你好 我们有15260多个对象和38000个网络设备,需要对其进行配置,更新和验证,以使其正常运行。 维护这样一批设备非常困难,需要大量时间,精力和人员。 因此,我们需要使网络设备的工作自动化,因此我们决定采用“网络即代码”的概念来管理公司中的网络。 在削减后,请阅读我们的自动化历史,犯的错误以及进一步的构建系统计划。
长话短说,我们要自动化网络
你好 我的名字叫Alexander Prokhorov,我们和我们部门的网络工程师团队一起在
#IT X5中工作 。 我们的部门开发网络基础架构,监控,网络自动化以及“网络即代码”的趋势。
最初,我原则上并不真正相信网络中的任何自动化。 遗留和配置错误很多-并非到处都有中央授权,不是所有硬件都支持SSH,也不是到处都配置
SNMP 。 所有这些极大地破坏了人们对自动化的信念。 因此,首先,我们整理了启动自动化所需的内容,即:SSH连接的标准化,单一授权(
AAA )和SNMP配置文件。 所有这些基础使您能够编写用于将配置大量交付给设备的工具,但是问题来了:我可以获得更多吗? 因此,我们特别需要为自动化的发展以及网络作为代码的概念制定计划。
根据思科的说法,网络即代码的概念意味着以下原则:
- 将目标配置存储在资源库的源代码管理中
- 配置更改通过存储库“真理的单一来源”进行
- 通过API嵌入配置

前两点允许您将DevOps或NetDevOps方法应用于管理网络基础结构。 第三段有很多困难,例如,如果没有API,该怎么办? 当然,SSH和CLI,我们是网络专家!
这就是我们所需要的吗?仅仅应用这些原理并不能解决网络基础设施的所有问题,就像它们的应用需要一定的网络数据基础一样。
当我们考虑这个问题时出现了以下问题:
- 好的,我将配置存储为代码,如何将其应用于特定对象?
- 好的,我的存储库中有一个配置模板,但是如何基于该模板自动为对象配置配置呢?
- 如何找出该对象应采用的型号和供应商? 我可以自动做到吗?
- 如何检查对象的当前设置是否与存储库中的参数匹配?
- 如何处理存储库中的更改并将其复制到生产网络上?
- 关于零接触配置,我需要考虑哪些数据集和系统?
- 供应商甚至同一供应商的型号之间的差异如何?
- 如何存储子网以进行自动配置?
基于上述所有问题,很明显,我们需要一套能够解决各种问题,相互配合并为我们提供有关网络基础结构的完整信息的系统。

除了尝试将新方法应用于网络管理外,我们还想解决网络基础设施中一些更严重的问题,例如数据完整性,更新以及自动化。 自动化不仅意味着向设备大量交付配置,还意味着自动配置,网络设备清单数据的自动收集以及与监控系统的集成。 但是首先是第一件事。
我们针对的功能是:
- 网络设备数据库(+发现,+自动更新)
- 基本网络地址(IPAM +验证检查)
- 监控系统与库存数据的集成
- 在版本控制系统中存储配置标准
- 自动形成对象的目标配置
- 批量向网络设备交付配置
- 实施CI / CD流程来管理网络配置更改
- 使用CI / CD测试网络配置
- ZTP(零接触配置)-自动设置对象的设备
长话短说,我们尝试过自动化2年前,我们开始尝试自动化网络设置工作。 为什么现在这个问题再次出现并需要引起注意?
用手配置数十个设备既麻烦又无聊。 有时工程师的手抽搐,他会犯错。 几十个工程师通常一个脚本就足够了,它将更新后的设置滚动到网络设备上。
为什么不停在那里? 实际上,许多网络工程师已经知道如何做各种python,而那些不知道怎么做的人很快就能做到(但是,Natalya Samoilenko
在Python上发表
了出色的著作 ,特别是对于网络人员而言)。 负责配置n + 1路由器的任何人都可以编写脚本并快速推出设置。 比将所有内容恢复原状的速度快得多。 根据自动化“每个人都为自己”的经验,当您只能用手动手并且整个团队承受巨大痛苦时,就会发生错误。

例子
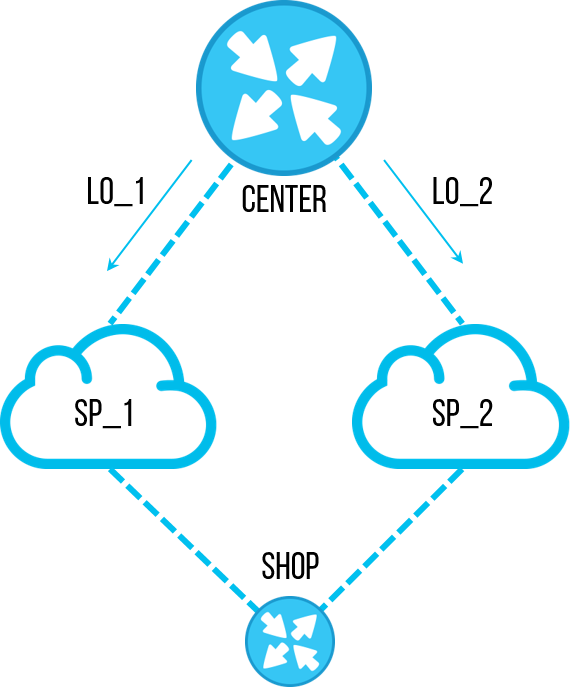
一次,一位工程师决定执行一项重要任务-恢复路由器配置的顺序。 作为对多个对象的审核的结果,发现了带有特定子网的陈旧
前缀列表 ,而我们不再需要它。 以前,它用于过滤中央站点的
环回地址,以便它们仅通过一个通道,我们可以在此通道上测试连接。 但是机制进行了优化,因此他们停止使用这种通道测试方案。 员工决定删除此
前缀列表 ,以使其不会影响配置并在将来引起混乱。 每个人都同意删除未使用的
前缀列表 ,任务很简单,他们立即忘记了。 但是,用双手放在多个对象上删除相同的
前缀列表非常无聊且耗时。 然后,工程师编写了一个脚本,该脚本将快速浏览设备,制作
“ no prefix-list pl-cisco-primer”,并郑重地保存配置。
讨论后的某个时间,几个小时或一天,我不记得有一个物体掉落了。 几分钟后,另一个类似。 无法访问的对象数量持续增长,在半小时内达到了10个,并且每2-3分钟就会添加一个新对象。 连接所有工程师进行诊断。 事故开始后40至50分钟,每个人都被询问有关更改的内容,员工停止了脚本。 那时,已经有大约20个带有破碎通道的物体。 一次完整的修复花了7个工程师几个小时。
技术方面
前缀列表用于过滤
回送 -一个过滤在一个通道上,第二个过滤在备份上。 这用于测试通信,而无需在通道之间切换生产流量。 因此,在
BGP邻居
上传入
路由映射的第一条规则是带有
“ match ip address prefix list”的 DENY 。
路线图中的其余规则都是
PERMIT 。
有几个细微差别可能值得注意:
- 没有匹配项的路线图规则-跳过所有内容
- 前缀列表的末尾是 隐式deny ,但前提是它不为空
- 空的前缀列表是隐式许可
以上所有内容对于
Cisco IOS都是正确的。 声明
路由映射时 ,可能会出现一个空的
前缀列表 ,使其
与“ ip address prefix-list pl-test-cisco”匹配 。 该
前缀列表不会在配置中明确声明(除了具有
match的行),但可以在
show ip prefix-list中找到 。
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
回到所发生的情况,当脚本删除
前缀列表时,该
前缀列表为空,因为它仍位于
route-map的第一个
DENY规则中。 空
前缀列表允许所有子网,因此
BGP对等体传递给我们的所有信息都属于第一条
DENY规则。
工程师为什么不立即注意到他断开了连接? 在这里,Cisco扮演了
BGP计时器的角色。
BGP本身并不按计划交换路由,并且如果您更新了
BGP路由策略,则需要重置BGP会话以将更改
“ clear ip bgp <peer-ip>”应用到Cisco。
为了不重置会话,有两种机制:
软重新配置将保留在
UPDATE中从邻居收到的有关路由的信息,直到在本地
adj-RIB-in表中应用了策略为止。 更新策略时,可以从邻居模拟
UPDATE 。
路由刷新是对等方根据请求发送
UPDATE的“能力”。 建立邻居时,应商定是否有此机会。 优点-无需在本地存储
UPDATE的副本。 缺点-实际上,在邻居发出
更新请求之后,您需要等待他发送
更新请求。 顺便说一句,您可以使用隐藏命令在Cisco上禁用该功能:
neighbor <peer-ip> dont-capability-negotiate
思科有一个未记录的功能-30秒计时器,该计时器由
BGP策略的更改触发。 更改策略后,将在30秒内开始使用上述技术之一更新路由。 我找不到该计时器的书面说明,但在
BUG CSCvi91270中有提及。 您可以在实践中了解其可用性,

在实验室中进行更改并在
调试中寻找到邻居或
软重新配置过程的 UPDATE请求之后。 (如果有关于该主题的其他信息,您可以在评论中保留)
对于“
软重配置” ,计时器的工作方式如下:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
对于这样从邻居侧
刷新路径 :
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
如果对等方之一不支持
Route-Refresh ,并且未启用
软重配置入站 ,则将不会自动执行通过新策略进行的路由更新。
因此,
前缀列表被删除,连接保持不变,在30秒后它消失了。 该脚本设法更改了配置,检查了连接并保存了配置。 在大量对象的背景下,脚本的跌倒并没有立即联系起来。
通过测试和部分复制设置,可以很容易地避免所有这些情况,人们认为自动化应该集中和控制。

我们需要的系统及其连接
扰流板的简短结论-更好地系统化和控制配置的批量交付过程,以免批量交付配置错误。
- DevOps: 50ms 4 - : ", !@#$%"
我们得出的方案包括“业务”主数据块,“网络”主数据块,网络基础设施监视系统,配置交付系统,带有测试单元的版本控制系统。
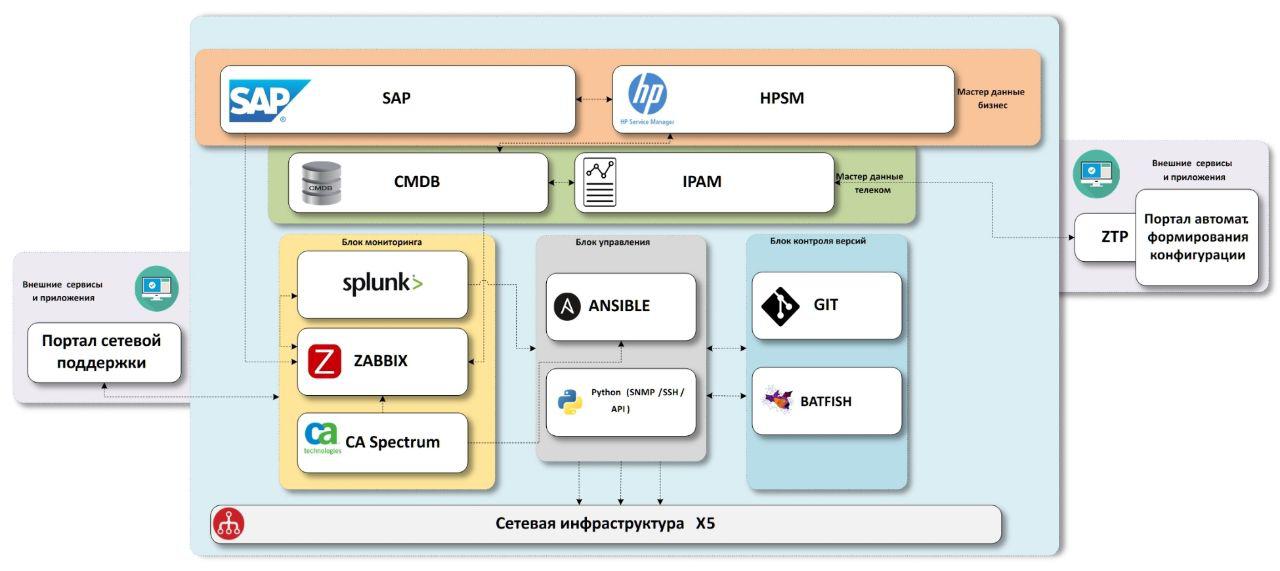
我们需要的只是数据
首先,我们需要知道公司中有哪些对象。
SAP -
ERP公司系统。 几乎所有设施的数据都存在,更确切地说,所有商店和配送中心的数据都在那里。 此外,还有通过库存清单编号通过IT仓库的设备数据,这对我们将来也很有用。 仅缺少办公室,它们不在系统中启动。 从打开的那一刻开始,我们试图在一个单独的过程中解决此问题,我们需要在每个对象上建立连接,然后选择用于通信的设置,因此,此时此刻我们需要创建主数据。 但是数据不足是一个单独的主题,如果对此有兴趣,最好将其放在单独的文章中。
HPSM-包含用于IT,事件管理,变更管理的通用
CMDB的系统。 由于系统对于所有IT都是通用的,因此它必须具有所有IT设备,包括网络设备。 在这里,我们将通过网络添加所有最终数据。 通过事件和变更管理,我们计划将来与监视系统进行交互。
我们知道我们拥有的对象,并通过网络上的数据丰富它们。 为此,我们有两个系统-SolarWinds的
IPAM和我们自己的CMDB.noc系统。
IPAM是IP子网的存储库,有关公司IP地址所有权的最正确和正确的数据应在此处。
CMDB.noc-具有WEB界面的数据库,用于存储网络设备上的静态数据-路由器,交换机,访问点以及提供者及其特征。 在静态下意味着他们的改变只能在人的参与下进行。 换句话说,自动发现不会更改此数据库;我们需要它来了解在对象上应“安装”什么。 需要它的基础作为整个公司使用的生产系统和内部网络工具之间的缓冲。 加快开发速度,添加必要的字段,新的关系,调整参数等。 另外,此解决方案不仅可以提高开发速度,而且还可以在我们需要的数据之间存在这些关系而毫不妥协。 作为一个小示例,我们在数据库中使用多个
exid进行IPAM,SAP和HPSM之间的通信。
结果,我们收到了所有对象的完整数据,并附带了网络设备和IP地址。 现在,我们需要在这些站点上提供的配置模板或网络服务。

真理的单一来源
在这里,我们刚刚达到了第一个NaaC原理的应用-将目标配置存储在存储库中。 在我们的例子中,这就是Gitlab。 对我们来说,选择很简单:
- 首先,我们公司中已经有了该工具,我们不需要从头开始部署它
- 其次,它非常适合我们当前和将来在网络基础架构上的所有任务
自动化的主要有趣部分将发生在Gitlab中-更改配置标准或更简单地说是模板的过程。
标准变更流程示例
我们拥有的对象类型之一是Pyaterochka商店。 在那里,典型的拓扑结构由一个路由器和一个/两个交换机组成。 模板配置文件存储在Gitlab中,这部分的一切都很简单。 但这还不是NaaC。
现在让我们说一个新项目。 新IT项目的任务是在一定数量的商店中进行试点。 根据试验的结果-如果成功,则对所有此类对象进行复制; 否则,将折叠领航员而不执行复制。
这个过程非常适合Git逻辑:
- 对于新项目,我们创建一个分支,在此更改配置。
- 在Branch中,我们还保留了正在对该项目进行试验的对象列表。
- 如果成功,我们将在master分支中进行合并请求,这将需要复制到prod网络
- 如果发生故障,请离开“分支”以获取历史记录,或者直接删除

初步估算-即使没有自动化,它也是用于网络配置的非常方便的工具。 尤其是当您想象同时出现三个或更多项目时。 当需要发布prod中的项目时,您将需要解决合并请求中的所有配置冲突,并检查设置的更改是否互斥。 这在git中非常方便。
另外,这种方法使我们可以灵活地使用Gitlab CI / CD工具来虚拟测试配置,从而自动将配置交付给测试台或一组试验对象。 //即使您愿意,也可以生产。
将配置部署到任何环境
最初,主要目标是精确地大量交付配置,这是一种非常明显的工具,可让您节省工程师的时间并加快配置任务的执行速度。 为此,甚至在大型活动“网络即代码”开始之前,我们就编写了
python解决方案,用于连接到设备以收集设备配置或对其进行配置。 这是
netmiko ,这是
pysnmp ,这是
jinja2 ,等等。
但是现在是时候将批量配置分为几个亚种了:
将配置交付给测试和试验区域此项基于Gitlab CI,它使您能够将配置交付到管道中的试验区和测试区。
产品中的配置重复- 一个单独的项目,最常见的是复制到38k设备中,发生多次浪潮-数量增加-监视生产情况。 另外,如此大规模的工作需要工作的协调,因此最好手动启动此过程。 为此,使用Ansible + -AWX并从我们的主数据系统加快库存的动态编译非常方便。
- 另外,当您需要让第二行启动执行复杂而重要的操作(例如在站点之间切换流量)的预配置剧本时,这是一种便捷的解决方案。
资料收集由于有时有人突然拆下交换机或安装新设备,因此我们将任务分配在单独的区域中,但我们事先不知道这一点。 因此,此设备将不在我们的主数据中,并且将脱离配置交付,监视以及一般的操作工作。 可能是合法安装了该设备,但在那里配置错误地“倒入”,并且由于某种原因,用于访问的
ssh ,
snmp ,
aaa或非标准密码无法正常工作。 为此,我们让python尝试了公司可能拥有的所有可能的
旧式连接方法,对所有旧密码进行了暴力破解,所有这些都是为了打铁并准备使用
ansible和监视。
有一个简单的方法-使多个
清单文件可用,在其中描述所有可能的连接数据(具有所有可能的用户名/密码对的所有类型的供应商),并为每个
清单变体运行一本
手册 。 我们希望有一个更好的解决方案,但是在RedHat会议上,Ansible建筑师提出了同样的建议。 通常假定您事先知道要连接的对象。
我们需要一个通用的解决方案-删除备份时,寻找新设备,如果找到了新设备,请将其添加到所有必要的系统中。 因此,我们选择了python解决方案-知道比它本身可以检测网络硬件的程序更漂亮的方法,而不管其上进行了什么配置(当然,在合理的范围内),根据需要进行配置,删除配置,同时,将API数据添加到所需的系统。
验证,如监控
自动化的任务之一当然是找出从自动化中产生的后果。 并非所有38k都在第一次配置时就完美配置,甚至发生有人用手摆放设备的情况。 并且有必要跟踪这些更改并恢复目标配置的
公正性 。
有三种方法可以验证配置是否符合标准:
- 定期进行一次检查-卸载当前状态,对照目标进行检查,并纠正已发现的缺陷。
- 如果不进行任何检查,则每隔一段时间-推出目标配置。 没错,有可能会破坏某些东西-也许目标配置中没有所有内容。
- 一种方便的方法是将与“真相单一来源 ”中目标配置的差异视为警报并由监视系统进行监视。 这包括:与当前配置标准不匹配,硬件与主数据中指定的硬件之间的差异,与IPAM中的数据不匹配。
在第三种情况下,似乎可以选择将此工作转移到事件管理(OS),以便在整个过程中在一小部分中消除不一致性,而不是一次被紧急情况消除。
我在前面的文章
“我们如何监视14,000个对象”中曾写过
Zabbix ,它是我们的分布式对象监视系统,我们可以在其中创建我们可以想到的任何触发器和警报。 自撰写上一篇文章以来,我们已经升级到Zabbix 4.0
LTS 。
基于
Web Zabbix,我们对网络支持门户进行了更新,现在您可以在一个屏幕上从我们所有系统上找到有关对象的所有信息,以及运行脚本以检查是否经常发生问题。
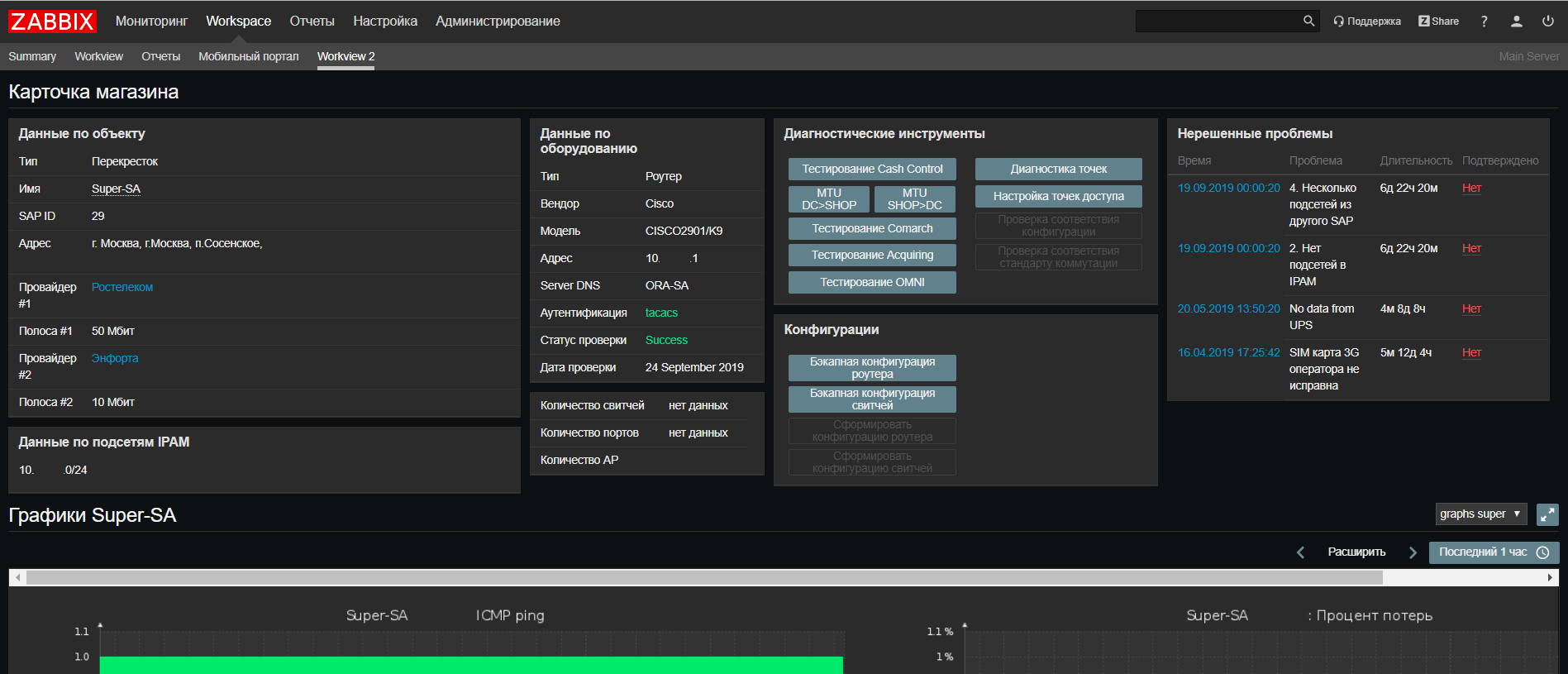
我们还引入了一项新功能-对于我们来说,Zabbix在某种程度上已成为
CRON,用于启动调度脚本,例如系统集成脚本,自动发现脚本。 当您需要查看当前脚本以及它们在何时何地运行而不检查所有服务器时,这确实非常方便。 的确,对于运行30秒钟以上的脚本,您将需要一个
启动器来启动它们而无需等待结束。 幸运的是,它很简单:
 Splunk
Splunk是一种解决方案,允许您从网络设备收集事件日志,它也可以用于监视自动化。 例如,收集配置备份后,
python脚本会生成
LOG消息
CFG-5-BACKUP ,路由器或交换机会将消息发送到Splunk,在此我们计算来自网络设备的此类消息的数量。 这使我们能够跟踪脚本已检测到的设备数量。 我们看到有多少铁可以向
Splunk报告,并验证所有铁片中的消息是否到达。
Spectrum是一个用于监视关键对象的综合系统,这是一个功能非常强大的工具,可以帮助我们解决关键的网络事件。 在自动化中,我们仅使用它从中提取数据,它不是
开源的 ,因此可能性有所限制。
蛋糕上的樱桃

使用带有设备主数据的系统,我们可以考虑创建ZTP或零接触配置。 就像一个按钮一样,“自动调整”,但是没有按钮。
我们具有前面各块中的所有必要数据-我们知道对象,其类型,所用设备(供应商和型号),地址是什么(IPAM),当前配置标准是什么(Git)。 通过将它们放在一起,我们至少可以准备要上传到设备的配置模板,它更像是One Touch Provisioning,但有时不需要更多。
真正的零接触需要一种自动将配置交付给未配置硬件的方法。 而且,无论供应商如何,都是理想的。 有几个工作选项-控制台服务器(如果所有设备都通过中央仓库),移动控制台解决方案(如果设备立即到达)。 我们只是在研究这些解决方案,但是一旦有可行的选择,我们就可以共享它。
结论
总体而言,在我们的“
网络即代码”概念中,有5个主要里程碑:
- 主数据(系统和数据之间的通信,系统的API,数据支持和启动的充分性)
- 监视数据和配置(自动发现网络设备,检查设施中配置的相关性)
- 版本控制,测试和试点配置(应用于网络的Gitlab CI / CD,网络配置测试工具)
- 配置交付(Ansible,AWX,python脚本进行连接)
- 零接触配置(需要什么数据,如何构建流程,如何连接到未配置的硬件)
不能将所有内容都写到一篇文章中,每个项目都需要进行单独的讨论,我们现在可以谈论一些事情,在实践中检查解决方案时可以谈论一些事情。 如果您对任何主题都感兴趣-最后,将进行一项调查,您可以为下一篇文章投票。 如果该主题未包含在列表中,但有趣的是请阅读该主题,请尽快发表评论,一定要分享我们的经验。
特别感谢Virilin Alexander(
xscrew )和Sibgatulin Marat(
eucariot )在2018年秋季对yandex云的参考访问以及有关云网络基础架构自动化的故事。 在他之后,我们得到了关于在X5零售集团的基础架构中使用自动化和NetDevOps的灵感和很多想法。