神经网络占领了世界。 他们对访客进行计数,监视质量,保留统计数据并评估安全性。 一堆创业公司,工业用途。
伟大的框架。 什么是PyTorch,第二个TensorFlow。 一切都变得越来越方便,越来越简单...
但是有一个阴暗面。 他们试图对她保持沉默。 那里没有快乐,只有黑暗和绝望。 每次看到正面的文章时,您都会伤心地叹息,因为您了解只是一个人不了解某事。 或隐藏它。
让我们谈谈嵌入式设备上的生产。

有什么问题
好像。 查看设备的性能,确保足够,运行并获得利润。
但是,与往常一样,有一些细微差别。 让我们把它们放在架子上:
- 生产。 如果您的设备不是以单个副本制成的,那么您需要确保系统不会挂起,设备不会过热,如果出现电源故障,一切都会自动启动。 这是一个大型聚会。 这仅给出两个选项-要么在设计设备时都考虑到所有可能的问题。 或者您需要克服源设备的问题。 好吧,例如,这些是( 1,2 )。 当然是锡。 要批量解决他人设备的问题,您需要花费不切实际的能量。
- 真正的基准。 很多骗局和技巧。 在大多数示例中,NVIDIA高估了30-40%的性能。 但不仅她有乐趣。 下面我举许多例子说明生产率可能比您想要的低4-5倍。 您不会被“所有在计算机上运行良好的设备所困扰,这在一定程度上会变得更糟”。
- 对神经网络体系结构的支持非常有限。 有许多嵌入式硬件平台极大地限制了可以在其上运行的网络(Coral,gyrfalcone,snapdragon)。 移植到这样的平台将是痛苦的。
- 支持。 某些功能不适合您,但问题出在设备方面?..这是命运,它将无法正常工作。 仅对于RPi,社区会关闭大多数错误。 并且,部分地,对于杰森。
- 价钱 在许多人看来,嵌入式很便宜。 但是,实际上,随着设备性能的提高,价格将几乎成倍增长。 RPi-4的价格是Jetson Nano / Google Coral的5倍,而强度则是2-3倍。 Jetson Nano比Jetson TX2 / Intel NUC便宜5倍,比它们便宜2-3倍。
- Lorgus。 还记得Zhelyazny的设计吗?
似乎我将其设置为标题图片…… “ 对数是一个不断变化的三维迷宫,代表了多元宇宙中混沌的力量。 ” 所有这些都是大量的漏洞和漏洞,所有这些各种各样的铁屑,所有不断变化的框架……当市场情况在2-3个月内完全改变时,这是正常的。 在这一年中,它已更改了3-4次。 您不能两次进入同一条河。 因此,当前所有想法在2019年夏季都是正确的。
什么是
让我们按顺序排列,它的味道不甜...现在有什么适合神经元了? 尽管有多种选择,但选择不多。 限制搜索的一些常用字词:
- 我不会解析手机上的神经元/推论。 这本身就是一个巨大的话题。 但是,由于电话是具有干扰配合的嵌入式平台,所以我认为这并不坏。
- 我将触摸Jetson TX1 | TX2。 在当前条件下,这些并不是价格最理想的平台,但在某些情况下仍易于使用。
- 我不保证该列表将包括今天存在的所有平台。 也许我忘记了一些东西,也许我不知道一些东西。 如果您知道更多有趣的平台,请写下!
这样啊 明显嵌入的主要内容。 在本文中,我们将精确比较它们:

- Jetson平台。 有几种设备可以使用:
- Jetson Nano-便宜又现代的(2019春季)玩具
- Jetson Tx1 | Tx2-相当昂贵,但在性能和多功能性平台上都不错
- Raspberry Pi 。 实际上,只有RPi4具有神经网络的性能。 但是可以在第三代上完成一些单独的任务。 我什至在一开始就开始使用非常简单的网格。
- Google Coral平台。 实际上,对于嵌入设备,只有一个芯片和两个设备-开发板和USB加速器
- 英特尔Movidius平台。 如果您不是一家大公司,那么只有Movidius 1 | Movidius 2棍棒可供您使用。
- Gyrfalcone平台。 中国技术的奇迹。 已经有两代人了-2801、2803
杂项 在主要比较之后,我们将讨论它们:
- 英特尔处理器。 首先,NUC程序集几乎嵌入
- Nvidia移动GPU。 现成的解决方案可以视为未嵌入。 而且,如果您收集嵌入内容,那么它将对财务产生体面的影响。
- 手机。 Android的特征在于,为了使用最佳性能,必须完全使用特定制造商拥有的硬件。 或使用通用的东西,例如张量流光。 对于苹果来说,也是一样。
- Jetson AGX Xavier是Jetson的昂贵版本,具有更高的性能。
- GAP8-用于超便宜设备的低功耗处理器。
- 神秘丛林AI HAT
杰森
我们与Jetson合作已经很长时间了。 早在2014年,
Vasyutka就在
Jetson上为当时的
Swift发明了数学。 2015年,在与Artec 3D举行的一次会议上,我们谈到了这是一个很酷的平台,然后他们建议我们基于该平台构建原型。 几个月后,原型就准备好了。 整个公司仅工作了两年,就在平台和天堂上遭受了数年的诅咒。而
Artec Leo诞生了,是同类产品中最酷的扫描仪。 甚至Nvidia在TX2的演示中也将他视为平台上创建的最有趣的项目之一。
从那时起,我们在5-6个项目中的某处使用了TX1 / TX2 / Nano。
而且,也许我们知道平台存在的所有问题。 让我们按顺序进行。
杰特逊tk1
我不会特别谈论他。 该平台在当天的计算能力方面非常高效。 但是她不是杂货店。 NVIDIA出售了支持
Jetson的TegraTK1芯片。 但是,这些芯片无法用于中小型制造商。 实际上,除了Nvidia之外,只有Google / HTC / Xiaomi / Acer / Google可以对它们执行某些操作。 所有其他集成到产品中的都是调试板,或者是抢劫了其他设备。
杰特逊TX1 | TX2
Nvidia做出了正确的结论,而下一代产品的表现令人赞叹。 TX1 | TX2,这些不再是芯片,而是板上的芯片。


它们比较贵,但完全是杂货店。 一家小型公司可以将它们集成到其产品中,该产品是可预测且稳定的。 我亲自看到了3-4种产品是如何生产的-一切都很好。
我将讨论TX2,因为从当前行来看它是主板。
但是,当然,并非所有人都感谢上帝。 怎么了
- Jetson TX2是一个昂贵的平台。 在大多数产品中,您将使用主模块(据我了解,从批量大小来看,价格将在200-250到350-400 cu每块之间)。 他需要一个载物板。 我不知道目前的市场,但早些时候大约是100-300立方米 取决于配置。 好吧,在您的腰包上方。
- Jetson TX2不是最快的平台。 下面我们将讨论比较速度,在那里我将说明为什么这不是最佳选择。
- 必须除去大量的热量。 对于我们将要讨论的几乎所有平台,这可能都是正确的。 外壳必须解决散热问题。 粉丝们
- 对于小型聚会来说,这是一个糟糕的平台。 数百种设备-大约 经常订购主板,开发设计和包装。 成千上万的设备? 设计您的主板-别致。 如果您需要5-10-不好。 您极有可能需要使用DevBoard。 它们很大,闪烁时有点令人作呕。 这不是支持RPi的平台。
- 英伟达技术支持差。 我听到很多人发誓,答案是秘密信息或每月答复。
- 俄罗斯基础设施差。 订购困难,需要很长时间。 但同时,经销商运作良好。 我最近遇到了一个Jetson nano,它在发射日就烧光了-毫无疑问地变了。 山姆由快递员接走了。 哇! 此外,他本人也认为莫斯科办事处的建议很好。 但是,一旦他们的知识水平不允许回答问题,并且需要向国际办公室提出请求,他们将不得不等待很长时间。
太棒了:
- 很多信息,非常庞大的社区。
- 在Nvidia周围,有许多生产配件的小公司。 他们愿意进行谈判,您可以调整他们的决定。 还有CarierBoard,以及固件和冷却系统。
- 支持所有常规框架(TensorFlow | PyTorch),并完全支持所有网络。 您可能要做的唯一转换就是将代码传输到TensorRT。 这将节省内存,可能会加快速度。 与其他平台相比,这是荒谬的。
- 我不知道如何繁殖木板。 但是从那些为Nvidia做到这一点的人那里,我听说TX2是一个不错的选择。 有与实际情况相对应的手册。
- 良好的功耗。 但是,所有“嵌入”的东西都将与我们同在-最糟糕的:)
- 俄罗斯的游标卡尺(原因为何)
- 不同于movidius | RPi | 珊瑚| Gyrfalcon是真正的GPU。 您不仅可以在网格上运行,还可以在常规算法上运行
因此,如果您有分段设备,那么这对您来说是一个很好的平台,但是由于某些原因,您无法交付功能齐全的计算机。 巨大的东西? 生物识别-很可能不会。 数字识别在边缘,取决于流程。 价格可能超过5000美元的便携式设备。 汽车-不,将功能更强大的平台放到更贵的位置上会更容易。
在我看来,随着新一代廉价设备的发布,TX2将随着时间的流逝而消失。
Jetson TX1 | TX2 | TX2i等主板看起来像这样:
 在这里
在这里或
这里还有更多变化。
杰森纳米

Jetson Nano是一件非常有趣的事情。 对于Nvidia而言,这是一种新的外形尺寸,就革命性而言,必须与TK1进行比较。 但是竞争对手已经耗尽了。 我们还会讨论其他设备。 它比TX2弱2倍,但便宜4倍。 更确切地说,数学很复杂。 演示板上的Jetson Nano售价100美元(在欧洲)。 但是,如果您只购买芯片,则价格会更高。 而且您将需要繁殖他(还没有适合他的主板)。 上帝禁止在大型聚会上比TX2便宜2倍。
实际上,Jetson Nano在其基板上就是这样的广告产品,适合机构/经销商/业余爱好者使用,应该会引起人们的兴趣和业务应用。 通过优缺点(与TX2部分相交):
- 设计较弱且未调试:
- 它会过热,以恒定的负载定期悬挂/飞行。 一家熟悉的公司已尝试解决所有问题3个月了-它无法解决。
- 用USB供电时,我已经筋疲力尽了。 我听说一个朋友的USB输出烧坏了,插头正在工作。 USB电源很可能会引起一些麻烦。
- 如果包装原始板,则NVIDIA的散热器将不足,例如,它将过热。
- 速度还不够。 几乎是TX2的2倍(实际上,可以是1.5,但取决于任务)。
- 很多5-10的设备通常都很好。 50-200-很难,您必须补偿制造商的所有错误,将其挂在狗身上,如果您需要添加POE之类的东西,那会很痛。 大型派对。 今天,我还没有听说过成功的项目。 但是在我看来,与TK1一样会出现困难。 老实说,我希望明年Jetson Nano 2能够发布,这些儿童疾病将得到纠正。
- 支持不好,与TX2相同
- 基础设施差
好:
- 与竞争对手相比,预算足够。 特别适合小型聚会。 优惠的价格/性能
- 不同于movidius | RPi | 珊瑚| Gyrfalcon是真正的GPU。 您不仅可以在网格上运行,还可以在常规算法上运行
- 只需启动任何网络(与tx2相同)
- 功耗(与tx2相同)
- 俄罗斯的游标卡尺(与TX2相同)
Nano本身是在早春出现的,大约在4月/ 5月,我对此很积极地戳。 我们已经设法在它们上进行两个项目。 通常,上面确定的问题。 作为爱好产品/小批量产品-非常酷。 但是尚不清楚是否有可能拖累生产以及如何进行生产。
谈论杰森的速度。
我们将在以后与其他设备进行比较。 同时,只需谈论Jetson和速度。 为什么Nvidia对我们撒谎。 如何优化您的项目。
下面的所有内容都是关于TensorRT-5.1的。 TensorRT-6.0.1已于2019年9月17日发布,所有声明都必须在此处进行仔细检查。
假设我们相信Nvidia。 让我们打开他们的
网站 ,看看将SSD-mobilenet-v2推断为300 * 300的时间:
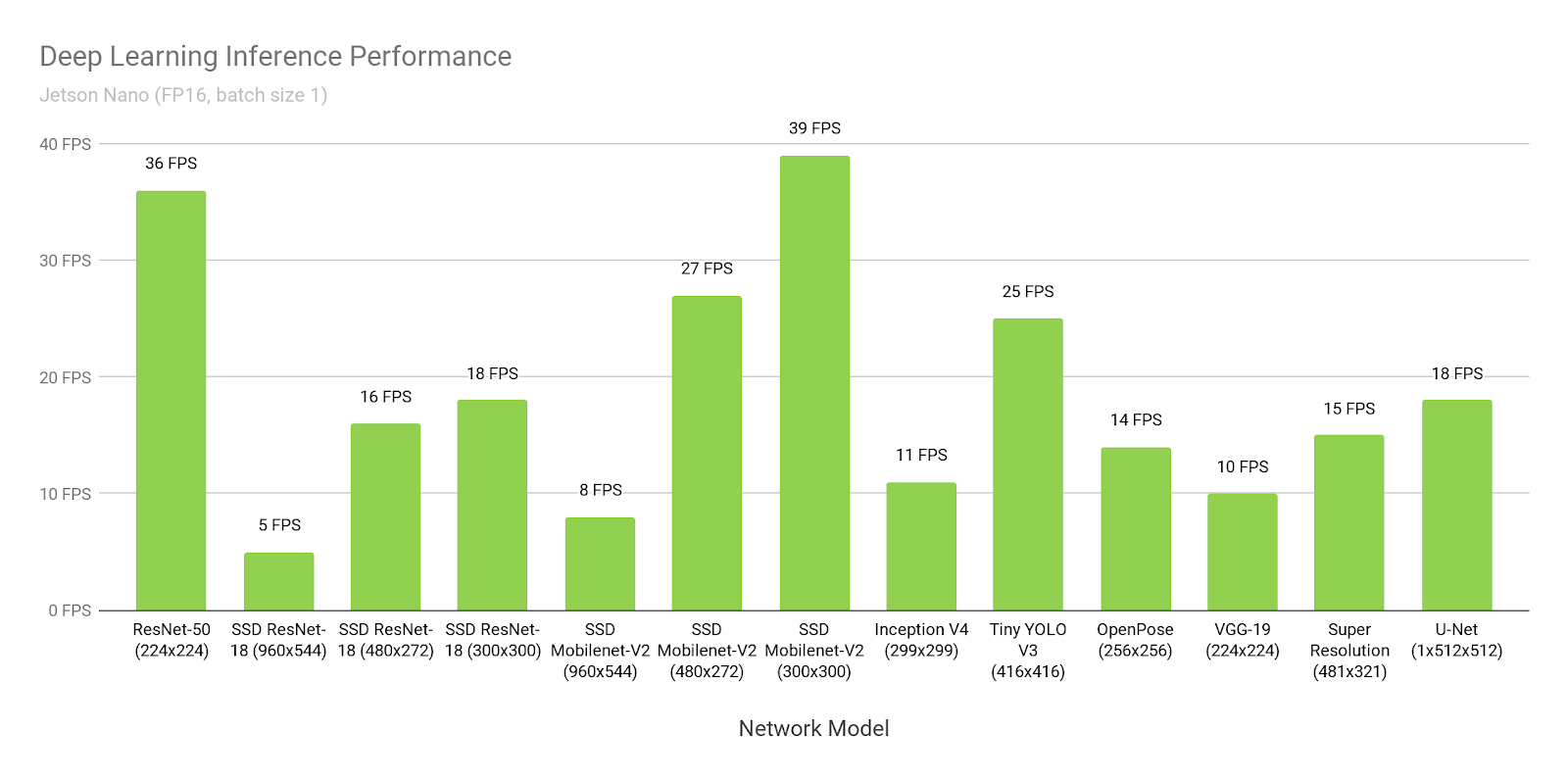
哇,每秒39帧(25毫秒)。 是的,源代码已
布置好 !
嗯...但是为什么要
在这里写约46ms?
等待...在这里,
他们写到309 ms是本机的,移植了72ms ...
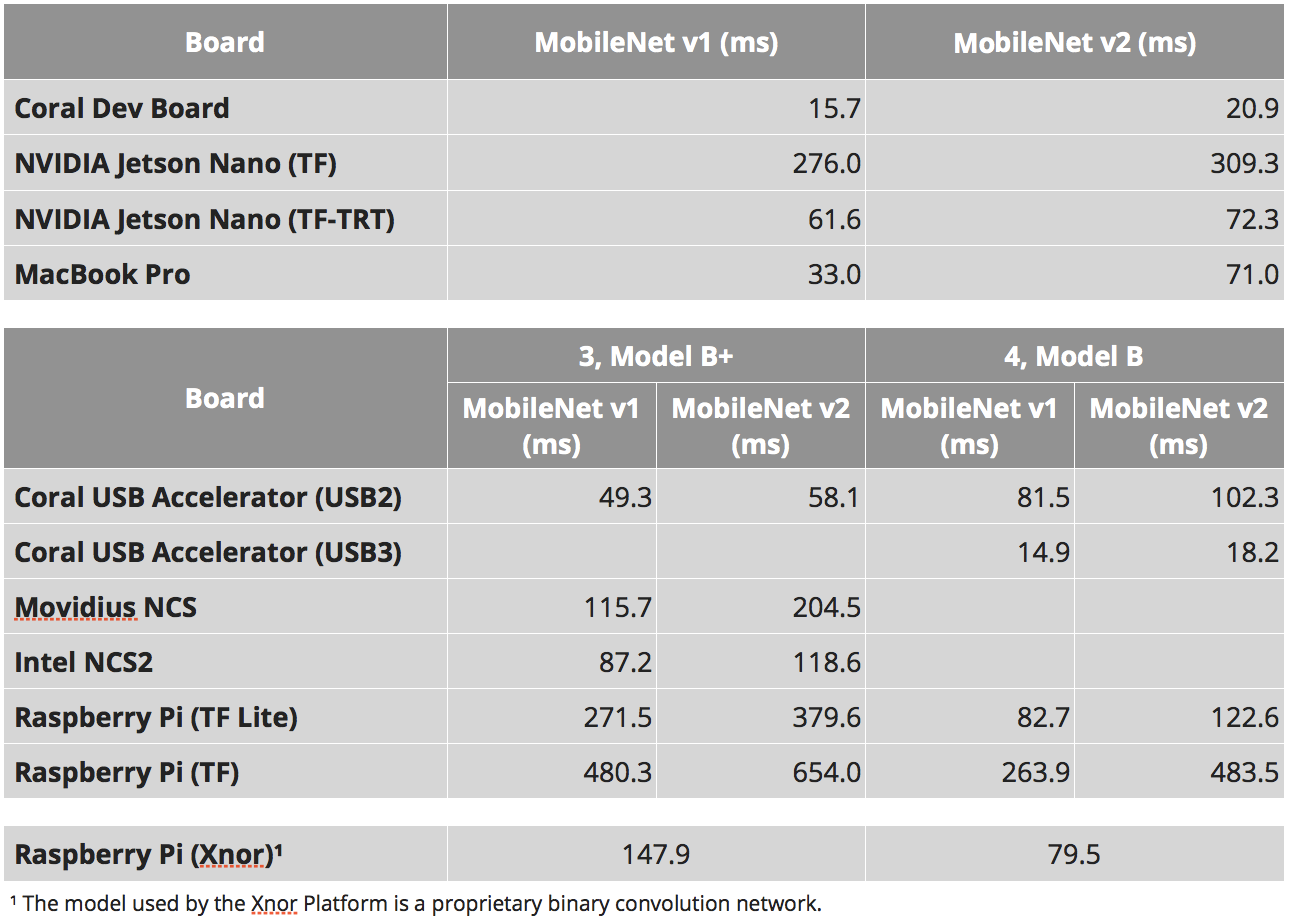
真相在哪里?
事实是,每个人都认为非常不同:
- SSD由两部分组成。 其中一部分是神经元。 第二部分是神经元产生的内容的后处理(非最大抑制)+输入上加载的内容的预处理。
- 如前所述,在Jetson下,所有内容都需要转换为TensorRT。 这是NVIDIA的本机框架。 没有它,一切都会变得糟糕。 只有一个问题。 并非所有内容都已移植到那里,尤其是从TensorFlow移植到那里。 在全球范围内,有两种方法:
- Google意识到这是个问题,因此为TensorFlow发布了一个名为“ tf-trt”的东西。 实际上,这是tf的附加组件,它使您可以将任何网格转换为tensorrt。 不支持的部分在CPU上推断,其余部分在GPU上推断。
- 重写所有图层/查找其类似物
在以上示例中:
- 在此链接中,300毫秒时间是通常的未经优化的张量流。
- 那里,tf-trt版本是72ms。 在那里,所有的nm基本上都在该过程中完成。
- 这是一个风扇版本,一个人转移了所有nm,并亲自写在gpu上。
- 而且……这个NVIDIA决定不进行后处理就测量所有性能,而无需在任何地方明确提及。
您需要自己了解,如果它是您的神经元,在您之前没有人会转换它,那么毫无问题,您将能够以72ms的速度启动它。 并以46毫秒的速度一周一整天地坐在手册和sorsa上。
与许多其他选项相比,这非常好。 但是请不要忘记您所做的一切-永远不要相信NVIDIA的基准!
RaspberryPI 4
生产?..我听到附近有数十位工程师开始嘲笑提到“ RPI”和“生产”两个词。 但是,我不得不说-RPI仍然比Jetson Nano和Google Coral稳定。 但是,当然,TX2丢失了,显然是吉尔法西酮。

(图片
来自这里 。在我看来,将风扇连接到RPi4是一种单独的民间娱乐活动。)
在整个列表中,这是我唯一没有拿过手/未测试的设备。 但是他在Rpi,Rpi2,Rpi3上启动了神经元(例如,他在
这里告诉我)。 一般来说,据我了解,Rpi4仅在性能上有所不同。 在我看来,RPi的优缺点是无所不包的。 缺点:
- 尽我所愿,这不是杂货店解决方案。 过热 。 定期冻结。 但是,由于社区庞大,每个问题都有数百种解决方案。 这不能使Rpi适于数千次打印运行。 但是数十/数百-围笔记。
- 速度 这是我们正在谈论的所有主要设备中最慢的设备。
- 几乎没有制造商的支持。 该产品针对发烧友。
优点:
- 价钱 不,当然,如果您自己繁殖板子,那么使用吉法西酮可以使成千上万个便宜。 但这很可能是不现实的。 RPi性能足以满足需求-这将是最便宜的解决方案。
- 人气。 当Caffe2发行时,基本发行版中有一个Rpi版本。 Tensorflow灯? 当然可以。 I.T.D.,I.T.P. 制造商不做的是转移用户。 我在不同的RPi和Caffe,Tensorflow和PyTorch上运行,还有一些稀有的东西。
- 小型聚会/件的便利。 只需刷新闪存驱动器并运行即可。 不同于JetsonNano,船上有WiFi。 您可以简单地通过PoE为其供电(似乎您需要购买有源出售的适配器)。
最后我们将讨论Rpi速度。 由于制造商并未假定其产品适用于神经元,因此几乎没有基准。 每个人都知道Rpi的速度并不完美。 但是,即使他适合某些任务。
我们在Rpi实施了几个半成品任务。 印象是令人愉快的。
Movidius 2

从这里到下面,不是成熟的处理器,而是专门为神经网络设计的处理器。 好像他们的优点和缺点同时存在。
这样啊 莫维迪乌斯。 该公司于2016年被英特尔收购。 在我们感兴趣的细分市场中,该公司发布了两种产品,Movidius和Movidius2。第二种更快,我们只讨论第二种。
不,不是那样。 对话不应从Movidius开始,而
应从 Intel
OpenVino开始 。 我会说这是意识形态。 更具体地说,框架。 实际上,这是一组经过预训练的神经元及其推断,针对英特尔产品(处理器,GPU,特殊计算机)进行了优化。
与OpenCV集成在一起,与Raspberry Pi集成在一起,并带有许多其他的口哨声和放屁。OpenVino的优点是它具有很多神经元。首先,最著名的探测器。用于识别人,人,数字,字母,姿势等的神经元。 (1,2,3)。并且他们被训练了。不是通过开放数据集,而是通过英特尔自身编译的数据集。他们更大/更多样化,更开放。可以根据您的情况对它们进行重新培训,然后通常可以正常工作。有可能做得更好吗?当然可以例如,我们所做的数字识别工作明显更好。但是我们花了很多年时间来开发它并了解如何使其完美。在这里,您可以开箱即用,这在大多数情况下就足够了。当然,OpenVino有几个问题。网格不会立即出现在此处。如果出现新的情况,则必须等待很长时间。那里的网眼看上去很杂货。您将在此处找不到任何GAN。只有深厚的利益。而且,根据我们的经验,如果您在架构上有一些不同于苛刻标准的技巧,那么很难超越那里的网格。但是这些家伙取代了一些甚至是非常复杂的模型: 在我看来,英特尔及其OpenVino选择了一种非常有趣的策略。他们扮演着不断追赶的角色。但是,一个追赶后传播任何东西的人。届时,当一切都从神经元中挤出来时,英特尔将占领整个市场。现在,您已经可以完成70%的任务,基于OpenVino构建解决方案。作为该策略的一部分,Movidius看起来像是其逻辑上的补充。这是您需要对所有这些财富感兴趣的设备。大多数网格都是为此专门优化的(有时甚至是二进制架构,这也非常快)。在全球范围内,他只有负数。 USB,该死的,不是食物连接器!您无法使用USB制作设备。有一个出路。英特尔销售芯片。甚至类似的东西也在上一代(1,2)似乎上面有产品。但是我还没有看到可以在上面开发产品的单个产品板。而且,没有一家熟悉的中小型公司没有开始基于该芯片进行任何开发。另一方面,坦克会发生什么?..它仍然会追上我们并压垮我们:)哦,是的,很不高兴。据我了解,OpenVino正在俄罗斯下诺夫哥罗德开发(在我看来,Computer Vision的一半是在俄罗斯完成的)。这里谢尔盖讲述了他:(该报告更有可能涉及AI 2.0,但有关OpenVino的内容很多)。好的,他们已经讲了几乎所有内容。Movidius 2的简短摘录。缺点:
在我看来,英特尔及其OpenVino选择了一种非常有趣的策略。他们扮演着不断追赶的角色。但是,一个追赶后传播任何东西的人。届时,当一切都从神经元中挤出来时,英特尔将占领整个市场。现在,您已经可以完成70%的任务,基于OpenVino构建解决方案。作为该策略的一部分,Movidius看起来像是其逻辑上的补充。这是您需要对所有这些财富感兴趣的设备。大多数网格都是为此专门优化的(有时甚至是二进制架构,这也非常快)。在全球范围内,他只有负数。 USB,该死的,不是食物连接器!您无法使用USB制作设备。有一个出路。英特尔销售芯片。甚至类似的东西也在上一代(1,2)似乎上面有产品。但是我还没有看到可以在上面开发产品的单个产品板。而且,没有一家熟悉的中小型公司没有开始基于该芯片进行任何开发。另一方面,坦克会发生什么?..它仍然会追上我们并压垮我们:)哦,是的,很不高兴。据我了解,OpenVino正在俄罗斯下诺夫哥罗德开发(在我看来,Computer Vision的一半是在俄罗斯完成的)。这里谢尔盖讲述了他:(该报告更有可能涉及AI 2.0,但有关OpenVino的内容很多)。好的,他们已经讲了几乎所有内容。Movidius 2的简短摘录。缺点:- . Rpi Jetson Nano. — . . Third Party ?
- . . .
- . .
- . USB 3.0
- , . -. . Movidius . .
优点:
- . . .
- 低功耗,不会过热
- 我听说很好的支持
我们自己没有在任何项目中使用它。我们所有测试了推理任务的朋友-结果,他们没有将它投入生产。但是我建议一些公司,他们的任务是“我们需要将20-30台摄像机置于障碍之中,但我们不想购买任何东西,我们会自己开发它” –看来他们最终还是选择了Movidius。英特尔最近宣布了一个新平台。但是,到目前为止,还没有详细的信息。 UPD他们为此发送了一个链接。费两秒钟。这是一种嵌入式格式。许多人为此使用PCI-e总线。这样的事情只是价格问题。两个movidius-这样的东西不太可能比$ 200便宜 成本。而且您还需要在系统中使用自己的主板...
UPD他们为此发送了一个链接。费两秒钟。这是一种嵌入式格式。许多人为此使用PCI-e总线。这样的事情只是价格问题。两个movidius-这样的东西不太可能比$ 200便宜 成本。而且您还需要在系统中使用自己的主板...谷歌珊瑚
我很失望 不,没有什么我无法预料的。 但我对Google决定发布此版本感到失望。 在夏季初,测试是一个奇迹。 从那时起也许有些变化,但是我将描述我当时的经历。
设置...要使Jetson Tk-Tx1-Tx2闪烁,必须将其插入主机和电源。 这就足够了。 要刷新Jetson Nano和RPi,只需将图像推入USB闪存驱动器。
而要闪烁珊瑚,您需要按照
正确的顺序粘贴三根电线:

并且不要尝试犯错! 顺便说一下,指南中存在错误/难以描述的行为。 也许我不会描述它们,因为从夏天开始他们可能已经修复了某些东西。 我记得在安装Mendel之后,所有通过ssh的访问都丢失了,包括他们描述的访问,我不得不手动编辑一些Linux配置。
我花了2-3个小时来完成此过程。
好啦 推出了。 您认为在其上运行网格很容易吗? 几乎没有:)
这是您可以放手
的清单。
老实说,我并没有很快达到这一点。 花了半天。 真的不行 您无法从
TF存储库下载模型并在设备上运行。 或者有必要横切所有图层。 我没有找到指示。
所以在这里。 有必要从上方从存储库中获取模型。 它们并不多(自夏季开始以来已添加了3个模型)。 以及如何训练她? 在TensorFlow中以标准管道打开吗? 哈哈哈哈哈哈哈哈。 当然不是!
您有一个特殊的
Doker容器 ,模型只会在其中训练。 (也许,您也可以以某种方式模拟您的TF。但是有些说明,说明……似乎并非如此。)
下载/安装/启动。 这是什么...为什么GPU为零?..因为培训将在CPU上进行。 Docker只适合他! 想要更多乐趣吗? 该手册说:“基于带有64G内存工作站的6核CPU”。 看来这只是建议? 也许吧 直到现在,在大多数模型训练的服务器上,我的8场演出还不够。 在第4个小时的训练中,他们全部消耗consumed尽。 强烈感觉到他们有流动的东西。 我在不同的机器上尝试了几天,使用不同的参数,结果却是一个。
在发布文章之前,我没有对此进行仔细检查。 老实说,对我来说一次就足够了。
还有什么要补充的? 这段代码不会生成模型吗? 要生成它,您必须:
- 滞后计数
- 将他转换为tflite
- 编译为Formal Edge TPU。 感谢上帝,这是在计算机上完成的。 在春季,只能在线进行。 并且必须打勾“我不会将其用于邪恶/我不会违反此模型的任何法律”。 现在,感谢上帝,这一切都没有。

这是我去年对IT产品感到的最大厌恶...
在全球范围内,Coral应该与Movidius的OpenVino具有相同的意识形态。 直到现在,英特尔一直在这条道路上走了几年。 拥有出色的手册,支持和优质的产品……还有Google。 好吧,那只是Google ...
缺点:
- 在AD级别,该委员会不是杂货店。 我还没有听说过芯片销售=>生产不现实
- 发展水平是可怕的。 一切都好。 开发流程不适合传统方案。
- 风扇 他们将其放在“能量最佳的芯片”上。 好的,我不再谈论生产了。
- 费用。 比TX2最昂贵。
- 两个网格不能同时保存在内存中。 必须执行上载下载。 这减慢了几个网络的推理。
优点:
- 在我们所说的所有事情中,珊瑚是最快的
- 如果将芯片提起,则可能比Movidius生产率更高。 而且似乎其结构对于神经元更合理。
吉尔法肯

最近一年半一直在谈论这种中国野兽。 甚至在
一年前,我
还在谈论他。 但是说话是一回事,而提供信息则是另一回事。 我与3-4家大公司进行了交谈,项目经理/总监告诉我这个Girfalkon有多酷。 但是他们没有任何文档。 他们没有看到他活着。 该
站点几乎没有信息。 从网站
下载至少某些东西只能成为合作伙伴(硬件开发人员)。 而且,该网站上的信息非常矛盾。 在一个地方,他们写道他们只支持
VGG ,在另一个地方,他们只说他们的神经元是基于GNet的(根据
他们的保证, GNet非常小,而且确实没有准确性的损失)。 在第三篇中,所有内容都是用TF | Caffe | PyTorch进行转换的,而第四篇中则是关于手机和其他魅力的。
了解真相几乎是不可能的。 一旦我挖掘并挖掘了一些至少有一些失误的视频:
如果这是真的,则意味着SSD(在移动设备上)在GTI2801芯片上的224 * 224以下时具有〜60ms,这与movidius相当。
看来他们的芯片2803快得多,但是有关它的信息却更少:
今年夏天,我们从萤火虫手中得到了一块
木板 (
此模块已安装在此处用于计算)。
希望最终我们能活着。 但是没有成功。 该板是可见的,但是没有用。 他们翻阅中文文档中的单个英语短语,甚至几乎了解了问题所在(最初的滚花系统不支持神经模块,必须自己重建并重新滚动所有内容)。 但是它并没有解决问题,并且已经怀疑该板子不能满足我们的任务(2GB的RAM对于神经网络+系统来说非常小。此外,没有同时支持两个网络)。
但是我设法看到了原始文档。 从中,了解得很少(中文)。 为了良好起见,有必要进行测试并查看源代码。
RockChip技术支持的得分愚蠢到我们。
尽管有这种恐怖,但我很清楚,这里同样是RockChip的门框。 我希望在正常的董事会中使用Gyrfalcon。 但是由于缺乏信息,我很难说。
缺点:
- 没有公开销售,仅与公司互动
- 信息很少,没有社区。 现有信息通常是中文。 平台功能无法预先预测
- 推断很可能一次不超过一个网络。
- 只有铁的制造商才能与旋翼飞机本身进行交互。 其余的需要寻找一些中介/板的制造商。
优点:
- 据我了解,gilfcon芯片的价格比其他芯片便宜得多。 即使采用闪存驱动器的形式。
- 已经有带有集成芯片的第三方设备。 因此,发展比Movidius容易一些。
- 他们保证有许多预先训练的网格,网格的转移比Movidius | Coral容易得多。 但是我不能保证这是事实。 我们没有成功。
简而言之,结论是:很少的信息。 您不仅可以躺在这个平台上。 而且,在对它进行操作之前,您需要进行大量审核。
速度
我真的很喜欢90%的嵌入式设备比较如何减少比较速度。 如上所述,此特征非常随意。 对于Jetson Nano,您可以将神经元作为纯tensorflow运行,可以使用tensorflow-tensorrt,也可以使用纯tensorrt。 具有特殊张量架构的设备(movidius | Coral | Gyrfalcone)-可能很快,但首先它们只能与标准架构一起使用。 即使对于Raspberry Pi,一切也不是那么简单。 来自
xnor.ai的神经元提供了一个半倍的加速度。 但是我不知道他们有多诚实,切换到int8或其他玩笑中获得了什么。
同时,另一个有趣的时刻是这样的时刻。 神经元越复杂,用于推理的设备就越复杂-最终拉出的加速度就越不可预测。 采取一些OpenPose。 有一个不平凡的网络,复杂的后处理。 由于以下原因,可以对此进行优化:
- GPU后处理迁移
- 优化后处理
- 针对平台功能的神经网络优化,例如:
- 移植到int8 | int16 |二值化
- 使用多个计算器(GPU | CPU |等)。 我记得在Jetson TX1上,当我们为此目的将与视频流相关的所有功能转移到内置加速器时,我们曾经加速得很好。 Trite,但是网络加速了。 保持平衡时,会弹出很多有趣的组合
有时,某人尝试为所有可能的组合评估某物。 但实际上,就我看来,这是徒劳的。 首先,您需要确定平台,然后再尝试完全提取所有可能的东西。
为什么我这一切。 此外,“
MobileNet多长时间 ”测试是一个非常糟糕的测试。 他可以说平台X是最佳的。 但是,当您尝试将神经元部署到那里并进行后处理时,您可能会非常失望。
但是比较mobilnet'ov仍然可以提供有关该平台的一些信息。 对于简单的任务。 对于您了解的情况,无论如何,将任务简化为标准方法更容易。 当您要评估计算器的速度时。
下表摘自以下几个地方:
- 这些研究是: 1,2,3
- 对于SSD,有这样一个参数“输出类别数”。 并且从该参数可以推断出很大的变化率。 我试图选择班数相同的研究。 但是,并非到处都是这样。
- 我们在TensorRT方面的经验。 我知道哪些工作不分工。
- 对于gyrfalcon,这些视频基于mobilnet v2的存在+区域更改成本估算的事实。 该视频说2803可以快3-4倍。 但是对于2803,没有SSD额定值。 总的来说,我最怀疑此时的速度。
- 我试图选择给出真正最大速度的研究(例如,没有NMS的我就没有Nvidia版本)
- 对于Jetson TX2,我使用了这些等级,但是有5个班级,在相同数量的班级上,其他班级会变慢。 我以某种方式从经验/与Nano内核的比较中找出了应该存在的内容
- 我没有考虑笑话的比特率。 我不知道Movidius和Gyrfalcon所做的工作是什么。
结果,我们有:

平台比较
我将尝试将我上面所说的所有内容放到一张桌子上。 我用黄色突出显示了我的知识不足以得出明确结论的那些地方。 而且实际上是1-6-这是对平台的一些比较评估。 越接近1,越好。

我知道能源消耗对许多人至关重要。 但是在我看来,这里的所有内容都有些模棱两可,而且我对此理解得太差了,因此我没有输入。 而且,意识形态本身似乎到处都是相同的。
侧步
我们所说的只是您系统的巨大变化空间中的一小部分。 可能是该区域特征的常用词:
但是,在全球范围内,如果降低其中一项条件的重要性,则可以将许多其他设备添加到列表中。 下面,我将介绍我所遇到的所有方法。
英特尔
正如我们在讨论Movidius时所说的那样,英特尔具有OpenVino平台。 它允许在英特尔处理器上非常有效地处理神经元。 此外,该平台还允许您在芯片上甚至支持各种intel-gpu。 我现在害怕确切地说出什么任务有什么样的表现。 但是,据我所知,一块配备GPU的好石头可以提供1080的性能。 对于某些任务,它甚至可以更快。

在这种情况下,外形尺寸(例如Intel NUC)非常紧凑。 良好的散热,包装等 速度将比Jetson TX2快。 通过可用性/易于购买-更容易。 开箱即用的平台的稳定性更高。
两个缺点-功耗和价格。 开发要复杂一些。
Jetson AGX

这是另一个杰森。 本质上是最旧的版本。 速度比Jetson TX2快2倍,而且还支持int8计算,这使您可以再超频4倍。 顺便问一下,从Nvidia上看这张
照片 :
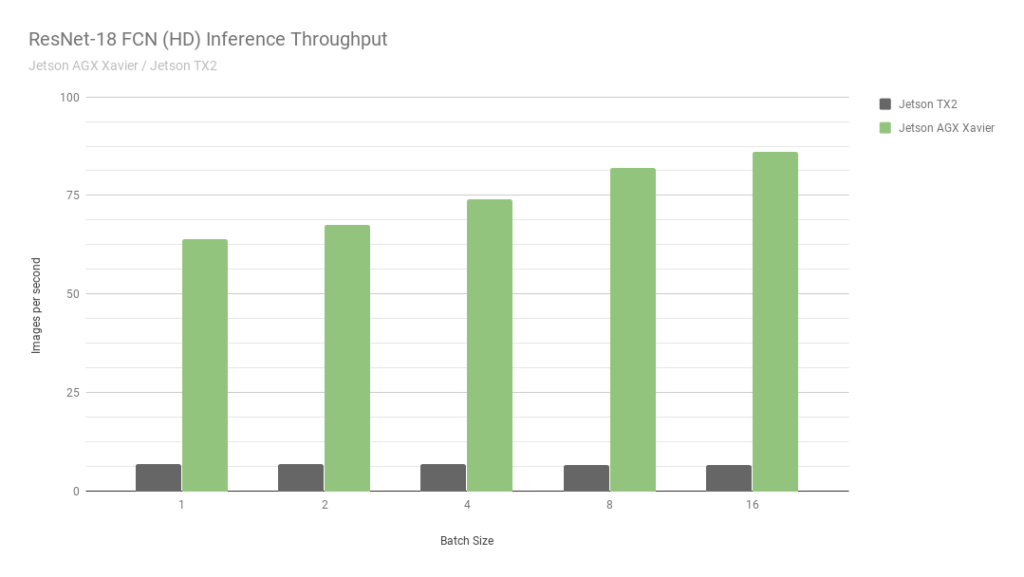
他们比较自己的两个杰森。 int8中的一个,int32中的第二个。 我什至不知道该说些什么……总之:“永不相信NVIDIA GRAPHICS”。
尽管事实证明AGX很好-就计算能力而言,它还不能达到Nvidia的普通GPU。 不过,就能源效率而言-它们非常酷。 主要减去价格。
我们自己没有与他们合作,因此我很难说得更详细些,以描述最适合他们的任务范围。
Nvidia GPU | 笔记本电脑版
如果您取消了对功耗的严格限制,则Jetson TX2看起来并不是最佳选择。 像AGX。 通常,人们不怕在生产中使用GPU。 所有这些都需要单独付款。
但是,有数以百万计的公司为您提供在一个板上组装定制解决方案的方法。 通常,这些是笔记本电脑/小型计算机的主板。 或者,最后,像
这样 :

我在过去2.5年中一直工作的初创公司之一(
CherryHome )
就走了这条路。 我们非常满意。
像往常一样,在能源消耗上减去负数,这对我们而言并不重要。 好吧,价格有点咬。
手机
我不想深入探讨这个话题。 要说出现代手机中用于神经元的所有信息/哪些框架/哪种硬件等,您将需要不止一篇如此大小的文章。 考虑到我们朝这个方向戳了2-3次这一事实,我认为自己对此无能为力。 因此,请注意以下几点:
- 有许多可以优化神经元的硬件加速器。
- 没有普遍适用的解决方案。 现在有一些尝试使Tensorflow lite这样的解决方案。 但是,据我了解,它尚未成为一体。
- 一些制造商有自己的特色农庄。 一年前,我们帮助优化了Snapdragon的框架。 这太可怕了。 那里的神经元质量比我今天谈论的一切都低得多。 不支持90%的层,即使是基本层(如“添加”)也是如此。
- 由于没有python,网络的推论非常奇怪,不合逻辑且不便。
- 在性能方面,碰巧一切都很好(例如,在某些iPhone上)。
在我看来,对于嵌入式手机而言,这并不是最佳解决方案(某些低成本的人脸识别系统除外)。 但是我看到了一些将它们用作早期原型的情况。
间隙8
最近在
Usedata会议上。 其中一份报告涉及以最低的百分比(GAP8)推断神经元。 而且,正如他们所说,对发明的需求非常狡猾。 在故事中,一个例子牵强附会。 但是作者告诉了他们如何能够在大约一秒钟内通过面子推理。 在非常简单的网格上,基本上没有检测器。 通过疯狂和长期的优化并节省了比赛费用。
我总是不喜欢这样的任务。 没有研究,只有血液。
但是,值得认识的是,我能想象出一些难题,即低消耗百分比会带来很酷的效果。 可能不是用于面部识别。 但是在5-10秒内您可以识别输入图像的地方...
格罗夫AI HAT

在准备本文时,我遇到了
这个嵌入式平台。 关于它的信息很少。 据我了解,零支持。 生产率也为零...而速度没有一次测试...
服务器/远程识别
每当他们在嵌入式平台上向我们寻求建议时,我都想大喊“奔跑,你这笨蛋!”。 有必要仔细评估对这种解决方案的需求。 查看其他选项。 我总是建议大家使用服务器体系结构进行原型设计。 在操作过程中,由您决定是否实施真正的嵌入式。 毕竟,嵌入式是:
- 增加的开发时间,通常是2-3倍。
- 生产中的完善支持和调试。 ML的任何发展都是不断的修订,神经元的更新,系统更新。 嵌入式仍然更加困难。 如何重新加载固件? 而且,如果您已经可以访问所有单位,那么当您可以在一台设备上进行计算时,为什么要对它们进行计算呢?
- 系统复杂性/风险增加。 更多的故障点。 同时,尽管该系统无法整体运行,但可能无法理解:该平台是否适合此任务?
- 价格上涨。 放置像nano pi这样的简单板是一回事。 另一种是购买TX2。
是的,我知道有些任务无法做出服务器决策。 但是,奇怪的是,它们比通常认为的要小得多。
结论
在本文中,我尝试没有明显的结论。 这是一个关于现在的故事。 得出结论-有必要对每种情况进行调查。 不仅是平台。 但是任务本身。 在设备下,任何任务都可以略微简化/略微修改/略微锐化。
该主题的问题是主题正在更改。 新设备/框架/方法即将到来。 例如,如果NVIDIA明天开启对Jetson Nano的int8支持,情况将发生巨大变化。 当我写这篇文章时-我不确定两天前信息没有改变。 但我希望我的短篇小说能帮助您更好地导航下一个项目。
如果您有其他信息/我错过了一些事情/说错了什么,那就太好了-在此处写详细信息。
ps
即使我几乎完成了这篇文章的撰写,
snakers4仍在他的电报频道Spark中删除了我最近的
帖子 ,这与Jetson的问题差不多。 但是,如上所述,在任何功耗的情况下,我都会使用zotacs或IntelNUC之类的东西。 而且作为嵌入式jetson并不是最糟糕的平台。
