大约一年前,我和我的同事被分配使用流行的网络基础架构监视系统-Zabbix进行整理。 在研究了文档之后,我们立即进行了负载测试:我们想要评估Zabbix可以工作多少个参数而不会出现明显的性能下降。 只有PostgreSQL被用作DBMS。
在测试过程中,确定了数据库布局的某些体系结构功能以及监视系统本身的行为,默认情况下,这些功能不允许监视系统达到其最大功能。 结果,主要在调优数据库方面开发,实施和测试了一些优化措施。
我想分享本文完成的工作的结果。 本文对于Zabbix和PostgreSQL DBA管理员以及想要更好地了解和理解流行的PosgreSQL DBMS的每个人都将很有用。
小型破坏器:在每分钟负载20万个参数的弱机器上,我们设法将CPU iowait从20%减少到2%,将对主数据表的记录时间减少了250倍,对汇总数据表的记录时间减少了32倍,减小了索引的大小5-10倍,并在某些情况下将历史样品的接收速度提高了18倍。
负载测试
根据该方案进行了负载测试:一台Zabbix服务器,一台活动Zabbix代理,两个代理。 每个代理配置为每分钟提供50吨整数和50吨字符串参数(每分钟总共200吨参数或每秒3333个参数)。 为了生成代理参数,我们使用了
Zabbix插件,要检查一个代理可以生成多少参数,您需要使用
来自同一插件作者zabbix_module_stress的
特殊脚本 。 Zabbix Web管理员在注册大型模板时遇到困难,因此我们将参数分为5个参数(2500个数字和2500个字符串)的20个模板。
用于python中的负载测试的脚本生成器模板import argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
cpu iostat指标很好地指示了Zabbix的性能-它反映了处理器等待磁盘访问的时间单位的分数。 数值越高,磁盘上的读写操作就越多,这将间接影响整个监视系统的性能下降。 即 这肯定是监控出现问题的迹象。 顺便说一下,在网络的开放空间上,一个比较普遍的问题是“如何在Zabbix中删除iostat触发器”,所以这很麻烦,因为有很多原因会增加iowait指标的值。
这是最初三天后获得的cpu iowait指标的图片:
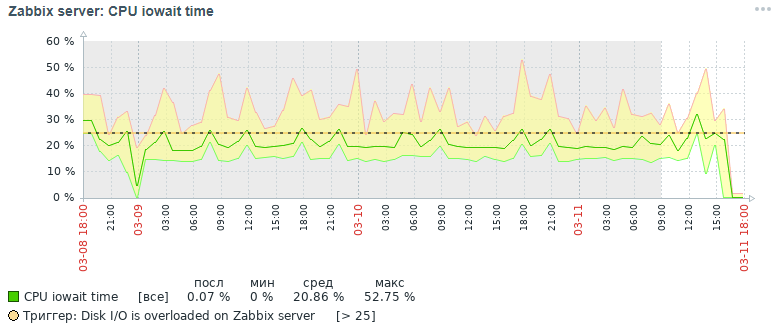
但是,在完成所有优化措施之后,我们在三天之内也获得了相同指标的结果,下面将对此进行讨论:
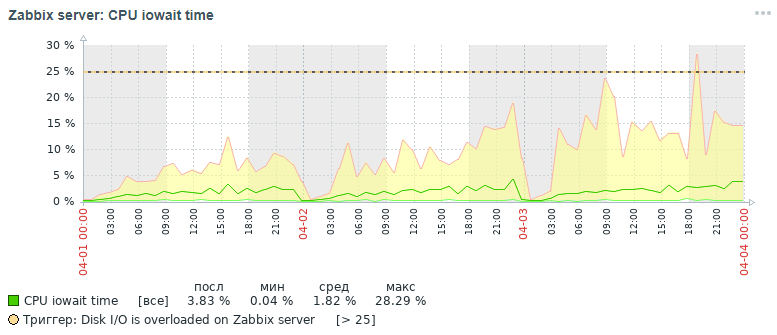
从图中可以看出,cpu iowait指标从几乎20%下降到2%,从而间接地加快了所有添加和读取数据请求的执行时间。 现在让我们看看为什么使用标准数据库设置,监视系统的整体性能下降以及如何对其进行修复。
Zabbix性能下降的原因
由于在每个主数据表中累积了超过1000万个参数值,因此注意到监视系统的性能急剧下降,原因如下:
- 服务器CPU的iowait指标增加了20%以上,这表明CPU期望访问磁盘读写操作的时间增加了
- 监视数据大大膨胀的表的索引
- 对于具有监视数据的磁盘,利用率指标提高到100%,这表明磁盘具有读和写操作的满负载
- 根据管家的时间表进行清理时,过时的值没有时间从历史记录表中删除
这种情况在每个小时的开始都会加剧,此外,还要计算每小时的汇总统计信息-在主动从磁盘读取和写入索引页,从历史记录中删除过时的数据时,导致相同的结果-数据库性能下降和执行时间增加请求(在限制中,记录了最多5分钟的请求!)。
在Zabbix中组织监视数据仓库的一点帮助。 此外,它将参数类型分开存储在不同表中的主数据和聚合数据。 每个表存储一个itemid字段(对系统中已注册数据项的隐式引用),用于以unix时间戳格式注册时钟值的时间戳记(在单独的列中以毫秒为单位)和在单独的列中的值(日志表除外,它具有更多字段-与事件日志类似) ):
优化活动
为了提高PostgreSQL数据库的性能,已进行了各种优化措施,主要是分区和更改索引。 但是,值得一提的是一些重要和有用的措施,这些措施可以加快PostgreSQL数据库管理系统下任何数据库的工作。
重要说明。 在收集本文的资料时,我们使用了Zabbix 4.0版,尽管已经发布了4.2版并且正在准备发布4.4版。 为什么提到这一点很重要? 因为从版本4.2开始,Zabbix开始支持用于TimescaleDB时间序列的特殊强大扩展,但到目前为止仍处于实验模式:使用该扩展的所有优势,人们认为某些请求开始运行得更慢,并且仍然存在无法解决的性能问题(已在4.4版中解决)-
阅读本文 。
在下一篇文章中,我打算与该解决方案案例进行比较,介绍已经使用TimescaleDB扩展进行负载测试的结果。 PostgreSQL版本使用10,但是给出的所有信息都与11和12版本有关(我们正在等待!)。
因此,首先要注意的是:
- 使用pgtune实用程序设置配置文件
- 将数据库放在单独的物理磁盘上
- 用pg_pathman分区历史表
- 将历史记录表的索引类型更改为brin(时钟)和btree-gin(itemid)
- 查询执行统计信息pg_stat_statements的收集和分析
- 设置物理磁盘监视参数
- 硬件性能提升
- 创建分布式集群(超出本文范围的内容)
使用pgtune实用程序配置配置文件
实际上,PostgreSQL是一个相当轻量级的DBMS。 它的默认配置文件已配置为,正如我的同事所说,“甚至可以在咖啡机上工作”,即 用非常适中的铁。 因此,有必要为服务器配置配置PostgreSQL,同时考虑内存量,处理器数量,数据库的预期使用类型,磁盘类型(HDD或SSD)和连接数量。
las,没有一个单一的公式可以调整所有DBMS,但是有一些适用于大多数配置的规则和模式(更精确的调整已经是专家的工作)。 为了简化DBA的工作,编写了
pgtune实用程序,并在
网络版本上添加了
le0pard ,这是一本有趣且有用的PostgreSQL管理书籍的作者。
在具有100个连接(Zabbix具有要求的Web管理员)的控制台中针对“数据仓库”应用程序类型运行实用程序的示例:
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
pgtune实用程序随目的描述而更改的配置参数(以示例值给出) #DB版本:11
#操作系统类型:linux
#DB类型:web
#总内存(RAM):8 GB
#CPU数量:1
#连接数:100
#数据存储:硬盘
max_connections = 100#最大并发数据库连接数
shared_buffers = 2GB#共享内存中各种缓冲区(主要是表块和索引块的缓存)的内存大小
effective_cache_size = 6GB#使用索引执行查询所需的最大内存大小
maintenance_work_mem = 512MB#影响操作速度VACUUM,ANALYZE和CREATE INDEX
checkpoint_completion_target = 0.7#完成检查点程序的目标时间
wal_buffers = 16MB#共享内存用于维护事务日志的内存量
default_statistics_target = 100#ANALYZE命令收集的统计信息的数量-当增加时,优化器生成查询的速度会变慢,但会更好
random_page_cost = 4#索引访问数据页的条件开销-影响使用索引的决策
effective_io_concurrency = 2#DBMS将在单独的会话中尝试执行的异步I / O操作数
work_mem = 10485kB#在磁盘上使用临时文件之前用于排序和哈希表的内存量
min_wal_size = 1GB#限制在WAL文件数量以下,将被回收以备将来使用
max_wal_size = 2GB#限制将被回收以供将来使用的WAL文件的数量
一些有用的postgresql配置选项 #管理并发请求处理程序
max_worker_processes = 8#后台进程的最大数量-每个数据库至少一个
max_parallel_workers_per_gather = 4#单个请求中的最大并行进程数
max_parallel_workers = 8#系统可以支持并行操作的最大工作流程数
#日志记录设置(一种无需使用pg_stat_statements扩展即可了解请求执行时间的简便方法)
log_min_duration_statement = 3000#将所有操作时间> =指定值(以毫秒为单位)的命令的执行持续时间写入日志
log_duration = off#记录每个已完成命令的持续时间
log_statement ='none'#将哪个SQL命令写入日志,值:无(禁用),ddl,mod和全部(所有命令)
debug_print_plan = off#查询计划树的输出以供进一步分析
#将最大值从数据库中挤出,并准备好在发生任何故障时获取它(对于最压抑的人,他们忽略了ssd和分布式集群的存在)
#fsync = off#物理写入更改磁盘,禁用fsync可提高速度,但可能导致永久性故障
#synchronous_commit = off#允许您甚至在事务信息进入WAL之前就响应客户端-禁用fsync几乎是安全的选择
#full_page_writes = off#关机可加快正常操作的速度,但如果系统崩溃,则可能导致数据损坏或数据损坏
在单独的物理磁盘上列出数据库
该项目是可选的,而是对成熟的分布式集群的过渡解决方案,但是了解这种可能性将很有用。 为了加速数据库,您可以将其放在单独的磁盘上。 我们将整个磁盘安装在存储所有PostgreSQL数据库的基本目录中,但是通常可以以不同的方式进行操作:创建一个新的表库并将数据库(或者甚至是数据库的一部分-主要和汇总监视数据的表)转移到该表库中的单独磁盘上。
挂载示例首先,您需要使用ext4文件系统格式化磁盘并将其连接到服务器。 使用noatime标签挂载数据库磁盘:
挂载/ dev / sdc1 / var / lib / pgsql / 10 /数据/ base -o noatime
要进行永久安装,请将该行添加到/ etc / fstab文件中:
#其中UUID是磁盘的标识符,您可以使用blkid实用程序查看它
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 /数据/基本ext4默认值,noatime 0 0
用pg_pathman对历史表进行分区
我们在Zabbix压力测试期间遇到的问题之一-PostgreSQL无法从数据库中删除过时的数据。 使用分区,您可以将表拆分为其组成部分,从而减小超级表的索引和组成部分的大小,从而对整个数据库的速度产生积极影响。
分区可以立即解决两个问题:
1.通过删除整个表来加速过时数据的删除
2.分割每个组合表的索引
PostgreSQL中有四种分区机制:
1.标准constraint_exclusion
2.扩展pg_partman(
不要与pg_pathman混淆 )
3.扩展
pg_pathman4.手动手动创建和维护分区
我们认为,最方便,可靠和优化的分区解决方案是
pg_pathman扩展。 使用这种分区方法,查询计划者可以灵活地确定要在哪个分区中搜索数据。
有传言说,在PostgreSQL的第12版中,将会有一个出色的分区。因此,我们开始将每天的监视数据写入与父表不同的继承表中,并且通过立即删除所有过时的表开始删除过时的参数值,这对于DBMS来说更容易获得人工成本。 删除是通过在凌晨2点通过调用数据库用户功能作为Zabbix服务器的监视参数来完成的,并指示统计信息存储的可接受范围。
安装和配置PostgreSQL 10的分区从标准操作系统存储库安装和配置
pg_pathman扩展(有关从源代码构建扩展的最新版本的说明,请在github上的同一存储库中查找):
百胜安装pg_pathman10
纳米/var/pgsqldb/postgresql.conf
shared_preload_libraries ='pg_pathman'#重要-这里将pg_pathman写在列表的最后
我们重新启动DBMS,为数据库创建扩展名并配置分区(主监视数据为1天,聚合监视数据为3天-可以完成1天):
systemctl重新启动postgresql-10.service
psql -d zabbix -U postgres
创建扩展pg_pathman;
#为主要监视数据表配置一天
#1552424400-以unix时间戳记的倒数,86400-天数秒
选择create_range_partitions('history','clock',1552424400,86400);
选择create_range_partitions('history_uint','clock',1552424400,86400);
选择create_range_partitions('history_text','clock',1552424400,86400);
选择create_range_partitions('history_str','clock',1552424400,86400);
选择create_range_partitions('history_log','clock',1552424400,86400);
#配置三天的汇总监视数据表
#1552424400-以unix时间戳记的倒数,259200-三天内的秒数
选择create_range_partitions('trends','clock',1545771600,259200);
选择create_range_partitions('trends_uint','clock',1545771600,259200);
如果任何表中都没有数据,则在调用create_range_partitions函数时,必须再传递一个附加参数p_count = 0_。用于监视和管理分区的有用查询:
#分区表的一般列表,主要配置存储:
从pathman_config中选择*;
#表示所有现有节及其父级和范围边界:
从pathman_partition_list中选择*;
#覆盖标准pg_pathman行为的其他参数:
从pathman_config_params中选择*;
#将内容复制回父表并删除分区:
选择drop_partitions('table_name':: regclass,false);
查看分区数量和大小的统计信息的有用脚本:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
自动调整删除过时的分区(ahtung-一个很大的SQL函数)要配置分区的自动删除,您需要在数据库中创建一个函数
(宽文本,因此我必须删除语法高亮显示):
创建或替换功能public.delete_old_partitions(history_days整数,trends_days整数,str_days整数)
返回文字
语言plpgsql
AS $功能$
/ *
该函数删除所有早于指定天数的分区:
history_days-用于分区history_x,history_uint_x
Trends_days-对于趋势趋势_x,趋势趋势_uint_x分区
str_days-用于分区history_str_x,history_text_x,history_log_x
* /
声明clock_today_start int;
声明clock_delete_less_history int = 0;
声明clock_delete_less_trends int = 0;
声明clock_delete_less_strings int = 0;
clock_delete_less int = 0;
声明迭代器int = 0;
声明result_str text ='';
声明buf_table_size文本;
声明buf_table_len文本;
声明partition_name文本;
声明clock_max文本;
声明err_detail文本;
声明t_start timestamp = clock_timestamp();
声明t_end时间戳;
开始
如果$ 1 <= 0,则返回'ups,出了点问题:history_days参数必须为正整数值'; 如果结束
如果$ 2 <= 0,则返回'ups,出了点问题:trends_days参数必须为正整数值'; 如果结束
如果$ 3 <= 0,则返回'ups,出了点问题:str_days参数必须为正整数值'; 如果结束
clock_today_start =提取(date_trunc的纪元('day',现在())):: int;
clock_delete_less_history =提取(date_trunc('day',now())中的时期-($ 1 :: text ||'days'):: interval):: int;
clock_delete_less_trends =提取(date_trunc('day',now())中的纪元-($ 2 ::文本||'days')::间隔):: int;
clock_delete_less_strings =提取(date_trunc('day',now())中的时期-($ 3 ::文本||'days')::间隔):: int;
clock_delete_less =最少(clock_delete_less_history,clock_delete_less_trends,clock_delete_less_strings);
-提高通知'clock_today_start%(%)',to_timestamp(clock_today_start),clock_today_start;
-提高通知'clock_delete_less_history%(%)%天',to_timestamp(clock_delete_less_history),clock_delete_less_history,$ 1;
-提高通知'clock_delete_less_trends%(%)%days',to_timestamp(clock_delete_less_trends),clock_delete_less_trends,$ 2;
-提高通知'clock_delete_less_strings%(%)%days',to_timestamp(clock_delete_less_strings),clock_delete_less_strings,$ 3;
对于partition_name,在选择分区中为clock_max,在pathman_partition_list中为range_max,其中
range_max :: int <=最大值(clock_delete_less_history,clock_delete_less_trends,clock_delete_less_strings)和
(分区::文本(如“历史%”)或分区::文本(如“趋势%”))按分区升序排列
循环
如果(partition_name〜'history_uint_ \ d'和clock_max :: int <= clock_delete_less_history)
或(partition_name〜'history_ \ d'和clock_max :: int <= clock_delete_less_history)
或(partition_name〜'trends_ \ d'and clock_max :: int <= clock_delete_less_trends)
或(partition_name〜'history_log_ \ d'和clock_max :: int <= clock_delete_less_strings)
或(partition_name〜'history_str_ \ d'和clock_max :: int <= clock_delete_less_strings)
或(partition_name〜'history_text_ \ d'和clock_max :: int <= clock_delete_less_strings)
然后
迭代器=迭代器+ 1;
引发通知'%',格式('!!! delete%s%s',partition_name,clock_max);
从pg_class中选择max(reltuples :: int),pg_size_pretty(sum(pg_relation_size(pg_class.oid)))作为“大小”,其中relname如partition_name || '%'转换为严格的buf_table_len,buf_table_size;
如果result_str!='',则result_str = result_str || ','; 如果结束
result_str = result_str || 格式('%s(dt <%s,len%s,%s)',partition_name,to_char(to_timestamp(clock_max :: int),'YYYY-MM-DD'),buf_table_len,buf_table_size);
执行格式(如果存在%s,则删除表,partition_name);
如果结束
结束循环
如果iterator = 0,则result_str = format(“没有分区可删除较旧的日期,则为%s日期”,to_char(to_timestamp(clock_delete_less),“ YYYY-MM-DD”));
否则result_str =格式(“已删除的%s个分区,以%s秒为单位:”,迭代器,截断(提取(从(clock_timestamp()-t_start)的秒数)::数字3)) result_str;
如果结束
-提高通知'%',result_str;
返回result_str;
当别人那么例外
获得堆叠的诊断信息err_detail = PG_EXCEPTION_CONTEXT;
返回格式('ups,出了点问题:%s [err code%s],%s',sqlerrm,sqlstate,err_detail);
结束
$功能$;
要自动调用自动清理分区功能,需要使用以下设置为“数据库监视器”类型的zabbix服务器主机创建一个数据项:
-类型:数据库监视器
-名称:delete_old_history_partitions
-键:db.odbc.select [delete_old_history_partitions,zabbix]
-sql表达式:选择delete_old_partitions(3,30,30);
#在这里,delete_old_partitions函数调用的参数以天为单位指示存储时间
#用于数字值,聚合数字值和字符串值
-数据类型:文本
-更新间隔:0
-用户间隔:计划为h2
-历史记录存储期:90天
-数据元素组:数据库
结果,我们将获得大约以下类型的分区清理统计信息:
2019-09-16 02:00:00,在0.024秒内删除了3个分区:trends_78(dt <2019-08-17,len 1,48 kB),history_193(dt <2019-09-13,len 85343,9448 kB ),history_uint_186(dt <2019-09-13,len 27969,3480 kB)
重要! 通过数据元素和用户功能设置分区自动删除后,您需要在管家Zabbix任务计划程序中关闭历史记录和趋势清除:
通过 zabbix
菜单项,从角落的列表中选择“管理”->“常规”->选择“清除历史记录”->禁用“历史记录”和“动态变化”部分中的所有复选框。 将历史记录表的索引类型更改为brin(时钟)和btree-gin(itemid)
特别感谢
erogov提供了
有关PostgreSQL索引的
出色的概述文章系列 。
甚至整个PostgresPRO团队。这些文章给我们留下了深刻的印象,我们在监视数据表上使用了不同类型的索引,并得出结论,哪些字段上的索引类型可以最大程度地提高性能。据观察,所有的默认表监测数据创建复合B树索引(为itemid,时钟) -它的快速查找,尤其是对于单调有序值,但在磁盘上很“膨胀”,当大量的数据- 1000万放在桌子上默认情况下,按小时汇总统计信息通常会创建一个唯一索引,尽管此处在应用程序服务器级别提供了这些用于数据存储和唯一性的表,并且唯一索引只会减慢数据插入的速度。在测试各种索引期间,发现了最成功的索引组合:所有监视数据表的时钟字段上的brin索引和itemid字段上的btree-gin索引。brin索引非常适合单调增加数据,例如事件事实的时间戳,即 用于时间序列。而且btree-gin索引本质上是标准数据类型上的gin索引,通常比经典btree索引要快得多,因为 在添加新值期间,不会重建gin索引,而仅对其进行补充。将btree-gin索引作为PostgreSQL的扩展。下面给出了此索引策略和默认情况下Zabbix数据库中索引的采样速度的比较。在负载测试期间,我们为三个分区累积了三天的数据:为了评估结果,执行了三种类型的查询:- 对于一个特定的参数itemid,最后一个月的数据,实际上是最近三天(总共1660条记录)
解释分析select * from history_uint其中itemid = 313300
和时钟> =提取(从'2019-03-09 00:00:00'的时间::时间戳)::整数
和时钟<=提取(来自'2019-04-09 12:00:00'的时间::时间戳):: int;
- 一天12个小时中的一个特定参数数据(总共649个条目)
解释分析select * from history_text其中itemid = 310650
和时钟> =提取(从'2019-04-09 00:00:00'的时间::时间戳):: int
和时钟<=提取(来自'2019-04-09 12:00:00'的时间::时间戳):: int;
- 一小时的一个特定参数数据(总共61条记录):
说明从history_text分析选择计数(*),其中itemid = 336540
和时钟> =提取(从'2019-04-08 11:00:00'开始的时间::时间戳)::整数
和时钟<=提取(来自'2019-04-08 12:00:00'的时间::时间戳):: int;
测试结果列表如下:*三个分区的总大小(以MB为单位)**类型1请求-3天的数据,类型2请求-12小时的数据,类型3请求-1小时的数据从比较表中可以看出,具有记录数的大型数据表超过1亿个数据清楚地表明,将标准复合索引btree更改为两个索引brin和btree-gin对减少索引的大小和加快查询执行时间具有有益的作用。下面以向history_uint和trends_uint表添加新记录的请求为例,显示了索引和分区的效率(每个查询平均添加2000个值)。总结zabbix系统监视数据表的各种索引配置的测试结果,可以说zabbix监视数据表的标准索引的类似变化会对整体系统性能产生积极影响,当累积的数据量超过1000万时,这种感觉最为明显。您应该忘记默认情况下标准btree索引“膨胀”的间接影响-频繁重建数千兆字节的索引会导致硬盘负担重(利用率)时间),这最终会增加磁盘操作时间和等待从CPU访问磁盘的时间(iowait指标)。但是 为了使btree-gin索引可以使用bigint(in8)数据类型(即itemid列),您需要为btree-gin索引注册bigint类型的运算符系列。为btree-gin索引注册一个bigint运算符族/ *
该脚本允许您在biginteger和integer数据类型上完全使用gin索引,而无需显式类型转换。
问题-杜松子酒指数缺少int2,int4,int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
该脚本将Zabbix的PostgreSQL数据库中的所有索引从默认配置重新分配到上述最佳配置。/*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
对于强度为每分钟100吨参数(历史上为100吨,历史上为100吨,history_uint)的数据量的brin索引,注意到该索引适用于主要监视数据表,其区域大小为512页,是两倍而不是标准页面大小为128页,但这是单独的,并取决于表的大小和服务器配置。无论如何,brin索引占用的空间很小,但是可以通过微调区域的大小来稍微提高它的速度,但是前提是数据流率没有太大变化。因此,值得注意的是,Zabbix本身的体系结构存在一个局限性:在“最近的数据”选项卡上,考虑到过滤条件,收集了每个参数的最后两个值。对于每个参数,分别在数据库中请求值。因此,选择的此类参数越多,查询将运行的时间越长。当在历史表上设置btree索引(itemid,clock desc)并按时间进行反向排序时,将搜索最新数据,但是索引本身当然会在磁盘上“膨胀”,并且通常间接地减慢数据库的速度,这会导致问题,如上所述。因此,有三种解决方法:- « » 100 (.. , « » )
- Zabbix , , « »
- 保留索引的默认设置,并限制我们仅对分区进行分配,以便同时获得各种参数的“最近数据”选项卡上的相当大的选择(但是,注意到Zabbix Web服务器仍然对同时显示的参数值的数量有所限制在“最近的数据”选项卡上-因此,当我尝试显示5000个值时,数据库计算了结果,但是服务器无法准备网页并显示大量数据。
查询执行统计信息pg_stat_statements的收集和分析
Pg_stat_statements是用于收集整个服务器上查询性能统计信息的扩展。该扩展的优点是它不需要收集和解析PostgreSQL日志。使用pg_stat_statements扩展psql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
要监视Zabbix中的硬盘驱动器,仅提供开箱即用的vfs.dev.read和vfs.dev.write参数。这些选项不提供有关磁盘利用率的信息。查找硬盘性能问题的有用标准是利用率,等待查询时间和磁盘负载队列负载。通常,高磁盘负载与cpu本身的高iowait以及与sql查询执行时间的增加相关,这是在具有标准配置的zabbix服务器的负载测试过程中发现的,该测试没有分区且没有设置替代索引。您可以使用以下步骤添加这些参数来监视硬盘驱动器,这些步骤在朋友的文章中有所介绍。lesovsky和改进的:现在,iostat参数是在json time参数中为每个磁盘分别收集的,根据后期处理设置,这些参数已被分解为最终的监视参数。在Pull请求待处理期间,您可以尝试通过我的fork根据详细说明扩展对磁盘参数的监视。在完成所有描述的步骤之后,您可以为系统磁盘和数据库磁盘(如果它们不同)向Zabbix主服务器监视面板添加带有iowait cpu和utiliztion参数的自定义图形。结果可能如下所示(sda是主磁盘,sdc是包含数据库的磁盘):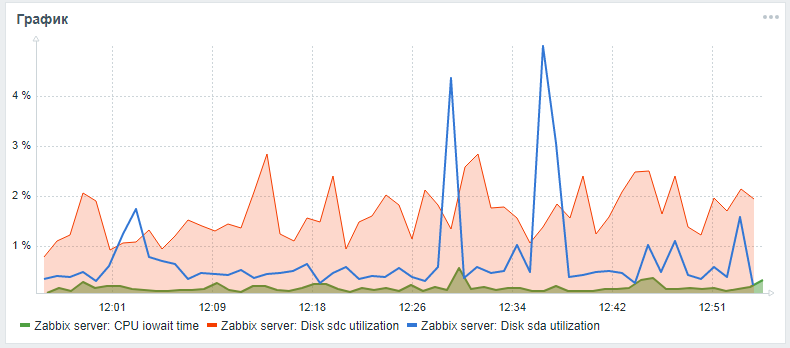
硬件性能提升
设置DBMS,建立索引和分区之后,您可以进行垂直扩展-改善服务器的硬件特性:添加RAM,将驱动器更改为固态并添加处理器核心。这样可以保证性能的提高,但是最好仅在软件优化后才能这样做。创建分布式集群
经过适当的垂直缩放后,您需要开始水平-创建分布式集群:分片或复制主从服务器。但这是单独文章的主题和材料(如何模制一堆狗屎和棍子),以及使用pg_pathman和使用TimescaleDB扩展方法建立索引的上述Zabbix数据库优化技术的比较。同时,只能希望本文中的内容实用且有益!