,从明显的事情来看:现在我们可以将代码的主要部分放在SDRAM中,在不可缓存的部分中,我们可以将那些以编程方式形成时间图的函数放出来,或者将其性能最大化,这意味着不应由于以下原因而放慢速度:其他函数会不断从缓存中转储相应的代码。
仔细看看轮胎。
现在,仔细研究最终处理器系统中的轮胎。 我们几乎有四个。 我在主巴士上圈了红色(这是两者的并集,这就是为什么我写“几乎”的原因:物理上-有两个轮胎,但从逻辑上讲-一个)。 我以绿色突出显示了通向非缓存指令存储器的总线,以蓝色突出显示了通向非缓存数据存储器的总线。
这三个轮胎平行且彼此独立地工作!
记住,在
有关DMA的
文章中,我认为限制性能的因素之一是数据在同一总线上传输吗? DMA模块从总线读取数据,向总线写入数据,甚至处理器内核同时使用相同的总线。 如您所见,FPGA完全消除了封闭系统的缺点。 在现成的控制器中,制造商在铺设连接时被迫在需求和功能之间撕裂。 程序员可能需要此选项。 这样的。 这样的。 因此,可能需要做很多事情。 但是资源要花钱,并且在选定的晶体上并不总是有足够的空间容纳它们。 您不能发布所有内容。 我们必须选择每个人真正需要的,以及在个别情况下需要的。 以及应该引入哪些孤立的案例,以及应该忘记哪些案例。 然后出现妥协的解决方案,所有这些方案的精妙之处,如果希望使用它们,程序员必须牢记。 就我们而言,我们可以毫不费力地采取行动。 今天奠定了我们今天需要的东西。 我们的资源是灵活的。 我们花了很多钱,使设备最适合今天的任务。 对于明天和昨天的任务,不需要保留资源。 但是在今天的情况下,我们将以一种使程序尽可能高效运行的方式放置所有内容,而无需特殊的编程乐趣。
曾几何时,在一所大学的信号处理器课程中,我们学会了与两个团队并行使用两条总线的技术。 据我所知,在现代ARM控制器中,对总线矩阵的详细了解也可以实现优化。 但是,当开发人员使用同一系统多年后,所有这些都很好。 如果您必须在项目之间使用完全不同的硬件,那么您将无法记住所有内容。 对于FPGA,我们不研究环境的特征,我们可以自由地为自己定制环境。
关于“我们不花很多时间在开发上”的方法,听起来像这样:
我们不需要努力优化现成的标准轮胎的使用,我们可以以最优化的方式快速放置它们以完成要解决的任务,迅速完成此辅助开发并迅速确保对主要项目进行调试或测试的过程。
让我们看一个示例,该示例包含《
嵌入式外围设备IP用户指南》中的DMA模块,以合并材料。
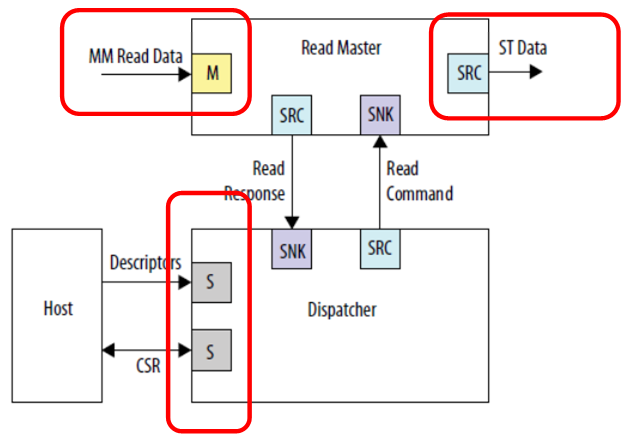
我们看到三个独立的连接。 输入数据(在此图中,这是一条投影到内存上的总线),输出数据(在此图中,这是一种完全不同的总线-流接口)以及与控制处理器的通信。 没有人愿意将它们全部连接到不同的总线,那么工作将并行进行。 输入数据(例如,来自SDRAM的数据)将进入一个流,没有人会干扰; 输出将以不同的流进入例如我们已经考虑过的FT245-FIFO通道; 由于主总线是隔离的,因此中央处理器不会吃掉这些时钟总线。 尽管在这种情况下,当然,SDRAM中位于单独总线上的内存在编程上将不可用。 但是没有人会阻止它被DMA读取。 如果目标是使用缓冲区实现高性能,则必须不惜一切代价实现它。 除非整个程序都必须适合FPGA内置的存储器,否则Redd硬件中没有其他存储单元。
要使轮胎平行化,还可以使用非缓存轮胎,因为我们看到可以有多个。 连接到这些总线的从站受到许多限制:
- 奴隶永远是公车上的奴隶;
- 从机不使用总线延迟机制;
- 写入延迟始终为零;读取延迟始终为1。
如果满足这些条件,则可以将此类从设备连接到未缓存的总线。 当然,很可能它将是数据总线。
通常,了解这些基本原理后,您当然可以在实际任务中使用它们。 但是,总的来说,您可以。 如果通过常规方法获得结果,则可以不这样做。 但是请记住这一点。 有时,通过这些机制优化系统比对程序进行微调更为简单。
结论
我们研究了一种用于传输对性能或不可缓存内存中的处理执行的可预测性至关重要的代码段的技术。 在此过程中,我们研究了通过使用多个相互平行且独立运行的轮胎来优化性能的可能性。
为了完成本主题,我们仍然必须学习如何提高系统时钟频率(现在仅限于为SDRAM芯片生成时钟脉冲的组件)。 但是,由于这些文章遵循“一件事-一条文章”的原则,因此我们下次会再做。