大家好! 在这篇文章中,我将告诉您我们在Mail.ru搜索中使用哪种方法比较文本。 这是为了什么 一旦我们学习了如何将不同文本很好地进行比较,搜索引擎将能够更好地理解用户的请求。
为此我们需要什么? 首先,严格设置任务。 您需要自己确定我们认为相似的文本和不考虑的文本,然后制定自动确定相似性的策略。 在我们的案例中,将用户查询的文本与文档的文本进行比较。
确定文本相关性的任务包括三个阶段。 首先,最简单:在两个文本中查找匹配的单词,然后根据结果得出关于相似性的结论。 下一个更困难的任务是搜索不同单词之间的联系,理解同义词。 最后,第三阶段:分析整个句子/文本,隔离含义,并根据含义比较句子/文本。

解决此问题的一种方法是找到一些从文本空间到更简单映射的映射。 例如,您可以将文本翻译到向量空间并比较向量。
让我们回到开始并考虑最简单的方法:在查询和文档中查找匹配的单词。 这样的任务本身已经非常复杂:要做到这一点,我们需要学习如何获得正常形式的单词,而单词本身并不是平凡的。
直接映射模型可以大大改善。 一种解决方案是匹配条件同义词。 例如,您可以输入关于文本中单词分布的概率假设。 您可以使用向量表示法并隐式隔离不匹配单词之间的连接,然后自动进行。
由于我们从事搜索,因此在收到某些文档以响应某些查询时,我们拥有大量有关用户行为的数据。 基于这些数据,我们可以得出关于不同单词之间关系的结论。
我们来看两句话:

从查询和标题中分配每对单词一定的权重,这将意味着第一个单词与第二个单词有多少关联。 我们将点击次数预测为这些权重之和的S形变换。 也就是说,我们设置了逻辑回归的任务,其中属性由一组成对的形式(查询中的单词,文档标题/文本中的单词)表示。 如果我们可以训练这样的模型,那么我们将了解哪些词更同义词,更准确,可以连接以及哪些词最不可能。
现在您需要创建一个良好的数据集。 事实证明,记录用户的点击历史记录,添加否定示例就足够了。 如何在负面例子中混用? 最好以1:1的比例将它们添加到数据集中。 此外,在训练的第一阶段,示例本身可以随机完成:对于查询文档对,我们找到了另一个随机文档,我们认为这样的对是负数。 在训练的后期阶段,给出更复杂的示例(具有交叉点的示例以及模型认为相似的随机示例(硬性负挖掘))是有利的。
示例:“三角形”一词的同义词。
在这个阶段,我们已经可以区分一个匹配单词的好的函数,但这并不是我们所追求的,该函数允许我们进行间接单词匹配,并且我们想比较整个句子。
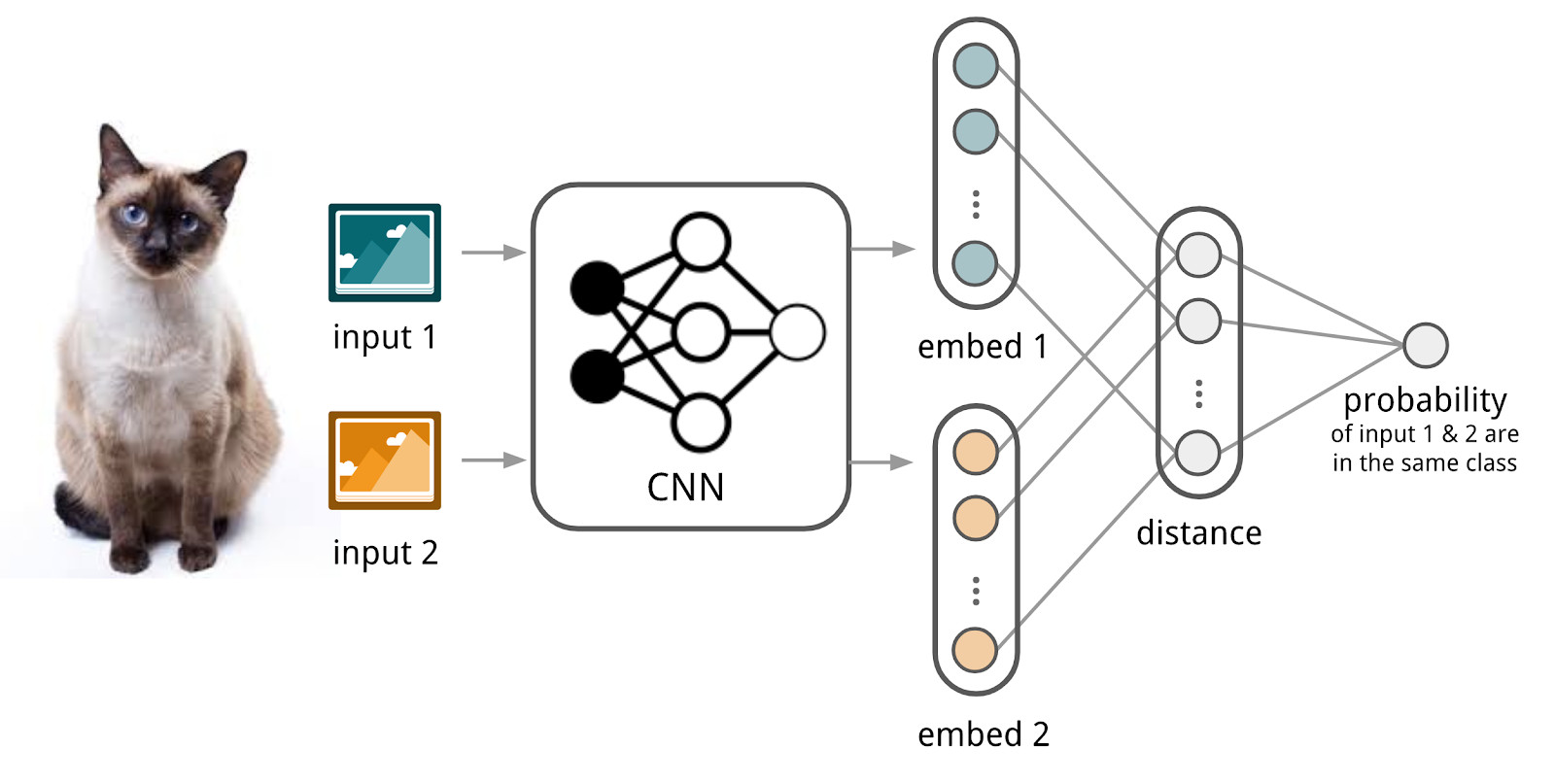
在这里,神经网络将为我们提供帮助。 让我们创建一个接受文本(请求或文档)并生成矢量表示的编码器,以使相似的文本具有接近的矢量和远离的矢量。 例如,您可以使用余弦距离作为相似度的度量。
在这里,我们将使用连体网络的设备,因为它们更容易训练。 暹罗网络由一个编码器和一个比较操作(例如,余弦距离)组成,该编码器应用于两个或多个族的样本数据。 当将编码器应用于不同系列的元件时,将使用相同的权重。 这本身可以提供良好的正则化,并大大减少了训练所需的因素数量。
编码器从文本中产生矢量表示并进行学习,以使相似文本的表示之间的余弦最大,而异文本的表示之间的余弦最小。
深度语义复杂性DSSM网络适合我们的任务。 我们使用它进行一些细微的更改,下面将对此进行讨论。
经典DSSM的工作方式:查询和文档以袋的形式出现,从中获得标准矢量表示。 它经过几个完全连接的层,并以某种方式训练网络,以便根据要求最大化文档的条件概率,这等效于最大化通过网络的完全通过而获得的矢量表示之间的余弦距离。
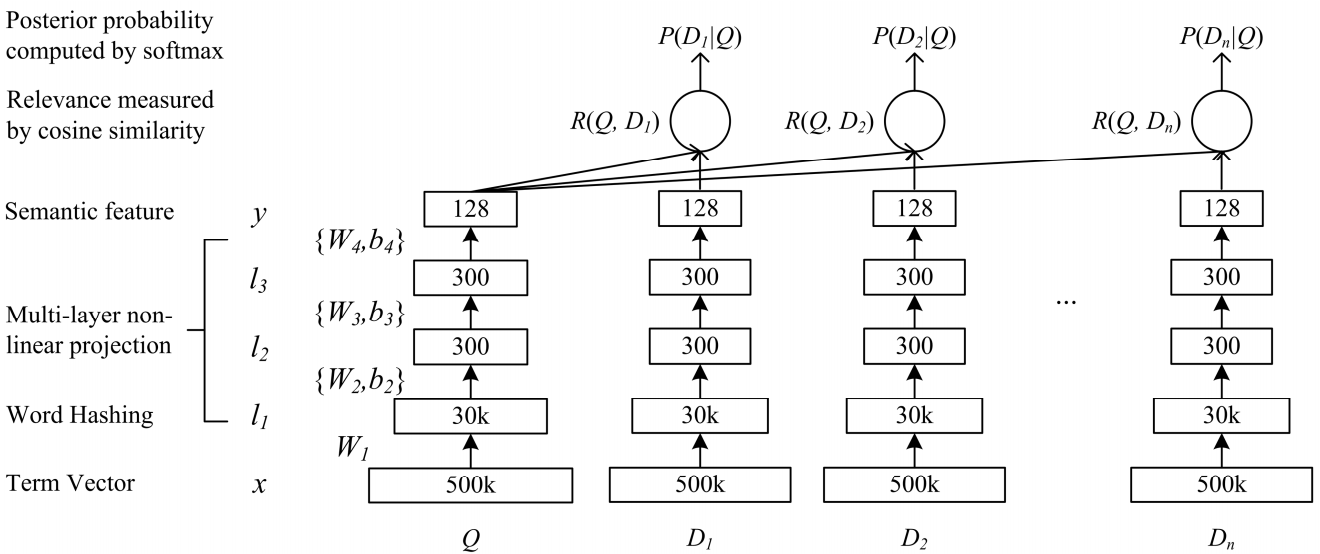 宝森黄晓东何建峰高力登亚历克斯·阿塞罗·拉里·赫克。 2013年使用点击数据学习用于Web搜索的深度结构化语义模型
宝森黄晓东何建峰高力登亚历克斯·阿塞罗·拉里·赫克。 2013年使用点击数据学习用于Web搜索的深度结构化语义模型我们几乎以相同的方式进行。 即,查询中的每个单词都表示为三字组的向量,而文本则表示为单词的向量,因此保留了有关哪个单词站立的信息。 接下来,我们在单词内部使用一维卷积,使它们的表示变得平滑,并使用全局最大值拉动的操作以简单的矢量表示形式聚合有关句子的信息。

从本质上讲,我们用于训练的数据集与用于线性模型的数据集完全吻合。
我们并没有就此停止。 首先,他们提出了一种预训练模式。 我们获取该文档的查询列表,输入哪些用户与此文档进行交互,并训练神经网络将此类对紧密地嵌入。 由于这些对来自同一家庭,因此这样的网络更易于学习。 另外,当我们比较请求和文档时,可以更轻松地在战斗示例中对其进行重新训练。
示例:用户转到e.mail.ru/login并提出以下请求:电子邮件,电子邮件输入,电子邮件地址,...最后,我们仍在努力并已取得成功的最后一个困难部分是将请求与一些长文档进行比较的任务。 为什么这个任务比较困难? 在这里,暹罗网络的机制已经不适合使用,因为请求和长文档属于不同的对象族。 尽管如此,我们几乎负担不起改变架构的负担。 只需要按单词添加卷积,这将为文本的最终矢量表示保存有关每个单词上下文的更多信息。
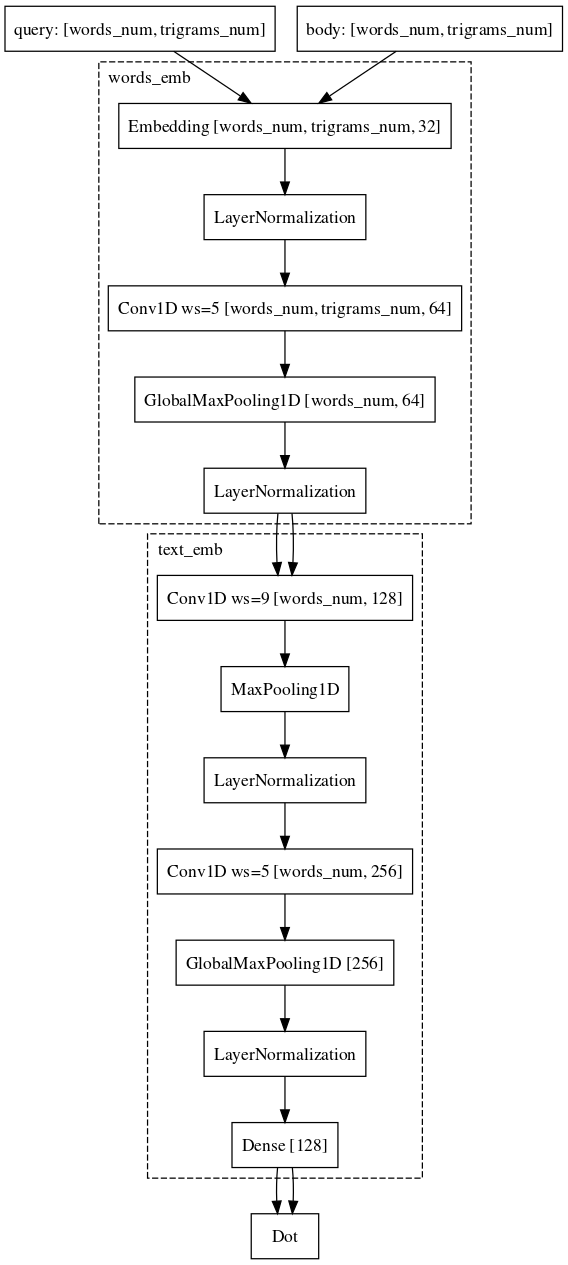
目前,我们通过修改架构并尝试数据源和采样机制来继续提高模型的质量。