目录内容
有时,错误本身会找到我们。 因此,我们推送了大量数据-系统挂起。 是因为掉落了100万个字符吗? 还是她不喜欢某个人?
或文件已上传到系统,然后崩溃了。 怎么了 是由于名称,扩展名,内部数据还是大小? 您可以将本地化推送到开发人员,让他考虑文件中有什么不好的地方。 但是通常您可以自己找到原因,然后更准确地描述问题。
如果找到要播放的最少数据,则:
- 您将为开发人员节省时间-他将不必连接到测试台,自己加载文件并首次亮相
- 管理者将能够轻松地评估任务的优先级-是紧急需要修复的问题,还是可以等待错误? 虽然名称“某些文件掉了,xs为什么”却很难做到...
- 通过了解跌倒原因来描述错误也将有所帮助。
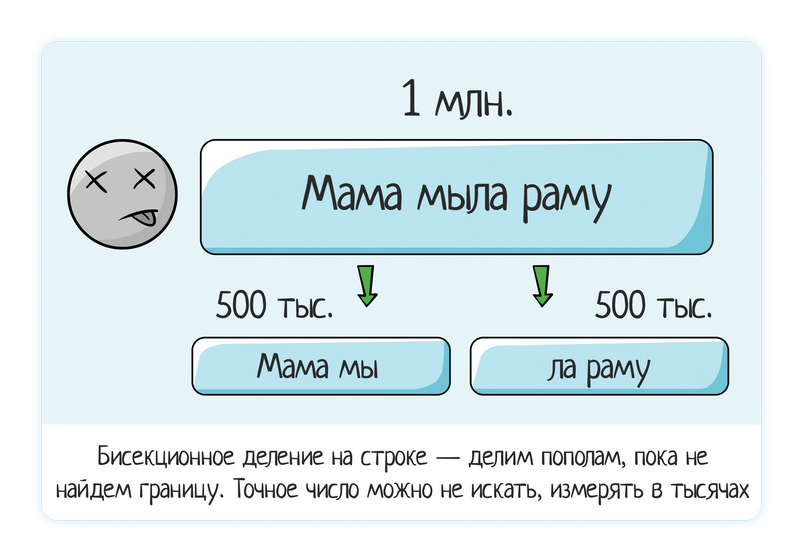
如何找到播放错误的最低数据? 如果日志中有任何提示,请应用它们。 如果没有任何线索,那么最好的方法是二等分法(也称为“二等分”或“二分法”)。
方法说明
该方法用于查找跌倒的确切位置:
- 拿一个下降的数据包。
- 分成两半。
- 检查一半1
- 如果跌落了,那么问题就在那里。 我们将与她进一步合作。
- 如果它没有掉落→检查一半2。
- 重复步骤1-3,直到剩下一个下降值。

该方法使您可以快速定位问题,尤其是通过编程方式解决时。 开发人员将此类机制集成到数据处理中。 如果他们没有内置它,那么测试人员来到他们面前说:“它落在这个文件上了,但是我找不到确切的原因。”
测试人员的申请
资料列
加载了一百万条数据线-系统冻结。
我们尝试50万(分为两半)-它仍然挂起。
我们尝试25万-它不会挂起,一切正常。
↓
因此,得出的结论是问题在250到50万之间。
我们尝试35万(“按眼”划分-完全可以,您在手动玩游戏时不必碰到准确的数字)-一切正常
我们尝试了45万-这很糟糕。
我们尝试40万-这很糟糕。
↓
通常,您已经可以得到一个错误。 测试人员很少需要报告边界或错误明显在286586中。将其本地化大约为29万就足够了。
选中“ 10”然后立即选中“ 300,000”只是一回事,而提供更完整的信息则完全不同:“多达一万个都可以,从10到28万个制动器启动,现在已经降至29万个”。
显然,当以数千为单位测量数量时,手动搜索特定的面孔将花费很长时间。 是的,开发人员不需要此。 好吧,没有人愿意白白浪费时间。
当然,如果最初的问题是在长度为10到30个字符的行上,则可以找到确切的边框。 一切与时间都具有合理的关系-如果使用猜测或二等分法,您可以快速找到确切的值,并且该值很小(通常最多为100)-我们正在寻找确定的值。 如果问题很大,则查找1000以上→。
档案文件
上传的文件-崩溃了! 怎么,为什么呢? 首先,我们尝试自己分析哪些因素会影响我们测试的内容? 这是“首先是积极的,然后是消极的”的主要规则。 如果您不尝试一次将所有内容填充到一个测试中:
- 检查了一个小样本文件
- 我们检查了一个巨大的2GB文件,其中包含一列,一列和内部数据的不同变体
在这里很难本地化。 如果分开检查:
- 很多行(但是数据是肯定的,并且已经过验证)
- 多列
- 重物
- ...
那已经可以理解了,这是什么原因。 例如,它落在大量的行上-从10万起。 好的,我们正在寻找使用二等分法的更精确边界:
- 我们将文件分成两份,每份5万,先检查一下。
- 如果跌倒,将其分开
- 因此,直到我们找到特定的下落地点
如果下降取决于行数,我们会寻找一个近似的边界:“下降5000点后,就没有40万了。” 无需搜索特定的地方(4589)。 时间太长,不值得花时间。
这个错误是由达达特的学生发现的。 可以将数据文件加载到此处,系统将处理这些数据并使之标准化:正确的错字,确定目录中缺少的信息(KLADR代码,FIAS,地理坐标,市区,邮政编码...)。
这个女孩试图下载一个大文件并得到了结果:系统在100%的负载下显示进度条,并挂了30分钟以上。
本地化进一步发展-冻结何时开始? 这很重要,因为它会影响任务的优先级。 典型的下载大小是多少? 用户多久发送一次直接LOTS?
也许系统被设计为处理数千行,然后这样的错误塞满了“有一天修复它”。 还是典型的下载-正常处理的1万到5万行,这意味着该错误并未燃烧,我们稍后会修复它。
任务本地化:
- 对于具有5万行,15秒挂起的文件,
- 对于具有10万行,30秒挂起的文件,
- 对于15万行的文件,挂起1分钟,
- 16.5万行的文件挂4分钟,
- 对于文件17.2万行,进度条100%冻结了超过半小时
这是测试人员已经定性完成工作的地方。 提供了有关系统操作的完整信息,在此基础上,管理人员已经可以得出结论,紧急修复漏洞的必要性。
验证也不会花费太多时间。 您可以从头开始,也可以从头开始-在这里我们下载了20万行,问题何时开始? 我们使用二等分法!
或以相对较小的数字开始-5万,然后逐渐增加(按二等分法的一半,相反)。 知道20万一切都会不好,所以我们知道测试不会很多。 我们检查了50、100、150-为进行三个测试,我们找到了近似边界。 然后不再需要挖掘。
但是请记住,您还需要检验您的理论。 问题确实在于行数,而不是文件中的数据吗? 检查这一点非常容易-用一个“正”值创建一个5000行文件。 该值正好在您之前已经检查过了。 如果没有跌落,那么问题就不干净了=))看来行数的理论是错误的,而问题在于数据本身。
尽管您可以尝试一万行正值。 跌倒可能会再次发生。 只是您的源文件在几列上。 还是里面的字符占用了比正值更多的字节...通常,不要立即拒绝文件大小或行数的理论。 相反,尝试二等分-将文件加倍。
但是无论如何,请记住,将多个检查混合在一起,则本地化该错误就越困难。 因此,最好立即测试一个正值上的行数或列数。 这样可以确保您正在测试的是数据量,而不是数据本身。 测试分析及所有=)
但是,如果问题不是行数而是数据本身,该怎么办? 而且您不知道确切在哪里。 也许您将“战争与和平”中的数据塞到了测试文件中,或者从Internet上的某个地方下载了一个大型电子表格……或者用户发现了一个问题-他上传了文件,但一切都掉了下来。 他来支持,支持来到了您:该文件在您身上,播放它。
进一步的行动取决于情况。 如果用户的最后期限到期了,或者从他的帐户中扣了钱,然后文件处理下降了,那么这是一个阻止程序错误。 而且没有时间培训本地化测试人员。 将精确下降的文件提供给开发人员比较容易,让他有空并自己找到原因。
但是,如果您自己发现了一个错误,那就是时候自己去挖掘它了。 再一次,不要忘记本地化的常识。 首先,我们试图自己得出结论,然后寻求帮助。 要自己做出结论,您需要:
- 查看日志,可能有正确答案;
- 查看文件的内容:某些东西可能会引起您的注意,这是第一个理论;
- 使用二等分法。
因此,您放了一个经过深思熟虑和本地化的错误,而不是“ Falls文件,为什么xs,这里有2GB的文件附件”错误:“如果DD / MM / YYYYY格式的日期在内部,文件就会掉落”。 然后,您就不需要2GB的文件了,一行和一列只需要一个文件!

开发人员申请
对于大量数据,测试人员不会寻找明确的边界,因为手动进行此操作是不合理的。 但是开发人员在代码中使用了二等分的方法,并且总是可以找到一个特定的地方。 毕竟,系统将划分成胜利,而不是一个人!
例如,我们有一种将数据加载到系统中的机制。 它可以加载一万和一百万。 但这无关紧要,因为下载是分200个条目进行的。 如果出了问题,系统本身将进行两部分划分。 本身。 直到找到问题的地方。 然后阅读日志:
- 有1000个条目
- 处理了200条记录
- 处理了400条记录
- 糟糕,跌破了200条记录!
- 我尝试处理大小为100的包装
- 我尝试处理一包大小为50的包装
- 我尝试处理25号装
...
- 此类标识符有误:未填写必填的电子邮件字段
- 处理了600条记录
...
当然,这里的进一步逻辑也取决于开发人员。 遇到错误后,处理将停止,或者进一步处理。 偶然发现一包200个条目吗? 我们发现瓶颈,将条目标记为错误,处理了剩余的199,然后继续前进。
但是,如果整个包装都破裂了怎么办? 我们将记录标记为错误,但其余199个也无法处理。 怎么了 我们采用相同的方法来寻找新问题。 诀窍是您始终需要能够准时停止。
如果错误数量超过10-50-100,则最好停止下载。 原始系统中可能发生上传错误,我们收到了100万个“曲线”数据。 如果系统将每包200条记录分成两半,然后将剩余的199分,依此类推,那么对每个人都不利:
- 日志从通常的15 mb增长到3 gb,变得无法读取;
- 尝试生成最终错误消息时,系统可能会崩溃(我在BMW助记符部分中谈到了这种情况);
- 搜索所有错误花费了大量时间。 是的,该系统的执行速度比一个人快,但是如果您将200万条记录中的一百万包分开,那将需要时间。
因此,无论在手动测试还是在编写程序代码时,大脑都必须无处不在。 您必须始终了解何时停止。 只有在进行手动测试的情况下,才“即将找到边界”,而在开发中“如果跌倒了就停止”。
总结
二等分的方法用于搜索跌落的确切位置和错误的定位。
寻找数字,然后将其分成两半:
- 线长
- 档案大小
- 锉重量;
- 行/列数;
- 手机中的可用内存量;
- ...
但是请记住-有一天您必须停止! 如果需要数以千计的其他测试,则无需停下来寻找确切的数字。 但是可以给本地化5-10分钟。
PS- 在我的博客上通过“有用”标签查找更有用的文章