我将尝试告诉您,只需将机器学习课程的教程中完全标准的方法应用于深度学习中未使用的数据,即可轻松获得有趣的结果。 我的帖子的实质是它可以是我们每个人的全部,您只需要查看您熟知的一系列信息即可。 为此,实际上,简单地理解您的数据比成为神经网络的最新结构专家要重要得多。 我认为这就是DL开发的黄金点,一方面,它已经是一种无需博士就可以使用的工具,另一方面,如果您看,仍然有很多领域没有人真正使用过它。比传统主题略远。

阅读文章并通过观察机器学习的发展方式,您和我都可以轻松地感受到这趟火车正在过去的感觉。 的确,如果您从同一个优秀的开放数据科学社区学习最著名的课程(例如Andrew Ng )或有关Habré的大多数文章,您会很快意识到,从高等数学的学院知识的记忆的深度来看,这里没有什么可做的,至少,有些只有经过几周研究特里理论及其不同实施方式,才能取得理智的结果(即使在“ 玩具 ”示例中也是如此)。 但是通常您想要另一个,您想要拥有一个执行其功能的工具,该工具可以解决特定类别的问题,以便将其应用于您的领域即可获得结果。 的确,在其他领域,一切都是如此,例如,如果您编写一个游戏并且您的任务是确保信息从玩家到服务器的传输,那么您就无需研究图论,也无需弄清楚如何优化连接性以使数据包更快到达-您可以使用该工具(库,框架)为您执行此操作,并专注于特定任务的独特功能(例如,您需要来回传递什么样的信息)。 为什么对于深度学习却不是这样?
实际上,现在我们正处在这样的时代 。 对于我自己,我几乎找到了这个工具-fast.ai。 一个优秀的图书馆和更陡峭的课程,其全部原理都是“自上而下”构建的:首先要解决实际问题,通常是在对最新模型进行预测的准确度上,直到图书馆的内部结构及其背后的理论。
当然,一切并不是那么简单。期待指责非专业主义和我知识的肤浅(当然,多半是事实),我想立即提出保留。 是否有必要学习该理论,观看那些非常基础的讲座,记住矩阵演算等? 当然是 而且,您越深入该主题,您就越需要该主题,并且必须坚持使用主要资源。 但是,沉浸式意识越强,就越容易准确地理解这些基本原理如何影响结果。 自上而下的原则的全部要点就是必须在此之后进行。 在写了一些有形的东西之后,就可以向朋友展示。 在您投入足够的话题之后,它就使您着迷了。 知识的理论将超越您,它只是在您将它与您已经完成的工作关联起来的那一刻而已。 解释其为什么以及如何真正起作用。
我绝对确信有人会更习惯于传统的自下而上的方法。 两种方式都很好,主要是我们在中间相遇
有了这样的知识,我决定将DL应用于一个我自己一直很感兴趣的主题,并查看它会导致什么。 当然,我首先想到的是足球。 当我在kaggle上发现了这个很棒的转移统计数据时,选择就变得更加显而易见。
有关此数据的一些信息。 它们包含有关过去10年中谁和在何处迁移到欧洲足球的信息。 这里有有关俱乐部,球员统计数据,他们参加的联赛,教练和经纪人等的信息(还有一百多个不同的领域)。 数据非常有趣,但是是否可以确定玩家应该从中花费多少呢?
如果您考虑一下,那么播放器的价格取决于许多因素。 同时,这很棒, 而且我(如果不是最多的话)是不可形式化的。 如何理解俱乐部刚刚以高价出售了球员,需要一个进攻者并且准备为此多付钱; 如何理解新教练的到来并需要更新名册; 如何理解俱乐部的主要后卫注意到了盛大而他开始半心半意地要求转会? 所有这些从根本上影响交易额,但未在数据中显示。 因此,我对这种预测的准确性的最初期望很小。
我是假程序员此时,是时候插入标准的免责声明了: #不是# ,我不能以此赚钱,所以我的代码很糟糕,很可能可以(而且应该?)重写得更好,但是由于任务是调查这个想法,(不是?)确认理论,然后代码便是:)
型号
首先,我将价格低于100万美元的汇款排除在外,这太混乱了。 然后他将所有数据带到一个有一百五十个字段的大表中,其中每个转会都有关于他的所有可用信息(关于转会本身,球员和他的统计数据,以及参与其中的俱乐部,联赛等)的信息。 )
让我们看看如何创建模型的步骤:
在完成所有Python导入并加载了非规范化传输表之后,我们需要确定的第一件事是将哪些字段视为数字字段,将哪些字段视为分类字段。 这本身就是一个非常有趣的主题,您可以在注释中进行讨论,但是为了节省时间,我仅描述我使用的规则:默认情况下,我考虑所有类别,除了那些以浮点数或那些具有不同值的数量足够大的对象。
例如,在这种情况下,我认为转移年份是分类年份,尽管最初是数字,因为此处不同值的数量很小(从2008年到2018年为10)。 但是,例如,该球员上赛季的表现(以每场比赛的平均进球数表示)是浮动的,几乎可以取任何值,因此我认为它是数值。
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
然后,在明确说明我们的预期-转移金额( fee )后,我们将数据随机分为80%和20%两部分。 首先,我们将教我们的神经网络,另一方面,我们将教您检查预测的准确性。
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
在最后的准备阶段,我们需要做出选择,如何衡量我们的预测的合理性。 然后,我选择了不是Universe局部中最标准的度量标准-误差百分比( MdAPE )的中位数。 或者,更简单地说,我们最有可能在随机收取的转让价格中犯错误的百分比(转让的绝对价格可能相差一个数量级)。 在我看来,“转移预测系统的准确性”一词对我而言到底意味着什么。
实际上,现在是时候开始学习网络了。
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
预测精度

Validation Error = 0.3492意味着在训练了新的( validation set , validation set )数据集之后,该模型的平均(中位数)相对于实际转让价格错误了34%。 而且我们仅从本教程中获取了几行代码后才得到它。
34%的误差,是很大还是有点? 一切都是相对的。 当然,唯一可比较的来源是transfermarkt,其数据可以视为转移金额的“ 预测 ”。 幸运的是, kaggle的数据中有一个字段,显示了该站点在转移时如何评价球员,并且可以对此进行比较。 在此应注意,transfermarkt从未声称其market value是可能的转让价格。 相反,他们强调说,它更是玩家的“ 诚实价值 ”。 一个特定的俱乐部在特定情况下为它支付多少钱是一件非常个别的事情,并且可以在一个很大的范围内沿一个方向或另一个方向波动。 但这是我们最好的, 让我们比较一下 。

Transfermarkt错误-35% ,我们的模型-35% 。 非常奇怪,老实说,非常可疑。
在这一点上,我建议再考虑一下。 一个历史悠久的网站,其创建只是为了展示玩家的“价值”,它依赖于人群效应的全部力量(它是从普通访问者和市场专业人士的评级中获得价值)以及一方面的专家知识和模型,对足球一无所知的人,除了我们提供的数据外,什么都看不到(在现实世界中的这些数据之外,还有很多人拥有转移商标的考虑因素),另一方面,它们也表现出相同的错误 。 此外,我们的模型还可以预测玩家的租金价格,由于明显的原因,该价格不会显示出market value (考虑到此类交易,转让市场的结果甚至更糟 )。
老实说,我仍然认为我这里有某种错误,一切都太好了,难以置信。 但是,尽管如此,让我们走得更远。
测试自己的一种简单方法是尝试对两种来源(模型和transfermarkt)的预测取平均。 如果预测彼此真正独立,并且没有烦人的错误,那么结果应该会有所改善。

实际上,对预测进行平均可以将预测误差降低到32%(!)。 这看起来似乎有些不足,但是我们必须了解,我们正在从数据中过滤掉更多的信息,这些信息被压缩到最大程度。
但我认为,尽管这超出了fast.ai教程的范围,但接下来我们将做的事情更加令人惊讶和有趣。
功能重要性
神经网络,并不是说它是完全不应该的,通常被认为是“黑匣子”。 我们知道可以放入哪些数据,可以得到模型的预测,甚至可以评估平均而言,该预测的正确率是多少。 但是我们无法通过什么标准来解释模型“做出”这个或那个决定。 网络本身的内部结构是如此复杂,更重要的是,它是非线性的,以至于不可能直接追踪整个决策链并从那里得出真实结论。 但是真的很想。 我想了解什么最影响转账金额。
好吧,我们不会进入网络内部。 但是,每个领域的重要性意味着什么,我们称之为功能重要性 (FI)? 理解“重要性”的一种选择是计算如果没有此字段,情况会恶化多少。 而这正是我们可以衡量的。 现在,我们有了一个可以对任何数据集进行预测的工具。 因此,如果我们仅计算在替换字段中的随机数据时预测误差将增加多少,那么我们就可以估计它(字段)对最终结果的影响程度,这意味着它的重要性。 为了保持数据的真实分布,该字段将不仅用随机数填充,而且还用它的随机混合值填充(也就是说,我们将在原始表中仅混合列,例如“转让年”)。 为了保真,可以通过对结果求平均来对每个字段执行多次此过程。 一切都很简单。 现在,让我们看看如何理智地得出结果:
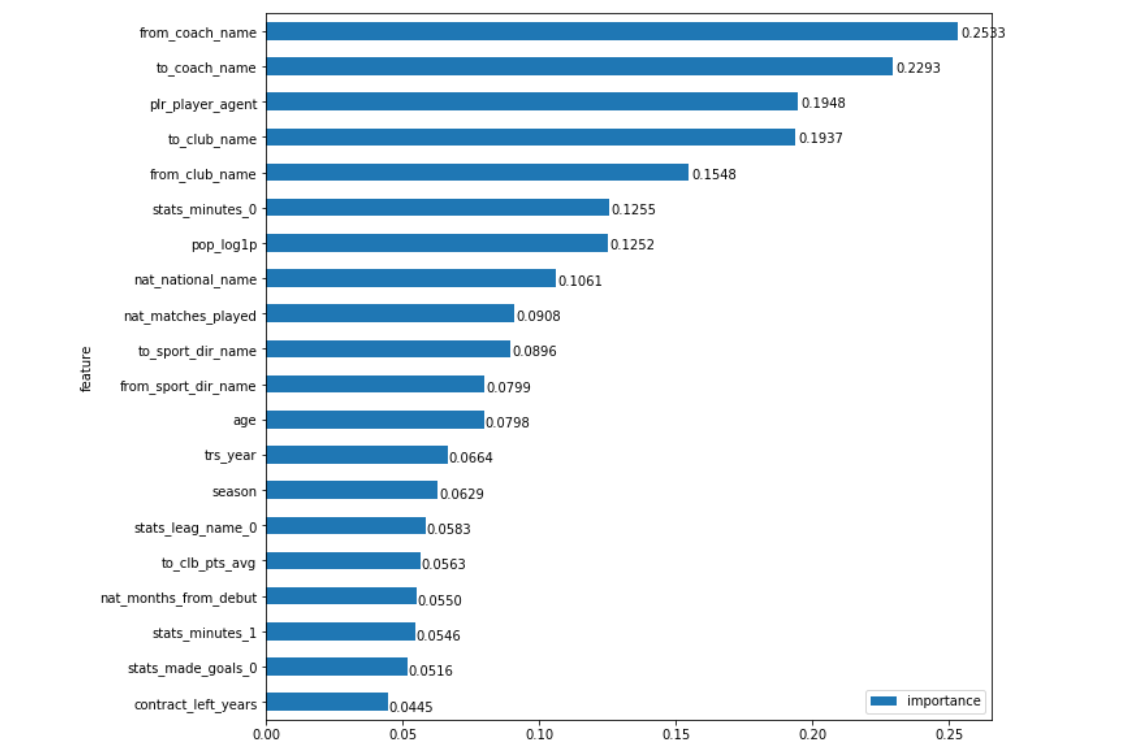
我的直觉说:“是,不是!”
一方面,您期望看到的字段位于最上方:球员去from_coach_name ,去哪里的团队教练( from_coach_name , to_coach_name ),参与转会的俱乐部本身( from_club_name , to_club_name ),球员的经纪人( plr_player_agent ),他在社交网络中的声望( pop_log1p )等 但另一方面,从直觉上讲,教练的名字似乎并没有比俱乐部本身具有更大的权重(我们很清楚有条件的本菲卡有能力将他的球员卖掉)。 教练的品牌比俱乐部的品牌对价格的影响更大吗? 有条件的曼奇尼的到来是否会迫使俱乐部多付钱? 什么是数据给我们提供新的,有点违反直觉的信息或只是模型中的错误的情况?
让我们做对。 仔细观察一下图表,眼睛很快就会发现奇怪的事情。 在中心正下方,附近有2个trs_year和season字段,它们表示转移的年份和进行转换的季节(通常,它们可能并不重合,尽管这种情况并不经常发生)。 首先,似乎他们应该提高价格,我们知道近年来足球运动员的价格上涨了多少,其次,它们显然意味着同一件事。 怎么办呢? 只是总结一下它们的重要性? 事实并非如此! 但是我们绝对可以做的是将相同的方法(混合值)应用于这两个字段,而不是分别应用于这两个字段。 也就是说,如果在这两列中同时存在随机值,则测量错误将如何变化。 好吧,由于我们多年来一直在进行此操作,因此我们需要查看是否还有其他与“连接”相同的字段。
例如,对于一个俱乐部,我们有几个参数:俱乐部本身( club_name )以及关于它的一组信息-来自哪个联赛,哪个国家/地区等。 ( club_is_first_team , clb_lg_name , clb_lg_country , clb_lg_group )。 仅在某些情况下,我们才想知道它对价格有多大影响,例如,玩家分别前往的国家( clb_lg_country ),对于我们来说,最重要的是了解``俱乐部''字段的总权重是什么,这已经在某个国家/地区,联赛等中了。 。
因此,我们可以根据语义内容将所有字段组合成组。 这将帮助我们简单地了解主题领域和常识以及所计算出的特征的“邻近度”。 后者仅显示字段之间如何相互关联,也就是说,可以将它们视为一个单独的组有多少。
应用这种方法,我们可以更直观地了解这些字段的重要性:
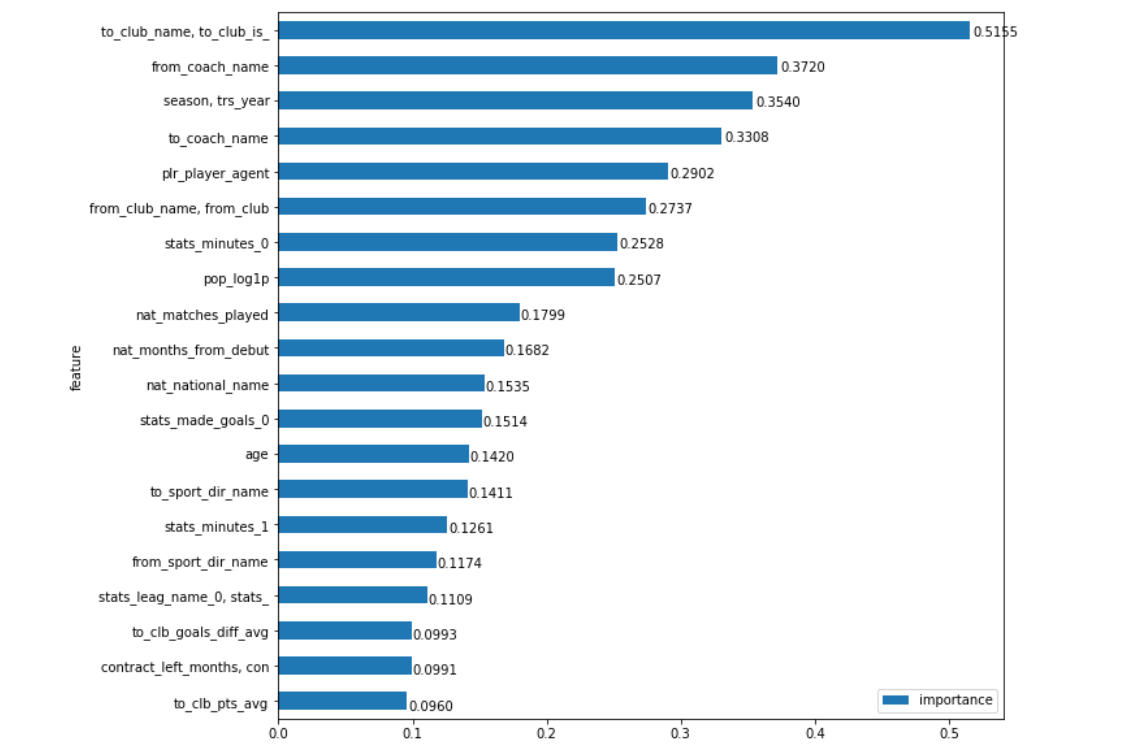
你去。 确切地说,球员购买最多的俱乐部会影响转会额,而且利润率非常高。 例如,Hi Man City,巴塞罗那,泽尼特(Zenit)以及同一本菲卡(毕竟,有些俱乐部能够以比“市场”便宜的价格购买到优质的球员,这一事实“ 强烈影响 ”了同一件事)。 在我看来,处理数据最有趣的事情是,一旦获得数据,结论是显而易见的(嗯,我怀疑俱乐部购买者对转账金额的影响最大),另一方面,这令人有些惊讶(对于第一个候选人,从直觉上讲,这个地方可能有点,与第二个地方的分离似乎并不那么重要)
仍然有很多有趣的发现。 例如,从模型的角度来看,从球员那里购买球员的教练的名字仍然比俱乐部重要。让差异大大减少。 原则上可以找到对此的逻辑解释(尽管有时可以找到任何东西)。 有些教练(瓜迪奥拉,克洛普,贝尼特斯,别尔迪耶夫)在不同的俱乐部中都遵循某种游戏意识,这更好地揭示了反之亦然,这会使球场上的某些位置变得不那么明亮,并且球员的知名度极大地影响了其价格。 关于俱乐部,可以这么说,几乎是不可能的。 而且我们看到的事实是,与俱乐部更换教练相比,教练并没有从根本上偏离比赛原则,而是保持相同的哲学思想(例如,副手,除了想到阿贾克斯和巴萨非常值得怀疑)。也许某些经理人显示出比俱乐部更稳定的球员。 尽管在这里我不会坚定地坚持我的发言。
在纯粹的统计指标中,最高的金额只是该球员去年在其主要比赛中在场上所花费的时间( stats_minutes_0 )。 这完全是合乎逻辑的,因为上个赛季该球员在他的俱乐部中是“主要”球员的人数似乎比其他球员更能通用地衡量其成功–例如进球数或获得的牌数。
播放器的人气( pop_log1p )关闭了这8个最重要的参数组。 值得回顾的是,我们提供的过去十年的数据。 我认为,如果我们考虑过去5年,这一领域的重要性会更高,对于过去10年的平均值,这是完全可以理解的结果,尤其是如果考虑到下一个位置的差距。
好吧,我想引起注意的最后一件事是代理字段( plr_player_agent )的重要性。 我将对此不加评论,因为如果您可以在关于代理人的(非)需求的争执中打破副本的边际,那么毫无疑问他们对现代转让市场的影响程度(尽管该模型建议不要高估它)。

顺便说一下,这种分析方法中最有趣的事情可能就是它的可访问性:不必为了获得有关参数重要性的信息而创建“ 理想 ”模型。 在许多情况下,仅需至少进行预测就可以了,从统计学上讲,它与掷硬币有显着不同,并且您已经获得了通常包含有趣见解的结果,或者告诉您可以从哪个角度看数据。
然后是时候四舍五入了,以免增加过多的文本。 在离别时,我想再次敦促所有对此主题感兴趣的人尝试(我认为,对于初学者来说最好的)深度学习课程-fast.ai并将所学的知识应用到“您的专业领域”,您很可能会是第一个参加此课程的人:)
而且,如果您愿意,我将尝试掌握有关实验的文章的第二部分,其中该模型将使用功能相同的工具- 部分相关性将告诉您:哪个代理商的客户最适合成为足球运动员,哪个俱乐部的转让政策最有效,哪个教练的增幅最大球员的成本(除了显而易见的候选人之外,还有许多不太值得推广的“品牌”显然值得仔细研究)以及更多。
第2部分- 足球转让模型:深入研究