如今,“人工智能”一词意味着很多不同的系统-从用于图像识别的神经网络到用于玩Quake的机器人。 Wikipedia给出了AI的绝妙定义-这是“智能系统的功能,可以执行传统上认为是人类的特权的创造性功能”。 也就是说,从定义中可以清楚地看到-如果某个功能成功实现了自动化,那么它将不再被视为人工智能。
但是,当最初设定“创建人工智能”的任务时,人工智能的含义有所不同。 此目标现在称为“强力AI”或“通用AI”。
问题陈述
现在有两个众所周知的问题表述。 首先是强大的AI。 第二个是通用AI(又称“人工通用情报”,简称AGI)。
更新。 他们在评论中告诉我,这种区别更可能发生在语言层面。 在俄语中,“智能”一词并不完全代表英语中的“智能”一词
强大的AI是一种假设的AI,可以做一个人可以做的一切。 通常会提到他必须在初始设置中通过图灵测试(嗯,人们通过了吗?)。要意识到自己是一个独立的人,并且能够实现自己的目标。
也就是说,它有点像一个虚构的人。 我认为,这种AI的用处主要是研究,因为强AI的定义在任何地方都不会说其目标是什么。
AGI或通用AI是“结果机器”。 她在输入端收到特定的目标设置-并对电动机/激光器/网卡/显示器发出一些控制动作。 并且目标得以实现。 同时,AGI最初并不了解环境,仅了解传感器,执行器和设定目标的渠道。 如果该管理系统可以在任何环境中实现任何目标,则将被视为AGI。 我们让她开车,避免发生事故-她会处理。 我们让她控制一个核反应堆,以便有更多的能量,但不会爆炸-她可以处理。 我们将给您一个邮箱,并指示销售吸尘器-也将应付。 AGI是“逆问题”的解决者。 要检查售出了多少个真空吸尘器,很简单。 但是弄清楚如何说服人们购买这款吸尘器已经是智力的一项任务。
在本文中,我将讨论AGI。 没有图灵测试,没有自我意识,没有虚假的个性-非常务实的AI和同样务实的操作员。
现状
现在有诸如强化学习或强化学习之类的系统。 这就像AGI,只是没有通用性。 他们能够学习,并因此在各种环境中实现目标。 但是,它们仍然距离在任何环境下实现目标都非常遥远。
一般而言,强化学习系统是如何安排的,它们有什么问题?
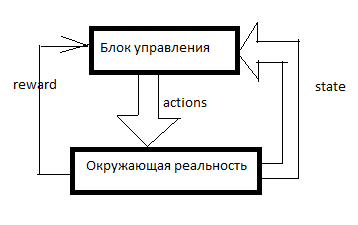
任何RL都是这样排列的。 有一个控制系统,有关周围现实的一些信号通过传感器(状态)和控制机构(动作)进入周围环境,并进入控制系统。 奖励是强化的信号。 在RL系统中,加强是从控制单元外部形成的,它表明AI能够很好地实现目标。 例如,最后一分钟售出了多少台吸尘器。
然后,表是由这样的东西组成的(我将其称为SAR表):

时间轴朝下。 该表显示了AI所做的一切,他看到的一切以及所有增强信号。 通常,为了让RL做一些有意义的事情,他首先需要随机移动一段时间,或者观察其他人的移动。 通常,RL在SAR表中至少已经有几行时开始。
接下来会发生什么?
莎莎
强化学习的最简单形式。
我们采用某种机器学习模型,并结合使用S和A(状态和动作),预测接下来几个时钟周期的总R。 例如,我们将看到(基于上表),如果您告诉女人“做男人,买吸尘器!”,那么报酬就会很低;如果您对男人说同样的话,报酬会很高。
可以使用哪些特定模型-我将在后面描述,现在我只会说这不仅是神经网络。 您可以使用决策树,甚至可以以表格形式定义函数。
然后发生以下情况。 AI收到另一条消息或链接到另一个客户端。 所有客户数据都从外部输入到AI中-我们会将客户群和消息计数器视为传感器系统的一部分。 也就是说,仍然需要分配一些A(动作)并等待增援。 AI会采取所有可能的行动,并反过来进行预测(使用相同的机器学习模型)-如果我这样做,会发生什么? 如果是呢? 对此将进行多少加固? 然后RL执行预期获得最大报酬的动作。
我在自己的一款游戏中引入了这样一个简单笨拙的系统。 SARSA在游戏中雇用单位,并在游戏规则发生变化时进行调整。
此外,在所有类型的强化训练中,都存在奖励折扣和探索/利用困境。
当RL尝试不使下N个举动的奖励金额最大化,而是根据“每年100卢布现在比110卢布好”的原则加权时,折扣奖励就是这种方法。 例如,如果折现系数为0.9,而计划范围为3,则我们将在接下来的3个时钟周期内不在总R上训练模型,而是在R1 * 0.9 + R2 * 0.81 + R3 * 0.729上训练模型。 为什么这是必要的? 然后,我们不需要那种在无限处创造利润的AI。 我们需要一个可以在此时此刻产生利润的AI。
探索/利用困境。 如果RL做其模型认为最佳的事情,它将永远不会知道是否有更好的策略。 漏洞利用是一种策略,在这种策略中RL会做出最大承诺的承诺。 探索是一种策略,其中RL会采取某种措施来探索环境以寻求更好的策略。 如何实施有效的情报? 例如,您可以每隔几个度量执行一次随机操作。 或者,您不能制作一个预测模型,而可以制作几个设置略有不同的模型。 它们将产生不同的结果。 差异越大,此选项的不确定性程度越大。 您可以选择操作,使其具有最大值:M + k * std,其中M是所有模型的平均预测,std是预测的标准偏差,k是好奇心系数。
缺点是什么?假设我们有选择。 开车或步行即可到达目标(距离我们10公里,通往那里的路很好)。 然后,在选择之后,我们可以选择-小心移动或尝试撞入每个支柱。
该人员会立即说,开车和谨慎行事通常会更好。
但是SARSA ...他将看看之前导致驾车的决定是什么。 但这导致了这一点。 在最初的统计数据阶段,AI鲁re驾驶并在一半的情况下坠毁。 是的,他可以开车。 但是当他选择是否开车时,他不知道下一步该怎么选择。 他有统计资料-在一半情况下,他选择了适当的选择,在一半情况下-自杀了。 因此,平均来说,走路更好。
SARSA认为,该代理将遵循用于填充表格的相同策略。 并在此基础上行事。 但是,如果我们以其他方式假设-代理商将在接下来的行动中坚持最佳策略该怎么办?
Q学习
该模型为每个州计算从中可获得的最大总奖励。 然后,他将其写在特殊的列Q中。也就是说,如果从状态S得到2点或1(取决于移动),则Q(S)将等于2(预测深度为1)。 我们可以从预测模型Y(S,A)中了解到,可以从状态S获得什么回报。 (S-状态,A-动作)。
然后,我们创建一个预测模型Q(S,A)-也就是说,如果我们从S执行动作A,Q将会进入什么状态。并在表中创建下一列-Q2。 也就是说,可以从状态S获得的最大Q(我们对所有可能的A进行排序)。
然后,我们创建一个回归模型Q3(S,A)-也就是说,如果我们从S执行动作A,我们将到达Q2的状态。
依此类推。 因此,我们可以实现无限深度的预测。
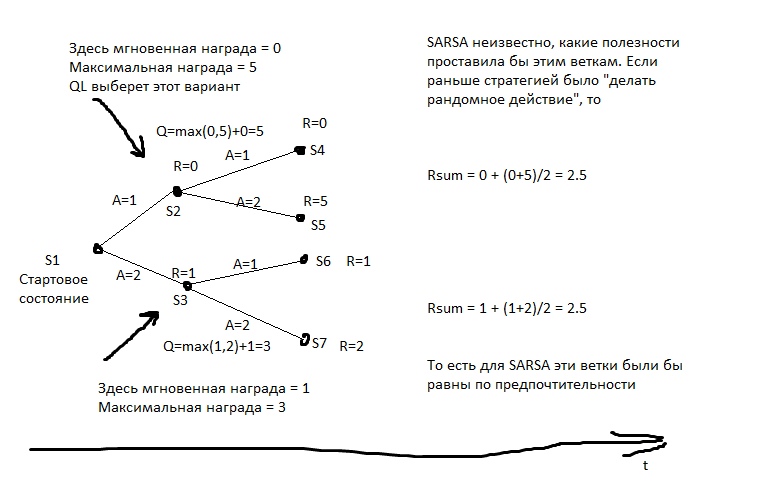
在图片中,R是钢筋。
然后,我们采取的每一步都会选择最大Qn的动作。 如果将这种算法应用于国际象棋,我们将得到理想的极小极大值。 几乎等同于错误估计移动到深处。
q学习行为的常见示例。 猎人有一支长矛,他主动将他带到熊上。 他知道未来的绝大部分动作都有很大的负奖励(失败的方法多于获胜的方法),他知道有些动作有积极的奖励。 猎人相信,将来他会做出最好的举动(不知道SARSA中会采取哪种行动),如果他做出最好的举动,他将击败熊。 就是说,为了去熊,他能够做出狩猎所需的所有要素就足够了,但是没有必要立即获得成功的经验。
如果猎人以SARSA的方式行事,他会假设他将来的行为将与以前大致相同(尽管事实是他现在有了不同的知识包),并且只有在他已经例如,他在超过50%的案件中获胜(好吧,或者如果其他猎人在一半以上的案件中获胜,如果他从他们的经验中学到的话)。
缺点是什么?- 该模型无法应对不断变化的现实。 如果我们一生都因按下红色按钮而获奖,现在他们在惩罚我们,并且没有发生明显的变化……QL将在很长一段时间内掌握这种模式。
- Qn可能是一个非常复杂的函数。 例如,要进行计算,您需要滚动一个N次迭代的循环-迭代速度不会更快。 预测模型通常具有有限的复杂度-即使大型神经网络也具有复杂度限制,并且几乎没有机器学习模型可以旋转循环。
- 现实通常具有隐藏的变量。 例如,现在几点了? 我们看一下表很容易发现,但是一旦我们移开手表,这已经是一个隐藏的变量。 为了考虑这些不可观察的值,模型必须不仅考虑当前状态,而且还要考虑某种历史。 在QL中,您可以执行此操作-例如,不仅将当前的S,而且还将先前的几个S馈入到那里的神经元或周围。 这是在玩Atari游戏的RL中完成的。 此外,您可以使用递归神经网络进行预测-让其在历史记录的多个帧上顺序运行并计算Qn。
基于模型的系统
但是,如果我们不仅预测R或Q,而且一般预测所有感官数据,该怎么办? 我们将不断拥有一份现实的袖珍本,我们将能够检查它的计划。 在这种情况下,我们不必担心计算Q函数的困难。 是的,它需要大量的时间来计算-好吧,无论如何,对于每个计划,我们都会重复运行预测模型。 计划10前进? 我们启动模型10次,每次将模型的输出馈入模型的输入。
缺点是什么?- 资源强度。 假设我们需要在每种度量标准中选择两个替代方案。 然后,对于10个时钟周期,我们将有2 ^ 10 = 1024个可能的计划。 每个计划是10个模型发布。 如果我们用数十个管理机构来控制飞机? 我们是否以0.1秒的时间模拟现实? 您是否希望至少有几分钟的规划时间? 我们将不得不多次运行模型,一个解决方案有很多处理器时钟周期。 即使您以某种方式优化计划的枚举,同样,与QL相比,计算量还是要多几个数量级。
- 混乱的问题。 设计某些系统时,即使输入模拟的误差很小,也会导致巨大的输出误差。 为了解决这个问题,您可以运行一些对现实的模拟-有点不同。 它们将产生截然不同的结果,由此可以了解我们处在这种不稳定的地区。
策略列举方法
如果我们可以访问AI的测试环境,而不是在仿真中实际运行它,那么我们就可以以某种形式写下代理行为的策略。 然后选择-通过发展或其他方式-带来最大利润的策略。
“选择策略”意味着我们首先需要学习如何以可以将其推入演进算法的方式写下策略。 也就是说,我们可以使用程序代码编写策略,但是在某些地方保留系数,然后让演化过程将其提取出来。 或者我们可以用神经网络写下一个策略-让进化来衡量其联系的权重。
也就是说,这里没有预测。 没有SAR表。 我们只需选择一个策略,它就会立即给出动作。
这是一种功能强大且有效的方法,如果您想尝试RL而又不知道从哪里开始,建议您这样做。 这是“看到奇迹”的非常便宜的方法。
缺点是什么?- 需要具有多次运行相同实验的能力。 也就是说,我们应该能够将现实倒退到起点-成千上万次。 尝试新策略。
生活很少提供这样的机会。 通常,如果我们拥有自己感兴趣的流程模型,就无法创建狡猾的策略-即使基于钝性暴力,我们也可以像基于模型的方法一样简单地制定计划。 - 不耐的经历。 我们有多年经验的SAR表吗? 我们可以忘记它,它不适合这个概念。
一种列举策略但“实时”的方法
策略的列举相同,但基于现实生活。 我们尝试一种策略的10个措施。 然后10个小节。 然后是第三小节的10小节。 然后,我们选择一种需要加强的地方。
通过这种方法可以获得最佳的人形行走效果。

对我来说,这听起来有些出乎意料-似乎QL +基于模型的方法在数学上是理想的。 但是没有那样的东西。 这种方法的优点与以前的优点大致相同-但它们并没有那么明显,因为这些策略的测试时间不长(嗯,我们在进化上没有几千年的经验),这意味着结果不稳定。 另外,测试的数量也不能提升到无限-这意味着必须在不太复杂的选择空间中寻求该策略。 她不仅有可以“扭曲”的“笔”。 好吧,体验不宽容并没有被消除。 而且,与基于QL或基于模型的模型相比,这些模型使用效率低下。 与使用机器学习的方法相比,他们需要与现实进行更多的交互。
如您所见,从理论上讲,创建AGI的任何尝试都应包括用于预测奖励的机器学习或某种形式的策略参数表示法-这样您就可以采用诸如Evolution之类的方法来采用该策略。
这是对提供基于数据库,逻辑和概念图创建AI的人们的强烈攻击。 如果您(象征性方法的支持者)阅读此书-欢迎发表评论,我将很高兴知道没有上述机制,AGI可以做什么。
RL的机器学习模型
几乎所有的ML模型都可以用于强化学习。 神经网络当然是好的。 但是,例如,有KNN。 对于每对S和A,我们都寻找最相似的对,但是在过去。 我们正在寻找那之后的R. Stupid? 是的,但是可以。 有决定性的树木-在这里最好是散步关键词“梯度助推”和“决定性森林”。 树是否善于捕获复杂的依赖关系? 使用功能工程。 希望您的AI更接近General? 使用自动有限元! 浏览一堆不同的公式,将它们作为增强功能提交,丢弃会增加误差的公式,并保留会提高准确性的公式。 然后提交最佳公式作为新公式的参数,依此类推。
您可以使用符号回归进行预测-也就是说,仅尝试对公式进行分类以获得近似于Q或R的结果。可以尝试对算法进行分类-然后您会得到一个称为Solomonov的归纳法,这在理论上是最佳的,但是几乎很难训练函数的近似值。
但是神经网络通常是表达能力和学习复杂性之间的折衷方案。 理想情况下,算法回归可以处理任何依赖关系-已有数百年的历史了。 决策树将很快得出结果-但无法推断y = a + b。 神经网络介于两者之间。
发展前景
现在要完全使用AGI的方法有哪些? 至少在理论上。
发展历程
我们可以创建许多不同的测试环境,并开始某些神经网络的发展。 , .
, .
, - RL, , . , RL — — « - , , !». — .
AIXI
Model-Based , . — , , . — , . , . , , — .
. , — , .
Seed AI
, . . ,
, . … ? .
?
, RL actions RL.
RL - - . RL , , .
— , actions .
Seed AI — . ? , ?
, Google, DeepMind . , .
, =) , « , AGI»!